Как экономить токены и на.. зачем это надо. Версия 1.1
Варнинг: автор лох, и сам ничего толком не знает. То, чем автор делится, было замечено им лично или подсмотрено у других. А еще автор крайне хреново шутит.
 "Девушка и китик" 495х600px, Автор: RTX 4070, 2025 г.
"Девушка и китик" 495х600px, Автор: RTX 4070, 2025 г.
Если вы умнее автора и хотите его поправить, поделиться житейской мудростью или сказать, что он ФУЛОХНЕРАЗОБРАЛСЯ, можно это сделать (●'◡'●), внизу есть контактики.
upd: 1.12.2025 v1.1 - добавилось немного инфы про всякое.
Тема кэширования раскрыта чуть лучше. Добавилась инфа про русик (в том числе добавлен рек модели для суммаризации русского текста). Интересный факт тоже оброс подробностями, но немного.
пришлось пилить новую рентри, потому что эдит код от старой я проебал - позор мне.
За помощь и прояснение некоторых вопросиков благодарю мудреца, который пожелал остаться анонимным.
ВЫ ТОЖЕ МОЖЕТЕ ВСТАВИТЬ СВОЮ ЛЕПТУ И ПОДЕЛИТЬСЯ МУДРОСТЬЮ, написав автору.
Речь тут пойдет в основном про большие модели, вроде той же гемини, клода и прочих ГПТ. Если вы запускаете локалки, то вы все это и так знаете (наверное).
НАВИГАЦИЯ:
- Как экономить токены и на.. зачем это надо. Версия 1.1
- Экономия токенов: теория. Как работают ЛЛМ (большие языковые модели)
- На что уходят токены? На все.
- Итоги и контактеки
Экономия токенов: теория. Как работают ЛЛМ (большие языковые модели)

Большие модели – это огромные нейросети, которые обрабатывают текст, но в отличие от человеков они разбивают текст не на символы, а на токены. Приблизительная (очень приблизительная) «стоимость» одного токена – три-четыре латинских символа, кириллица как правило чутка подороже. Не будем останавливаться на математике – каждая модель считает токены чутка по-своему (зависит от токенайзера), поэтому это бесполезно.
Модель учится на огромных полотнах текста – это книги, описание порева на ао3, письма вашей тете на гугл почте (привет, гугл!) и так далее. Она замечает, какие токены чаще всего стоят друг рядом с другом и учится выбирать наиболее вероятный – поэтому модели генерируют связные текста, в которых для нас, человеков, есть смысл. Хотя по факту, тот же самый ГПТ – просто хитрющий т9, умело мимикрирующий под нечто разумное.
ИНТЕРЕСНЫЙ ФАКТ
А ЗНАЛИ ЛИ ВЫ, ЧТО ВСЕ МОДЕЛИ – ГПТ??? Ну, то есть буквально – нейронки, которые генерят текста, относятся к семейству Generative Pre-trained Transformer. Но просто как-то так исторически сложилось, что техническая аббревиатура стала именем нарицательным для творения Сэма Альтмана.
UPD для прояснения:
Фанфакт сверху - это оч общее... ну, обобщение, вставленное ради кеков. Правильнее будет сказать, что современные ЛЛМ (клоды, гемини, гпт, дипсики и прочие лламы) - дети одного родителя, взявшие за основу одну технологию, но реализовавшую ее по разному. Думайте об этом как... про автомобили. И жигули, и феррари - автомобили, которые ездят, но ездят они немного (много) по разному.
Из чего состоит запрос к модели и че это вообще
Запрос – это то, что юзер пишет модели в чатик. Для модели он выглядит как набор тех самых токенов, и задача лобомита – построить на основе вводных (input) токенов свой ответ – вывод (output).
Запрос для модели состоит из нескольких кусочков.
1. Системные инструкции. Задача для модели, которую мы перед ней ставим. Например: «ты крутой ролевик, который просидел свою задницу на фикбуке, играешь в ролевую игру с юзером. Напиши ответ от лица персонажа». В него обычно и входят определения бота, персоны, авторские заметки и другие кусочки.
2. История диалога. Все предыдущие сообщения между юзером и ИИ. Обычно история диалога выглядит как последовательность ответов:
Ассистент: Привет, я Клодик, большая и умная и дорогая языковая модель! Давай играть!
Юзер: Привет, клодик! Будь моей мистресс!!
Ассистент: Ну ладно… (достает плетку из заднего кармана)
3. Запрос юзера: ну, соответственно, его последний ответ. В нашем примере:
Юзер: АХ АХ МИСТРЕСС!...
