this guide is LARGELY OUTDATED (from October 2023)
and designed ONLY for running AI in Cloud, which is inferior to ANY other methods as of 2024+
if you are new to AI and want to chat with bots then start with this guide instead
guide below is designed for anons who want to try out local models on Google servers
running Locals via Colab + semi-general Locals guide
╔═══════════════════════ ⋆⋅✨⋅🎈⋅🍎⋅🌈⋅💎⋅🦋⋅⋆ ═══════════════════════╗
.don't know where to start?
- never heard about about GPTQ, GGUF, kobold.cpp and quantz? then check QRD on models
- want to learn about Mirostat, Typical P, Beam Search and other samplers? then check Knobs
- never touched Advanced Formatting before? then learn about presets
- have issues with Locals? then check troubleshooting
- otherwise, just grab Colab Notebook here, and up you go
- ...or just read everything
╚═══════════════════════ ⋆⋅🦋⋅💎⋅🌈⋅🍎⋅🎈⋅✨⋅⋆ ═══════════════════════╝
readme
what it is?
it a guide on running Locals via Google Colab + the settings + knobs + presets + troubleshooting + two pony-based LoRAs by anon from /ppp/ thread
context size?
for 13b Locals max context size is:
| format | max context size |
|---|---|
| GPTQ | 7168 |
| EXL2 < 4 bws | 7680 |
| EXL2 4-5 bws | 6144 |
| EXL2 5-6 bws | 4096 |
| GGUF / GGML Q4_K_M | 6144 |
| GGUF / GGML Q5_K_M | 4096 (5122 in llamacpp) |
| GGUF / GGML Q6_K | 4096 |
(response length better to set in ~300 range)
what model shall I use?
- generally, use GGUF Q6_K model if you need good responses with 4k context;
- otherwise use GGUF Q4_K_M model if you need 6k context but less quality
- if you need pony LoRAs then use GPTQ 4bit 32g
what is Google Colab? do I need a good PC for this?
Colab is Google's data servers. Google allows people to use them for free in non-commercial purposes (with an emphasis on research and learning). paid accounts may use Colab for various other purposes and have more performance/priority. you need an internet connection only: your PC/GPU/CPU/RAM don't matter. all computation is done solely on Colab servers
what is the catch?
Time limit. Google Colab applies a vague time limit, allowing only a certain number of hours per account. usually, you can use Google Colab for 2-3 hours per day, but it varies greatly due to unknown factors. one time it allowed me to sit for 7 hours, and another time it cut me short after 55 minutes
but they count only active usage time, right? if I launch their system and will not use the model then I don't use their resources, correct?
no. Google counts idle connection as a real one regardless of active usage. in simple terms: if you have connected to Google Colab and left your PC for four hours and literally did nothing - you will get 'daily limit is reached' nonetheless
what will happen after my time limit is up?
Google will cut off your access to their T4 GPU, and Locals do require GPU for work. you can still use Colab on CPU via kobold.cpp (see settings) but the generation will be extremely slow. your usage limit will recharged in 8-12 hours. there is no other limitations and anon who made a well-known rentry about Colab claims using it for Locals for months with no problems
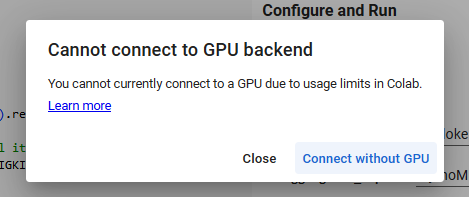
can I abuse it with multi-accounting? will Google Colab ban me for that?
yes, you can do multi-accounting and abuse their free limits, but it is highly recommended to use VPN + fake user-agent / incognito mode to protect yourself
NSFW?
yes. no strings attached. Locals are absolutely unfiltered so you can do whatever you want. mind that some Locals may have inner filters because they were trained on filtered materials (for example, none-finetuned Llama 2 is censored as well as Falcon 180b)
will Google ban me for NSFW?
Google will not ban your account for NSFW: but they can in theory throttle or rate limit accounts for suspicious usage; however I have yet to find real evidence of such practice. still don't push very questionable content on your primary gmail account too much
...but Google banned Pygmalion...
it was done in a different (much stupider) time, and it no longer applies. nowadays users can freely run Pygmalion 13B on Colab without negative consequences
...but Google banned A1111...
not banned but severely handicapped with throttling; because everyone uses it! Derpibooru alone has 10000+ AI pics and you can guess with high certainty that 80% of them were generated via Colab, and that number doesn't include 3.000.000+ bad pics that were discarded in the process. now apply those numbers to the whole internet, not 4chan only, and you get a picture. too much payload for Google (and people were abusing it much more than Pygmalion)
troubleshooting
Local generates garbage and noise
- significantly
reduce the max context(by 2k - 4k) and try again. it might be an overflow issue. if you start receiving coherent responses on low context then return back to the current max context and reduce it by 512 until the responses became meaningful - set the following
samplersto default values (if they are available): Mirostat (0/0/0), Penalty Alpha (0), Encoder Rep. Pen. (1), Beam search (1), CFG Scale / Negative Prompt (1) - ensure that
Ban EOS Tokenis OFF - ensure that
Instruct Modeis ON - change
presets(Alpaca / Vicuna 1.1 / Llama 2 Chat are the most common ones, but try them all) - enable/disable
streaming
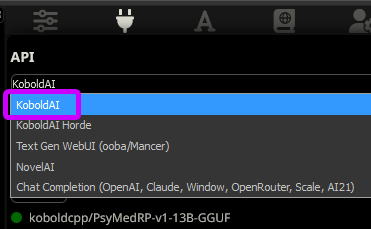
kobold.cpp generates only 49-50-51 tokens
in SillyTavern you are launching kobold.cpp as oobabooga. pick koboldAI instead:
Local generates blank messages or stuck
it is an issues on SillyTavern/Agnai <-> Cloudflare <-> Colab part, not a skill issue. sometimes your response get stuck
first, enable streaming since it helps to see generation in real time
second, if message generation doesn't start in 10-15 seconds then you can safely discard/pause current message and send a new one. just click on pause button

is that me or models loses intelligence when it gets to the end of its context?
no, that's how ALL models work (including GPT4 and Claude). it becomes even more apparent upon utilizing alpha_value (NTK RoPE) that scales models's context at values higher than original max context. to compensate the scaling model starts losing some tokens in the prompt - it is unavoidable unless more VRAM will be offloaded (which big corpos may afford but not you)
I got "RuntimeError: Found no NVIDIA driver on your system. Please check that you have an NVIDIA GPU and installed a driver" error on Colab
you didn't select T4 GPU in Hardware accelerator in Colab. or your daily limit is run out and you are now trying to connect via CPU, in that case wait for 8-12 hours before trying again
it says got "You are running ExLlamaV2 without flash-attention. This will cause the VRAM usage to be a lot higher than it could be."
yes, don't mind that error. if you install flash-attention in Colab then EXL2 will not work at all (shitty Colab GPU)
QRD on models
Locals work the following way
first you have a basic (aka foundation, pretuned) model - which is a model trained on optimized dataset. the most known foundation model - Llama, made by Meta; other examples - Falcon, Mistral, GPT-2/J, MPT...
those fundamental models can additionally be further trained on extra dataset (text files) to steer them into certain direction: write fiction, RP, doing science work, helping with coding, giving medical advice, being NSFW writers... those models are named finetuned or instruction-tuned (depending on the process): Pygmalion, Vicuna, Pythia, Wizard, Hermes, Beluga, etc if you see L or L2 label in the model's name then it means the model derived/based on Llama (1/2)
those finetuned models can be merged together in a pretty much any combination, for example a well-known Mythomax is a merge of:
- Hermes + Chronos + Airoboros = Mythologic
- Hermes + Chronos + Airoboros + Beluga + LimaRP = Huginn
- MythoLogic + Huginn = Mythomax
yes, it is not a typo - three models: Hermes, Chronos and Airoboros - were merged twice in process, only in different ratios.
if you ever wondered why Locals are so retarded, well they have lots of inbreeding
model' most define distinction is parameter (or as faggots say - beaks). the most common models' beaks are 7b, 13b, 20b, 33b, 65b and 70b, but models may be having any value in between
in general, parameter means the general intelligence of model: more the beaks more the smarts
but it is not always the case: some 7b models (Mistral) may perform better than some 13b, while some 20b may be as dumb as 7b. furthermore community always gets new tools, technologies and ideas that further boost the distinctions: for example, 13b models from early April of 2023 are much-much dumber than 13b models from September of 2023. you have to lurk and ask around which Locals are recurrently considered the best, because the meta changes every ~2-3 weeks upon the new milestone achieved
all those models requires A LOT of VRAM/RAM to load them; in order to reduce the specs - the models are compressed in the different formats. compression reduces the overall model size but hurts intelligence because some data becomes non-retrievable. four most popular compressions are GGUF, GGML, GPTQ and EXL2
GGUF - the format that values compression in Quant (Q); with Q2_K being the most retarded version but takes the least amount of VRAM/RAM to load, while Q8_0 offers the less compression rate but offers the best, almost lossless, quality. for Colab you shall use:
| GGUF quantz | vram usage | quality | context in Colab via kobold.cpp | ...via llama.cpp |
|---|---|---|---|---|
| Q4_K_M | low | average | 6144 | 6144 |
| Q5_K_M | average | good | 4096 | 5122 |
| Q6_K | high | best | 4096 | 4096 |
--use Q4_K_M if you value context size and Q6_K if you want quality the most
GGML - the same as GGUF above and outdated now. use GGUF models instead
GPTQ - the format that values compression in Bits (b) and Group Order (g). more the bits and less group order - better quality. for the purpose of Colab look for 4bit / 32g models: they can be load in Colab in 7168 context. in terms of intelligence, it stays at about Q4_K_M level