…на который ассистент даст ответ.
В итоговом виде структура передается модели подряд:
- Системный промпт
- История сообщений
- Новый запрос пользователя.
При этом история чата будет расти в арифметической прогрессии (в основном). Почему это происходит?
Дело в том, что каждый новый запрос к ЛЛМке будет состоять из истории всех предыдущих сообщений – то есть каждый раз юзер отправляет нашему клодику не только свой поток мыслей, но еще и то, что произошло до.
Простая математика:
- В начале чата Борис имеет системный промт в 1000 токенов, дефиниции бота и персоны (еще 1000), а также приветственное сообщение от бота в 400 токенов.
- Борис пишет свой ответ, ну, скажем, в 50 токенов. Итого – он «введет» в сетку 2450 токенов. Это импут.
- Лобомит напишет ответ еще на 100 токенов (это вывод, оутпут).
Если Борис продолжит чатик и напишет второй ответ лобомиту (еще 50 токенов), в его запрос (ввод) уйдет не 50 токенов, а все 2500, так как сетка не хранит историю чатика и каждый раз размер инпута раздувается все больше и больше.
Получается почти арифметическая прогрессия роста запросов – с каждым разом мы будем кормить сетку все большим и большим количеством токенов, дольше ждать ответа и все такое.
Как это контрить? Полностью – почти никак (это архитектурная особенность вроде как), но кое что сделать можно. Об этом дальше.
UPD для прояснения:
многие провайдеры поддерживают кеширование. Кеширование позволяет провайдеру не принимать весь инпут каждый раз, а сохранять постоянные его кусочки у себя. Вместо того чтобы каждый раз отправлять полную простыню, вы отправляете только новую информацию, а статичную часть промта, которая не изменилась, провайдер подтянет из кеша. Об этом (и о НЮАНСИКАХ, потому что куда ж без них) - в разделе про кэш. Пока мы условно про кэш забудем и сделаем вид, что его не существует, а попозже разберем и вернем
А почему длина запросов – это проблема?
Причина проста, как мир. Это деньги.
Большинство провайдеров использует модель монетизации Pay-As-You-Go, и расход токенов напрямую влияет на стоимость запросов.
 (для примера – стоимость запросов к превьюшке Гемини 3 с опенроутера)
(для примера – стоимость запросов к превьюшке Гемини 3 с опенроутера)
Казалось бы – один токен стоит почти ничего, а чтоб столько написать, надо ну очень постараться. Однако как и везде, тут есть подвох – как мы выяснили выше, запросы к модели растут ОЧЕНЬ быстро, а так как мы каждый раз кормим ее историей чатика, можно оч быстро остаться с голой задницей.
При pay-as-you-go ты платишь за каждый токен, отправленный в модель (входные (input) токены) и за каждый токен, сгенерированный моделью (выходные (output) токены). Поэтому, привязав карточку к тому же ОР, можно быстро заметить, что деньги с нее летят хрен знает куда.
Я – нефтянной шейх! Или я сижу на бесплатной проксе! Или мне вообще пофигу, я хочу чтоб модель помнила каждый мой чих!
Большие контексты – это вопрос денег... но на самом деле не только их.
Большой контекст – это иллюзия.
Гугл хвастается, что его модель спокойно вытянет контекстное окно в несколько лямов токенов! Клодик тоже недалеко ушел: соннеты вытянут один миллион и не подавятся! Да даже опус 4.1 вытянет 200к, что хоть и меньше, но все равно, на один томик хорошего писева хватит!
В контексте (ха) контекстного окна мы часто воспринимаем его размер как размер ПАМЯТИ, но тут есть один нюанс…
Играющие на больших контекстах могут заметить, что персонажи время от времени начинают забывать какую мороженку они ели 40к токенов назад, путаться в цвете собственных трусов, не узнавать собственных детей и страдать другими вариациями ретроградной амнезии…. Почему это происходит?
Современные ЛЛМ имеют в себе общую фичу (или баг) – они хорошо реагируют на начало содержимого контекстного окна, проваливаются в пропасть в середине и более-менее ориентируются в конце. Для моделей важны первичные инструкции, что в начале запроса, потом недавние (что было последним), а что остается посередине обрабатывается на отвали. Чем запрос длиннее, тем этот серединный провал заметнее.
Этот феномен называют «Lost in the Middle».