EXL2 - the new format that will replace GPTQ in future but for now its support is still low. in allows to create models of mixed number of bits - bws. GPTQ allowed to create only 4-bit and 8-bit models, while EXL2 can be anything in between and offers better compression. for the Colab look for models with 4-5-6 bws
models of various formats, datasets to train them with, all benchamarks are hosted on huggingface.co --all Locals can be found there
to launch all those formats we use different programs called either backend or loaders:
- GPTQ - exllama
- EXL2 - exllama2
- GGUF - kobold.cpp or llama.cpp
- GGML - kobold.cpp
exllama, exllamav2 and llama.cpp are combined together into one backend called oobabooga (if you ever did SD and heard about A1111 - then it is the same kind of all-in-one package), while kobold.cpp is a standalone program originated from llama.cpp but became its own thing
if you don't know which model to start with, then start with Q4_K_M GGUF models with 6k context. you can search huggingface/models for catalog of various models. if you want to apply LoRAs (see below) then look for GPTQ 4bit / 32g models in huggingface/models
if you absolutely don't know what model to pick then check huggingface's leaderboard and /lmg/'s ayumi leaderboard (which measures only the amount of used lewd words, not an actual coherence)
some good options to start with:
--> MythoMax 13B
MythoMax is a little 13B full of big sovl. maybe not as smart or as lewd, but produces surprisingly poetic and rich descriptions for 13b. Mythomax is considered a golden standard of all-around models: a well-around working pony horse
--> MLewdBoros 13B
MLewdBoros is the merge between Mlewd, the extremely lewd model - and Spicyboros, the another horny model. result is, you guess it - lewd and horny model
--> Amethyst 13B
Amethyst is my personal favorite 13b merge so far. as usual Undi95 threw some random stuff into one merge and that somehow clicked: both RP and storywriting. don't question my personal autism
Notebook
--> #1.
download Notebook (all credits in the notebook)
previous versions (not needed, just for history): [07_13], [old]
--> #2. proceed to Google Colab (requires gmail account)
--> #3. File -> Open notebook -> Upload -> Select notebook
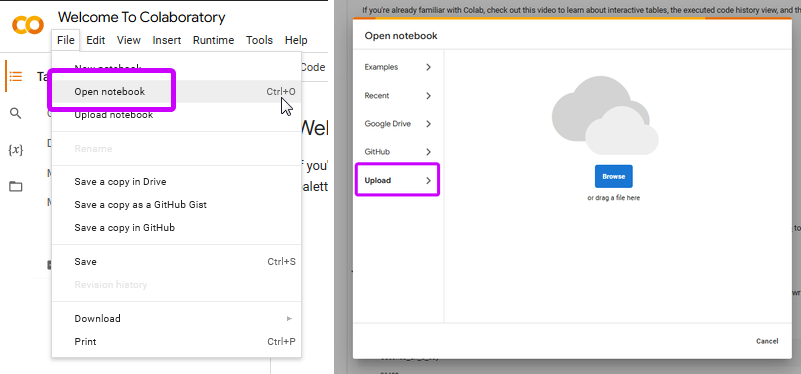
if you cannot find File then click on the gray arrow in top-right corner:
--> #4. you will be redirected to that page. those are the settings:
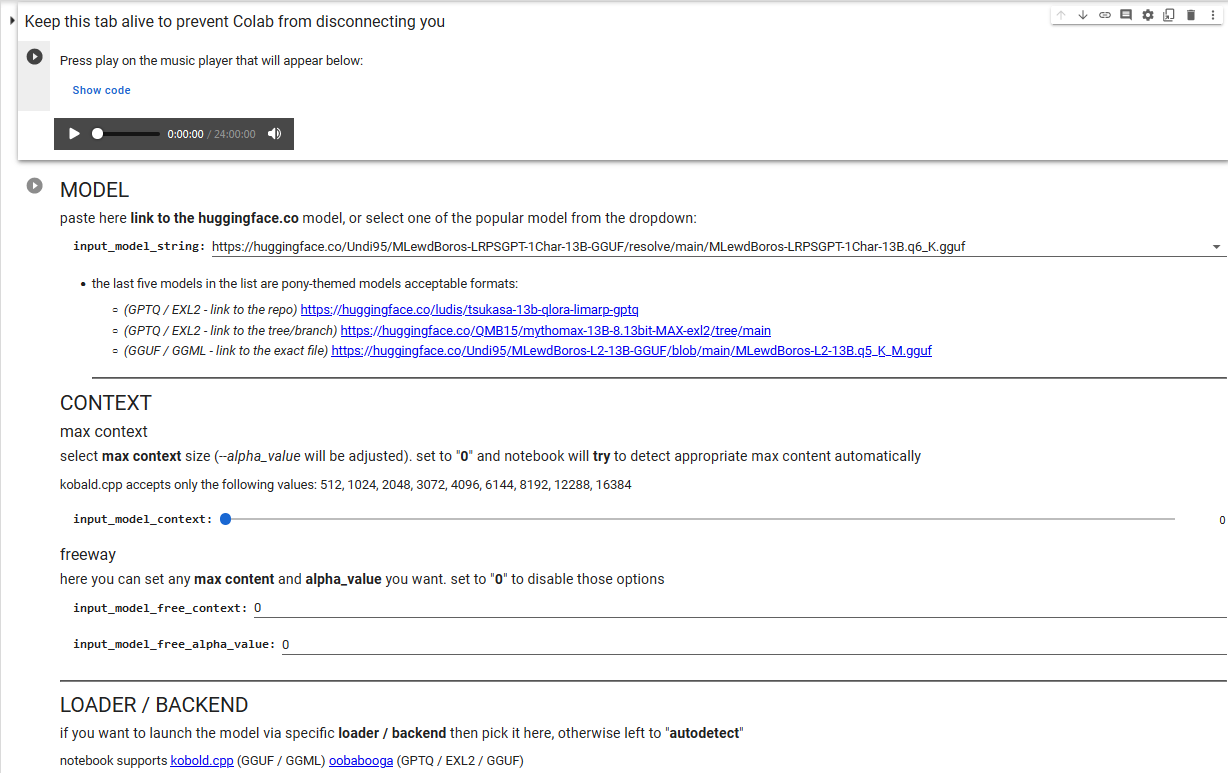
if you cannot see the settings then click there:
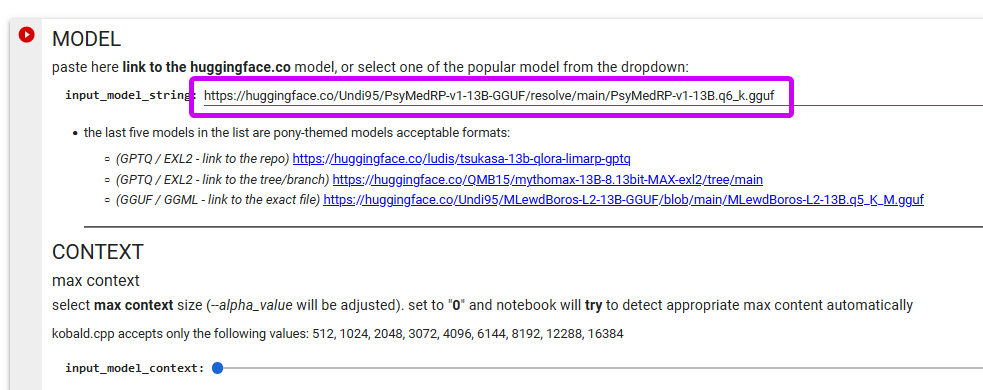
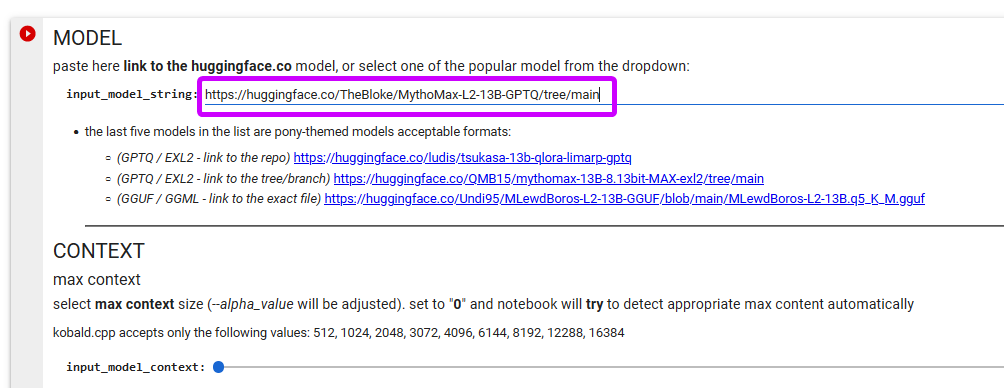
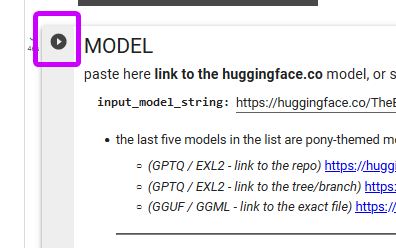
--> #5. everything is already set to the best options the only thing you have to do - is provide the link to the Locals you would like to use