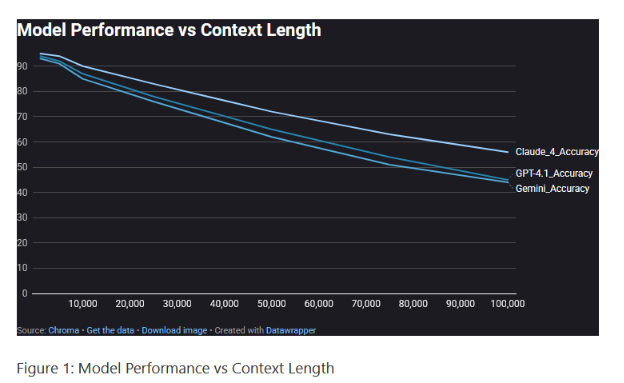 (статья про работу АИ агентов – нам она нахрен не нужна, только сама метрика. Припасть – тут https://www.rockcybermusings.com/p/the-context-window-trap-why-1m-tokens)
(статья про работу АИ агентов – нам она нахрен не нужна, только сама метрика. Припасть – тут https://www.rockcybermusings.com/p/the-context-window-trap-why-1m-tokens)
Так что да – чем длиннее ваши запросы по себе, тем этот «провал» заметнее, а модель тупее.
Эффект протечки или «у вас клодик протек»
Если мы говорим о ролевках, то у нас есть большая, ОГРОМНАЯ, насыщенная история чатика, которую мы будем скармливать модели при каждом запросе – а так как модель по сути оч хитровыебанный т9, наш Клодик будет смотреть на всю переписку и формировать свои ответы, исходя из нее.
Большая история чата будет со временем вытеснять системный промт, заставляя модель вести себя НЕПРАВИЛЬНО, игнорируя инструкции и заставляя галлюцинировать. Из-за того, что информации много, модель начинает путаться – сначала в мелочах, потом, по мере накопления инфы, более серьезно – и лениться, выдавая шаблонные ответы.
Фанфакт:
Так называемые клодизмы, геминизмы и прочие -измы – это любимые «ленивые» паттерны модели. Вместо того, чтоб придумывать что-то новое и интересное, модель лезет в проверенную (по ее мнению) классику и выбирает токен, который встречался чаще всего. Отсюда растут ноги к так называемых якорей, озонов и прочих шилвер он май спайн. У каждой ЛЛМ -измы свои, но так как очень часто нейронки обучают на выводах друг от друга, -измы они наследуют.
Чтоб было понятно, вот вам пример.

Мы играем на гемини, и наш ботик – няшная заботливая лисожена (правда оока мико - волкочевочка, но ДОПУСТИМ).
- В самом начале наша лисожена гладит нас по голове, варит вкусный супчик и машет хвостиком, как сказано в промте.
- Мы взаимодействуем с нашей лисоженой, общаемся и комфортимся, и в процессе она вкидывает неловкую хехешную шутку про озон. Мелочи, но оно началось...
- Через некоторое время лисожена начинает грубить и ехидничать. Она начинает подозревать юзера в неверности, хотя вокруг - ни души, и время от времени вбрасывает неоднозначные намеки на то, что вкусный супчик в следующий раз лучше не есть. Такого не должно быть, НО ДОПУСТИМ, у лисожены был плохой день.
- ????
- лисожена начинает шизеть, берет бензин из гаража и, познакомившись с милой девочкой-волшебницей, сжигает вашу уютную лесную сычевальню нахуй. Хотя в системном промте такого не было, да и в чатике вроде как тоже…..
Как итог: история чата "затягивает" модель в другой контекст, и она выходит из роли, заданной системным промптом. Отсюда – так называемые протечки, т.е скатывание личности персонажа в предрасположенности ассистента.
Так значит контекстное окно – это обман???
И да, и нет. Скорее это маркетинговая уловка. Это звучит красиво, позволяет собирать много деняк и даже работает не так погано, как кажется. К тому же, за последний год ЛЛМки шагнули далеко вперде, и те же 32к сейчас и 32к тогда – совсем разные 32к.
Рекомендуемый размер контекстного окна по моим наблюдениям
На современных моделях с думалкой – примерно 50-64~к. Без думалки меньше. Дальше уже начинается шиза.
Про серые\черные прокси

Тут речь идет про серые\черные прокси, которые предоставляют доступ для юзеров бесплатно\за небольшую сумму. Мы не будем касаться вопроса этичности, потому что все и так знают, что воровать – плохо, а еще ваши логи могут слить и показать маме. Это очевидно и понятно.
Теория
Мы уже поняли, что запросы к башим моделькам – это дорого и страшно, но ведь можно взять и сэкономить! В сравнении с предыдущим годом, таких проксей стало сильно меньше, но они все еще есть и представляют свои услуги. Иногда – за спасибо, иногда – за денежку, иногда – за что-то еще. Автор сия писева знает, например, про прокси, за доступ к которой нужно было нарисовать поняшу или вырастить чайный гриб.
ЛАДНО. КАК ЖЕ ПОЯВЛЯЮТСЯ ТАКИЕ ПРОКСИ?
Можно предположить, что кто-то добрый и милый делится своими деньгами с народом – отметать такой вариант не будем, но обычно все куда проще.
Представим, что у нас есть Ваня. Ваня – начинающий разработчик на пайтоне и пилит свой проект с ИИ лисоженами. Ваня – милый и законопослушный. Что же он делает?
- Ваня регистрируется на платформе OpenAI (или другой) и получает API-ключ
- Он кладет деньги на счет, чтобы оплачивать запросы к модели ИЛИ привязывает к ключу свою карточку, чтоб в случае чего не кидать туда деньги постоянно
- По какой-то причине Ваня теряет свой ключ: он может по глупости засветить его на своем дискорд сервере или забыть в репозитории, или мб его обманул злой скамер… не важно, суть понятна.
- Чел (давайте назовем его… ну, Валерой), нашедший ключик Вани, кладет его в свою копилочку и запускает прокси
- Теперь прокси Валеры работает! И когда пользователь прокси Валеры делает запрос через него, в мире плачет один Ваня, потому что именно Ваня со своей зряплаты оплачивает чье-то нейродрочево. И будет оплачивать, пока деньги на его счету не закончатся или сам Ваня не забьет тревогу.
Схема выше очень абстрактна, условна и передает только идею. Кто-то запускает прокси на чужих ключах, кто-то занимается реверсом (вытаскивает условный клод из условного курсора), кто-то абьюзит какие-то другие схемки…
Но серые прокси конечны и прямо зависят от чужого раздолбайства и кошелька. Провайдеры – тоже не глупонькие, они старательно латают дырки, мониторят утечки и стучат нарушителям по голове.
Даже если сами вы за запросы не платите, у вашего прокси неизбежно возникнут проблемы с предоставлением ключей, если они будут сжираться слишком быстро.
Если один прокси умрет, просто найду другой и все… ведь так?
Не факт.
Известные год назад паблики ныне ушли в тень, гейткип набирает обороты и все такое. Так что даже если кто-то найдет новый способ кумить без СМС, регистрации и платы за токены, не факт что вы о нем узнаете.
Любите своих проксихолдеров, уважайте чужой труд (пусть и не совсем легальный) и кушайте токены разумно.
ПОКУМИЛ САМ – ДАЙ ПОКУМИТЬ ДРУГОМУ. Коммунизм и все такое.
На что уходят токены? На все.
История чата.
Самый простой и очевидный фактор, который влияет на размер ваших запросов. История чата (ВСЯ, не только новый запрос) при каждом запросе передается в модель как часть входного контекста - то есть занимает контекстное окно (см.теорию выше)
При заполнении контекстного окна ST сам подрезает старые сообщения, чтобы вместить в контекстное окно историю чатика, дефиниции и системный промт. Вы тоже можете это делать, но в целом, как мне кажется, это не обязательно – можно всего лишь дернуть волшебный ползунок:
Саммаризация: а что делать, если история уже очень и очень длинная, и ее критически важно помнить??
А тут нам на помощь придет такая великолепная вещь, как саммаризация. Если кратко, то саммаризация – это краткий пересказ того, что было раньше. Представьте, что вам пересказали какую-нибудь книгу или серию аниме – вы будете делать тоже самое, но для ИИ.
Саммаризация – это простой и действительно элегантный способ заставить модель лучше ориентироваться в минувших событиях и неписях. Ничего дополнительно устанавливать не нужно, так как расширение уже встроено в таверну.
Лучше всего, конечно, писать саммари руками – так вы будете иметь полный контроль над «памятью» модели, но это долго, нудно и в основном нахрен надо, если вы не какой-нибудь контролфрик с обилием свободного времени Spoiler(Это ни в коем случае не плохо, автор просто вам завидует).< Второй хороший вариант – заставлять писать саммари саму модель, а затем править руками, добавляя нужные кусочки и удаляя мусор.