(the first input field - input_model_string)
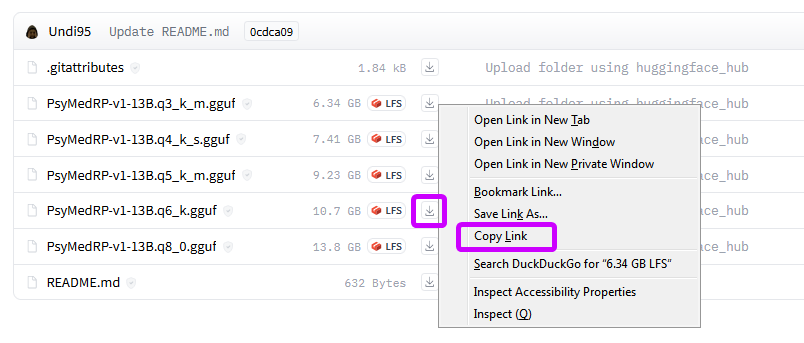
for GGUF / GGML models:
copy-paste the link to the exact file you want to download. for example if you want to use GGUF 6Q version of PsyMedRP then visit its page on huggingface and copy-paste the link:
FOR GPTQ / EXL2 models:
copy-paste the link to the whole repo you want to download. for example if you want to use GPTQ version of MythoMax then visit its page on huggingface and copy-paste the link:
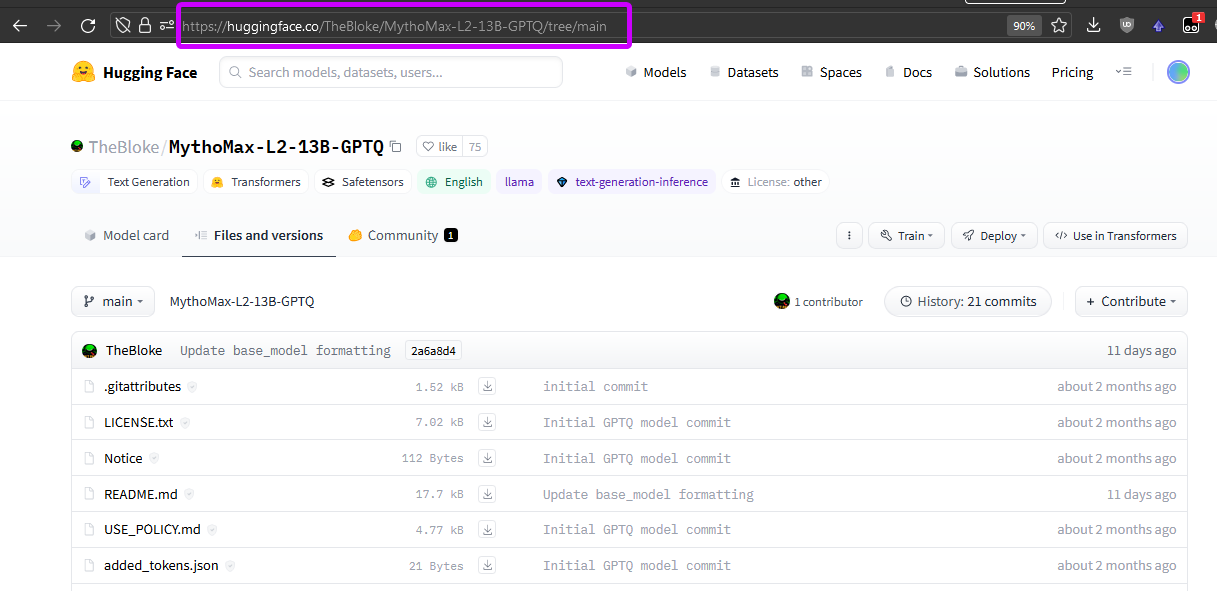
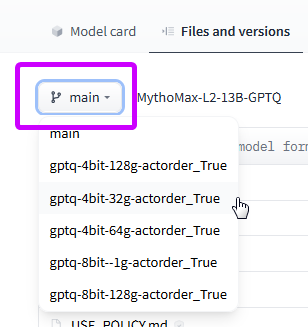
different GPTQ versions are usually uploaded as different tree branches. select them from the dropdown
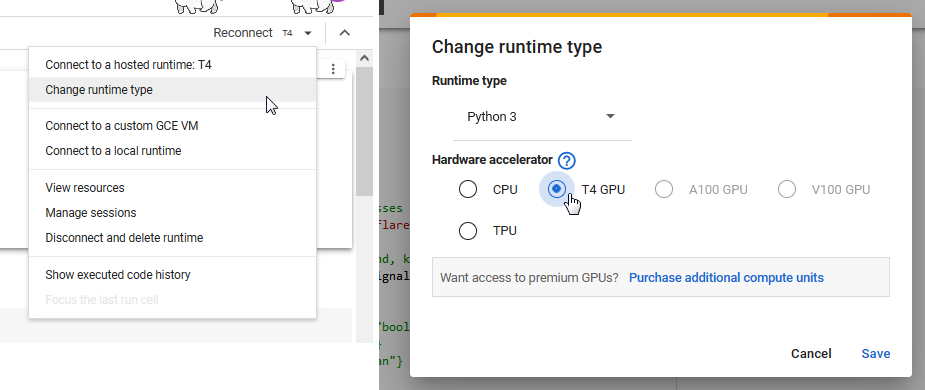
--> #6. in top-right corner look for reconnect link, next to it an arrow-down -> Change runtime type -> Hardware accelerator -> T4 GPU
--> #7. press on the first PLAY button to enable music player. it is a 24h silent soundfile to keep the tab busy and prevent its hibernation (and issues with Colab)
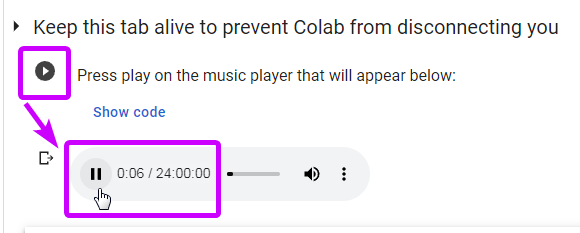
--> #8. press on the second PLAY button and wait.
--> #9. now you need to link Colab to your SillyTavern or Agnai
for GGUF / GGML models:
when notebook asks you to connect to http://localhost:5001...
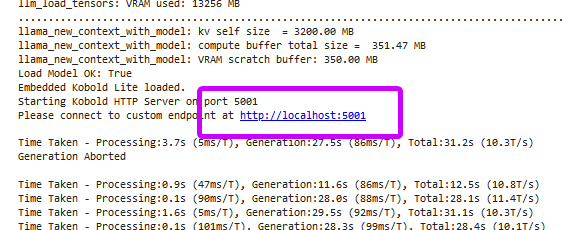
...scroll up until you see a Your quick Tunnel has been created link. copy it
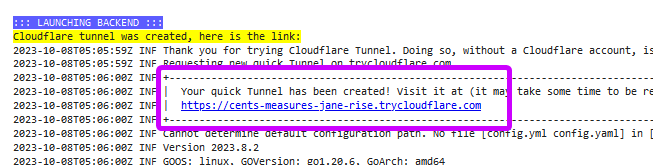
in SillyTavern select KoboldAI as API and paste the generated link, afterwards click connect, ensure that the name of Model appeared below... and chat with AI Mares
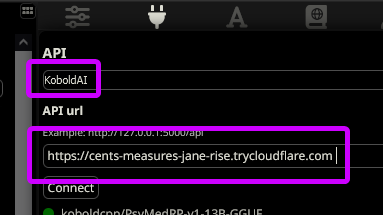
in Agnai create the following preset:
- select
AI Service->Kobold / 3rd party->Kobold Third Party URL-> your link from Colab WITHOUTAPIAT THE ENDDisable Auto-URL: OFF (gray)
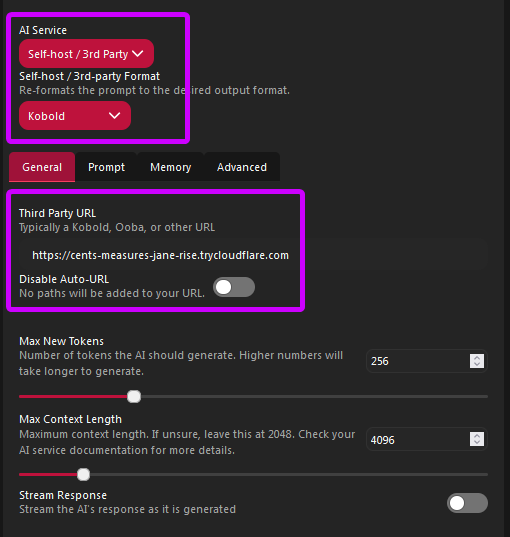
for GPTQ / EXL2 models:
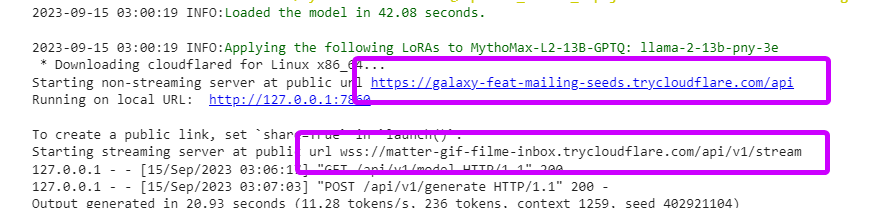
you will get two links that look like this:
https://****************.trycloudflare.com/api
-- main linkwss://****************.trycloudflare.com/api/v1/stream
-- streaming link (if you need streaming, optional)
howto_notebook_link.png
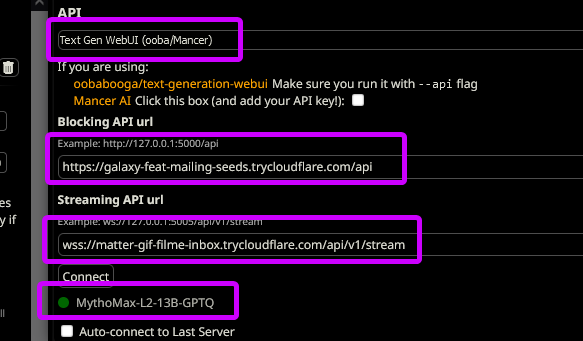
in SillyTavern select Text Gen WebUI (ooba/Mancer) as API and then paste both links:
- main link goes into
Blocking API url - streaming link goes into
Streaming API url(if you need streaming, optional)
--after that clickconnect, ensure that the name of Model appeared below... and chat with AI Mares
in Agnai create the following preset:
- select
AI Service->Kobold / 3rd party->Textgen (Ooba) Third Party URL-> your link from Colab WITHOUTAPIAT THE ENDDisable Auto-URL: OFF (gray)
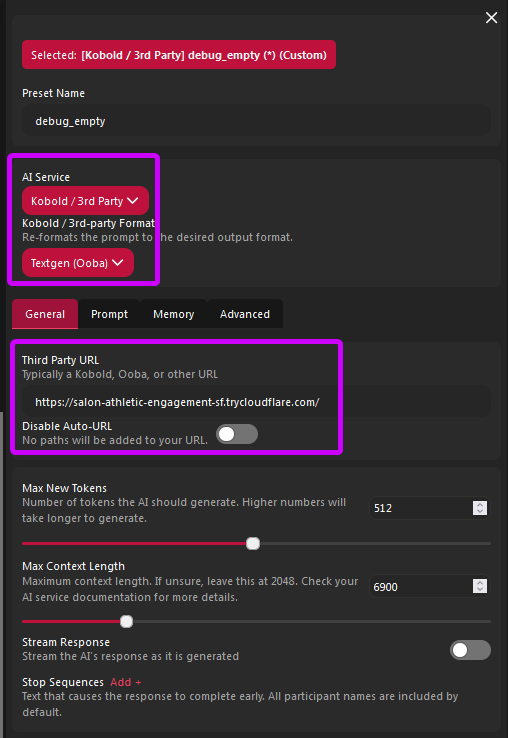
--> #10. if you didn't do it already then setup Advanced Formatting and Samplers
don't close the tab with Colab, left it open.
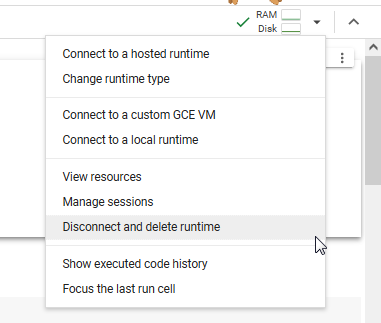
--> #11. when you done chatting. in top-right corner look for reconnect link, next to it an arrow-down -> Disconnect and delete runtime
LoRAs
LoRA is a subset of data containing examples, text, weight, lore, training corpus and extra details. they can be served as the plugins to directly incorporate into a model, or serve as extra knowledge cutoff
that Notebook supports two pony-related LoRAs that can be applied to any GPTQ model. LoRAs are created by anon in /ppp/ thread
- FIMFarchive-v1 - dataset of fanfics from FIMfiction archive
- desu-/mlp/-v1 - dataset of /mlp/ posts, including greentext
those pony LoRAs can be applied to GPTQ models only
for LoRAs to work correctly set preset to Pygmallion, Metharme, Vicuna 1.0 or WizardLM-13B. other presets may work better/worse depending on the model, so it is a but of trial-n-error
those two LoRAs improve models' awareness about MLP and help with lingo and names. reasoning itself is unaffected so don't expect models to become much smarter, but they will be able, for example, to deduce that Element of Honesty is Applejack (with certain probability). on pic below you can see the effect of applied FIMFarchive-v1 LoRA (before/after):
(Scootaloo is RD's adoptive daughter is too cute, I don't care)
the negative consequence of LoRAs is spurting random data from dataset (noise tokens), which can be mitigated with lower temperature or more aggressive sampling. just cut them off. in my test they mostly proc on the low context prompt until the model get enough tokens to works with
...however some of those OOC are funny and I don't mind their occasional appearance :
below are pictures for comparisons, done on basic Athena model, then with two different LoRAs applied, and forth column for MythoMax model for extras:
| Athena model | Athena + desu-/mlp/-v1 | Athena + FIMFarchive-v1 | MythoMa model + FIMFarchive-v1 |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Advanced Formatting
Preset/Format
to use Local models properly you need to set correct options for them
open Advanced Formatting tab in SillyTavern and check presets. here change between various presets: Alpaca, Vicuna, Llama 2 Chat... to change how Local will process your prompt:
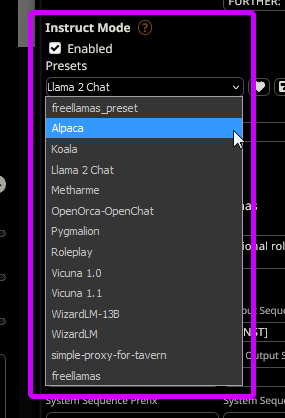
how to know which preset/format is correct? visit model page. usually author posts which format the model has been trained on:
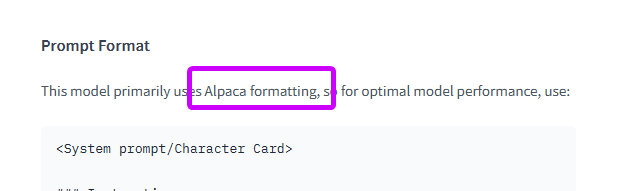
you don't need to tweak anything else here by default - settings correct preset is enough in the most cases; but if you want the more control over the text generation, and know what all those settings mean, then read further:
Story String
it acts as your MAIN and templates formatting (Agnai users will find it very familiar)
the absolute minimalist, super default, Story String looks like this. it basically goes: if there is system info then output it, if there is description info then output it, etc...
| option | description |
|---|---|
system |
content of system prompt (read below) |
wiBefore |
content of World Info / LoreBook if you set to insert it BEFORE character's card |
wiAfter |
content of World Info / LoreBook if you set to insert it AFTER character's card |
description |
content of character's card (defs) |
personality |
content of character's Personality summary (from Advanced Definition) |
scenario |
content of character's Scenario (from Advanced Definition) |
persona |
content of user's Persona Description (from Persona Management) |
you can move those templates any way you like and it may affect the generation. for example (using scenario as main while system will be used as mid-JB):
...furthermore you can add extra data to (hopefully) aid AI:
...in addition you can manually add your instructions here; some people recommend add ### Input: at the start which supposedly helps AI --but can be a snake oil. for example:
for Agnai use the following settings:
Use Prompt Template: ON (red)Prompt Template(source):
System Prompt
System Prompt will be inserted in place of {{system}} template in Story String. you may utilize it as MAIN that will go first before anything else:
Story String(start):
System Prompt:
...or use at the end of Story String and utilize as a pseudo AN with extra instructions:
Story String(end):
System Prompt:
--whatever approach to use depends on your personal preference, current RP and the current model
Example Separator and Chat Start
Example Separatoris added before every providedDialogue ExamplesChat Startis added before the actualChatstarted (after all the examples)
...those two commands aim to help AI into difference what it the part of actual narrative and what serves as an example
a typical guideline is to use the following separators:
I personally like the following approach - to announce that all examples are done and now we proceed to the roleplay itself:
Instruct mode and Sequences
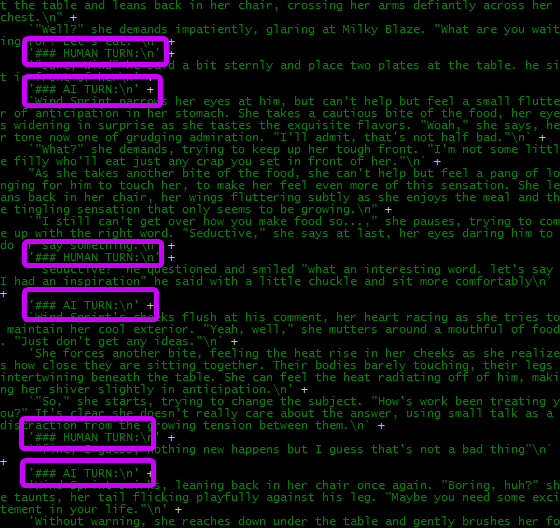
Instruct mode allows model to create text based on your prompt, which is exactly what you want in RP
if you disable Instruct mode then AI instead will try to CONTINUE the current prompt, see pic below
in most cases Instruct mode shall be ON unless you have a reason to ask AI to continue the text instead of completing it. seems like writing greentext is a legit case where Instruct mode shall be OFF but it depends on how you use Locals
Input Sequenceis added before every User's response (in chat history)Output Sequenceis added before every AI's response (in chat history)
...those two commands aim to help AI into difference the roles in the story
a typical guideline is to use the following sequences:
...but you can use whatever format you want and maybe model will click better for you, some examples:
First Output Sequenceis added before very first AI's responseLast Output Sequenceis added before very last AI's response
...usually you don't need to touch First Output Sequence but for Last Output Sequence you can add an extra instructions just before prompt generation, for example:
...of course you can go completely overboard and do stuff like this, and consider it to be a mini-JB:
System Sequence Prefixis added before the whole promptSystem Sequence Suffixis added after the whole prompt
the point of those sequences is to compel to quirky formats of certain Models. you most likely don't need to touch them on your own
Stop Sequence, EOS, Custom Stopping Strings
Stop Sequence is a special symbol commanding Local to stop the generation. upon reaching that token Local will stop producing more content until the next prompt is issued. it acts as a stop-signal both for Local itself and for SillyTavern/Agnai so they would not expect any tokens afterwards (which is especially useful in streaming)
the most common Stop Sequence is </s> - unless Local was trained to use something different
via Custom Stopping Strings (on the right) you may include more tokens and word combinations that will stop the generation. the difference is that Stop Sequence is a special indicator produced by Local itself to stop the generation, while Custom Stopping String can be pretty much any string, word, letter, sign, which can be part of original generation. for example you may include here the word "ministration" and Locals will stop the generation when that word appear in text
for Custom Stopping Strings you must utilize JSON format, example:
that combination willl force Local to stop generation when a newline starts with the word "Instruction" or tags </stream>, </endfic> or </startfic> are used
if you want to disable any stop sequences then look to Ban EOS option (EOS stands for "End of Stream"): it will force Local to generate tokens further despite Stop Sequence. be warned that model will go schizo very fast

Tokenizer and padding
Set Tokenizer to Sentencepiece (LLaMA)
proper Tokenizer is required for the correct token for Response Length (tokens) and Context Size (tokens) correctly. Sentencepiece works with all Locals
padding is a "token reserve" to avoid overflow. with lower values AI will try to output as many tokens without considering an actual length of prompt, with higher values AI will lookahead and finish its prompt prematurely before it overflow the completion
usually setting padding to 64 or 96 is enough
Wrap Sequences with Newline
that option adds the newlines before sequences. without it they will append on the same lines. good for content clarity
Replace Macro in Sequences
Replace Macro in Custom Stopping Strings
"macro" are various entries inside curly brackets {{}} that automatically transformed into the proper words; for example {{char}} stands for "card's name" and {{user}} stands for "user's persona". if you disable them then instead of names the actual words {{char}} and {{user}} will be used
Include Names + Force for Groups and Personas
that option appends names (both {{user}} and {{char}}) into prompt. it is great thing for RP since it helps AI to follow the roles better, but if you are doing a story-writing hen you probably better to turn them off. some models may confuse the roles and enabling/disabling Names may help those models to get the better context
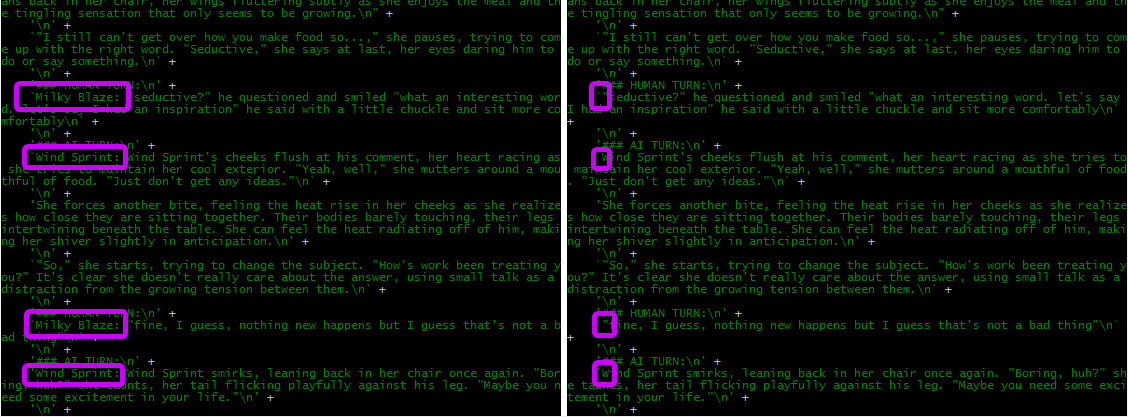
Knobs
tldr
don't want to read all that stuff and just need settings copy-paste?
- freellamas
- tsukasa13b
- my preset below
- @todo: need more
Big Models support mostly Temperature, Top_P, Top_K -and in case of GPT4 - penalties
Locals, in other hand, support much more knobs and offer a huge assortment of options which can make your head dizzy, but things ain't hard
ENABLE DO SAMPLING IN OPTIONS
otherwise most of those settings will not work you
my preset
those are my settings I am using for the most models. not necessary saying those are the best settings --but that is what I have settled with
Temperature must be changed according to the model
some Locals perform better on lower Temperature, while other require higher Temperature. Mythomax, for example, benefits from Temperature in 0.6-0.8 range, while higher ones turning it into schizo
| sampler | Default | More Stable | More Creative | Mirostat Default | Mirostat Creative | Mirostat Schizo |
|---|---|---|---|---|---|---|
| Temperature | 1.05 | 0.84 | 1.25 | 0.84 | 0.95 | 1.40 |
| Repetition Penalty | 1.06 | 1.11 | 1.15 | 1.06 | 1.05 | 1.03 |
| Repetition Penalty Range | 1320 | 1320 | 1320 | 1320 | 1320 | 1320 |
| Rep. Pen. Slope | 0.8 | 0.9 | 0.8 | 0.8 | 0.8 | 0.8 |
| Encoder Repetition Penalty | 1.01 | 1.01 | 0.99 | 1.02 | 1.02 | 1.03 |
| No Repeat Ngram Size | 0 | 0 | 0 | 0 | 0 | 0 |
| Top K | 0 | 0 | 0 | 0 | 0 | 0 |
| Top P / Nucleus | 0.90 | 0.80 | 0 | 0 | 0 | 0 |
| Typical P / Typical Sampling | 0.9 | 0.9 | 0.95 | 1 | 1 | 1 |
| Top A | 0 | 0.1 | 0.1 | 0 | 0 | 0 |
| TFC / Tail Free Sampling | 0.94 | 0.92 | 0.94 | 1 | 1 | 1 |
| Epsilon Cutoff | 0 | 0 | 0 | 0 | 0 | 0 |
| Eta Cutoff | 0 | 0 | 0 | 0 | 0 | 0 |
| Number of Beams | 1 | 1 | 1 | 1 | 1 | 1 |
| Length Penalty | 1 | 1 | 1 | 1 | 1 | 1 |
| Penalty Alpha | 0 | 0 | 0 | 0 | 0 | 0 |
| Mirostat Mode | 0 | 0 | 0 | 2 | 2 | 2 |
| Mirostat Tau | 0 | 0 | 0 | 4.0 | 3.5 | 5.0 |
| Mirostat Eta | 0 | 0 | 0 | 0.15 | 0.20 | 0.30 |
presets
SillyTavern offers prebuilt presets you may load and use without figuring what all those knobs do.
one anon made a good rounddown of most presets. my imho - for Mythomax the best presets are:
- Titanic
- Space Alien
- Naive
- TFS-with-Top-A
- Midnight Enigma
Temperature (temp)
your absolute basic knob. it determinate the pool of tokens (words), and their overall number:
higher: more tokens in the pool, more random tokenslower: less tokens in the pool, more predictable tokensdisable: 1 (default)
at value temp: 0 AI becomes 100% deterministic and always outputs the same text regardless of the seed or swipe
there are two main approaches:
- set temp at high value (1.4+) and then use other knobs generously to trim unnecessary tokens
- set temp at low value (0.6+) and then use other knobs sparingly to avoid trimming good tokens
overall, a safe temp value is in the 0.8-1.2 range, depending on how much creativity you need. if you are going with high temp then you need to counter-balance it with other sampling methods below
Top P & Top K
Temp's two younger sisters that always follow her around
Top P (aka "nucleus sampling") sets the range of tokens to be applied into the pool. it sums the probability of tokens until it reaches the point when the total sum of picked tokens exceeds the given range - then discards all leftover tokens. so it leaves only the tokens (the mass) of highly probable tokens
higher: more random tokens (less sampling effect)lower: more predictable tokens (more sampling effect)disable: 1
Top K is dumbed-down Top P. instead of actually calculating the sum of tokens' probability - it just picks the given number of tokens in a row and cuts everything else. in nutshell it limits the total range of pool to that many tokens
number: allow that many tokens into selectiondisable: 0
if you set Top K: 1 (only 1 most likely token to pick from) --then AI becomes fully deterministic because you effectively cut the whole pool to 1 most-likely token which always will be the same
neither of Top P and Top K is ideal because Top P tends to put random tokens into pool, while Top K cuts quite likely tokens. pic below explains the shortsights of both samplings. Top A below combines both their methods and 'patches' their issue
however, it might be a good idea to set Top K to some high value (50-80) to cut unnecessary tokens firsthoof, and allow other samplings to work with more relevant data

Top A
Top A uses the mass of the most likely token (the most probable) and verifies other tokens based on it. so instead of using some arbitrary sums - it uses the chance of the most likely token to cut the pool. due to its design it is very aggressive and can lead to dry results even on high settings
higher: more predictable tokens (more sampling effect)lower: more random tokens (less sampling effect)disable: 0
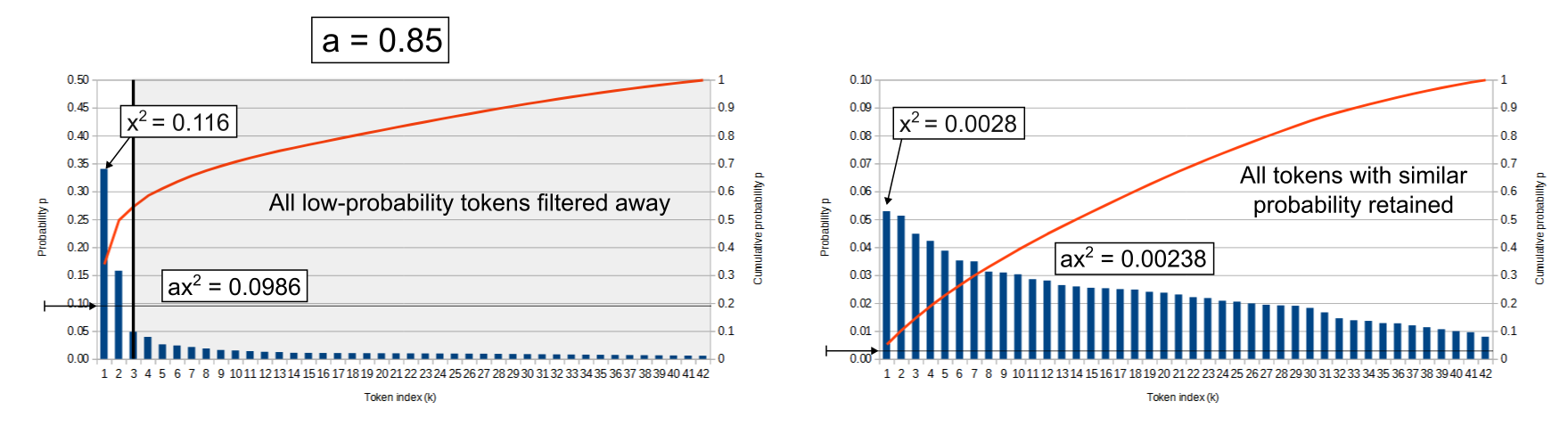
Typical P
Typical P (aka 'locally typical sampling') is unorthodox knob. it uses an entropy value to cut both tokens with too low probability and too high probability. it uses an idea that natural human speech uses median words, where every token has about the same probability as the previous one (aka, uses tropes and cliches). the value of that sampling method determines how strong the entropy to look for. while it is very good for summarization and providing facts - the usage in RP or storywriting can cause more harm than good
higher: more random tokens (less sampling effect)lower: more predictable tokens (more sampling effect)disable: 1
Tail Free Sampling
Tail Free Sampling (TFS) is extremely complicated sampling method based on the differences between the tokens' probability. in the first round TFS calculates the difference between tokens' probability and normalizes them to median (calculates the median of all differences). in the second round it cuts off the tokens behind the threshold. the common idea is to not set it too low unless user needs deterministic text
higher: more random tokens (less sampling effect)lower: more predictable tokens (more sampling effect)disable: 1
Epsilon Cutoff & Eta Cutoff
are basically the same thing as Tail Free Sampling but separated in two different values. see how in TFS the two rounds were mentioned? Epsilon Cutoff determines how aggressive the normalization across the board will be, while Eta Cutoff sets the threshold of tokens to cut
higher: more predictable tokens (more sampling effect)lower: more random tokens (less sampling effect)disable: 0
Repetition Penalty
Repetition Penalty reduces the appearance of tokens that are already present in the text. if user already has the word 'ministration' in the prompt (20 sentences ago) then this knob will check whether another appearance of 'ministration' is allowed. while it sounds as a nice feature, too high value will lead to unnatural text full of synonyms and simile
higher: less word repetition allowedlower: more word repetition alloweddisable: 1
Repetition Penalty Range
Repetition Penalty Range tells how far back AI shall look for the repetitive words (in tokens)
number: take that many tokens into consideration when determinate repetitionsdisable: 0 (all prompt)
Rep. Pen. Slope
Rep. Pen. Slope determines how aggressive anti-repetition measures must be closer to the end of chat. if you set that value low then Ai will allow some repetition to slip-in, setting it too high prevent AI from using the same words at the end of chat. you must use Repetition Penalty Range for Rep. Pen. Slope to work
higher: less word repetition allowed at the end of chatlower: more word repetition allowed at the end of chatdisable: 0
No Repeat Ngram Size
Ngram is sorta plugin for repetition detection and sets the number of tokens in a row to check for the repetition. for example the phrase 'the night is still young' is 6 tokens long. if you set this knob to '6' then AI will prevent the generation of that phrase in text (based on Repetition Penalty's aggressiveness), but setting it to '5' will allow that phrase to generate further. while useful, again, too lower value will make the text incomprehensible
number: check for that many tokens in a row for repetitiondisable: 0
Encoder Rep. Pen.
Encoder Repetition Penalty is a special knob that tries to fight with an issue of text becoming incomprehensible with other repetition penalties. it takes into account the context and allows some tokens that would have been otherwise banned to slip it. in other words, that option prevents tokens from being banned under regular circumstances if it will improve text legibility
higher: more token repetitionlower: less token repetition (set to 0.8 and have a laugh)disable: 1
Negative Prompt & CFG Scale
Negative prompts & CFG doubles the usage of VRAM, effectively cutting your max context in half
Negative prompt tells AI what TO NOT generate. you can do lots of things there:
- give a general direction of what you don't want to see (per @ada1's preset):
- tell AI what it shall not to do:
- provide the text with bad grammar and bad sentence structure (source):
CFG Scale affects how powerful the negative prompt must be:
higher: stay away from negative prompt as much as possiblelower: embrace and apply negative prompt into generationdisable: 1
"why in the name of the Celestia's second horn anyone wants to apply a negative prompt?", you may ask. the answer is simple - you can provide a (literally) random text into that field and set AI to apply it, then it will act as a second-hand randomizer/seed, (source) - which is a damn good hack
Beam search
Beams don't work in free Google Colab because of insufficient VRAM
Beams allow AI to predict multiple sentence generation and then pick the one generation that offers the best token probabilities. it results in generating more organic text, but uses a huge amount of VRAM. ironically but AI can generate much worse text in return because it will look for more organic text rather than the more creative and avoid unsure tokens
Number of Beams tells how many different variants to generate in total, while Length Penalty determines the length of each generation
Penalty Alpha
Penalty Alpha flipflops the whole sampling system and adds a natural degeneration into the range allowing some level of mistake into the range. now all sampling methods will allow a margin of error to (supposedly) make generation more natural, creative, random and unpredictable
higher: bigger margin of error, less predictable textlower: smaller margin of error, more predictable textdisable: 0
Mirostat
infamous Mirostat. in nutshell, very-simple, it is an auto-pilot mode that controls the sampling and adapts the generation based on the currently picked token buffed by randomness factor. some people enjoy it because it is a simple plug-n-play knob that does most of the work by itself, while other dislike it because of randomness in generation
the basic idea behind of Mirostat goes like this. your usual token prediction and selection work as usual but Mirostat checks what token was picked:
- if AI picked the token with high probability then Mirostat slightly boosts the chance of all other tokens via samplers in the next selection
- if AI picked the token with low probability then Mirostat slightly lowers the chance of other tokens via samplers, but leave the most-likely token intact in next selection, allowing AI to pick the token with higher chance next time
Mirostat takes control of samples
Top P, Top K, Typical P, Top A, Tail Free Sampling, Epsilon Cutoff & Eta Cutoff --will not work when Mirostat is on. Temperature and penalties work
Mirostat always adapts the token chance trying to balance between selecting random and predictable tokens. you can say that Mirostat works like the swing, picking between the tokens of both good and bad, and plays a devil's advocate in between
Mirostat Eta (learning rate) sets the overall aggressiveness of Mirostat, how much it will affect the tokens and how often it will affect the generation
higher: more random tokenslower: more predictable tokensdisable: 0
Mirostat Tau sets the amplitude that Mirostat will uses on tokens with each generation (changing their chance)
higher: more random tokenslower: more predictable tokensdisable: 0
Mirostat Mode sets what version of Mirostat to use:
0: disable1: mode for llama.cpp2: mode for exllama_hf (Colab notebook works on that)
setting the correct value for Mirostat is not easy and depends on the model and other sampling methods. some good variations from the anons in /lmg/:
credits, backlinks & shoutout
- colabfreellamas
- authors of two Colab notebooks: one & two
- author of two pony LoRAs and pony-related Colab notebook
- author of two pony-trained LLaMA 2 13B models: LL2-13B-DesuMLP-QLORA-GGML & LL2-13B-FIMFiction-QLORA-GGML
- author of pony-related corpus data
- ada1's preset
- Kalomaze for GGUF colab and for the numerous tests and reports
- Undi95 for non-stop merges and especially for Amethyst
- freellamas
- llm-settings
- hostfreellamas
- primeanon
- darkstardestinations
- ask-max