Мой любимка на роль писателя-саммаризатора – Gemini 2.5 Pro – он обычно хорошо работает с большими контекстами и улавливает логическую связь между событиями. Не идеально – перст указующий ему все еще нужен, но заметно лучше остальных.
Анонимный мудрец говорит, что Клоды (особенно 3.7) в разы лучше пилят саммари русского текста, чем многострадальная геминя - сам я на русике не играю, поэтому склонен верить.
Когда саммаризировать лучше всего:
Саммари – подсказка для модели, и в нем очень важна структура. Не саммаризируйте чатик рандомно – это почти бесполезно. Представьте, что вы расставляете чекпоинты в компьютерной игре – там работают автосейвы после завершения квестов или каких-то глав. Так и у вас – какое-то «глобальное» событие закончилось – саммаризировали, пошли играть дальше. Закончилось еще одно – дополнили саммари, пошли дальше. И так далее.
Когда саммари лучше НЕ делать:
Не делайте саммари в середине сцены, КОГДА ОНА ЕЩЕ НЕ ЗАКОНЧИЛАСЬ. Это только запутает модель и никакой долговременной памяти не случится.
Кроме того, в расширении можно настроить автоматический пересказ: отрубайте его нахрен. Оно вам не надо – автоматические саммари могут сломать уже имеющееся, а как его вернуть – я хз. ИИ не знает, когда события нужно пересказывать, а вот вы – да.
Язык ввода и вывода
Совет не особо актуальный, но упомянуть его стоит. Есть две новости: хорошая и плохая.

Плохая новость:
- кириллица «дороже» латиницы в токенах.
Хорошая новость:
- в последнее время: не слишком.
Старые модели, такие как гпт 3.5 действительно считали кириллицу так, что запросы на ней были дороже почти в три раза, но сейчас, из-за того, что датасеты стали больше и разнообразнее, модели куда лучше (и экономнее) болтают на русском языке. Русские буквы все еще дороже, впрочем.
Точные значения зависят от модели (вообще, от токенайзера, который модель использует), но В СРЕДНЕМ русик тяжелее английского в ~1.5-2x раз. Можно упороться в математику, но давайте будем честными, кому не насрать.
Что это значит?
Если вы хотите упороться в ультимативную экономию, лучше всего играть на английском.
Кеширование
Актуально для тех, кто реально платит за условный Клод на условном опенроутере/прямом апи.

Как уже было рассказано в начале сей нетленки, история чата при каждом запросе будет отправляться заново, набивая ценник на ввод. Но есть способ чутка обмануть систему и все же что-то, но сохранить. Поэтому вместо того, чтоб платить за постоянный ввод одной части (системный промт + первые сообщения), можно платить за кэширование.
КАК ЭТО РАБОТАЕТ???
Вернемся к нашему Борису. При первом запросе Борис отправляет:
- Системный промт (1000 токенов)
- Дефиниции бота и персоны (1000 токенов)
- Приветственное сообщение (400 токенов)
- Свое сообщение (50 токенов)
Так как это первый запрос (Боря только начал клеить свою будущую лисожену), он вбросит лобомиту ВЕСЬ набор токенов (2450). Провайдер еще не знает Бориса, и, соответственно, кэша еще нет.
Борис получает ответ - Клод, напяливший на себя кемономими, выдал еще 100 токенов. Борис радуется и строчит новую простыню, скажем, в еще 50 токенов.
Без кэширования:
Борис отправит лисожене все. Это 2450 токенов из прошлого запроса, ответ от лобомита на него (еще 100) и 50 токенов Бориса сверху. Итого: 2600 токенов на ввод.
С кэшированием:
Когда Борис отправляет второй запрос, провайдер уже запомнил постоянные части контекста с первого запроса. Грубо говоря, Клодик поставил закладку в книжку и сказал себе "АГА МЫ ОСТАНОВИЛИСЬ ЗДЕСЬ". Вместо того чтобы отправлять всю историю (2600 токенов) заново, Таверна Бориса посылает провайдеру только новую информацию - то есть то, чего в кэше еще нет.
Клодик заглядывает в книжку, видит закладку (достает из кэша содержимое предыдущего запроса) и просто добавляет к тому, что он уже знает, ТО, ЧЕГО в промте раньше не было. Борис заплатит только за новую часть промта (и за кэш, что все равно дешевле, лол)
В чем нюансы кэширования??
Казалось бы, вот он, способ обмануть систему! Но если бы все было бы так хорошо, мы бы тут не сидели и не распинались бы об этом.
ПОДВОХИ:
- Сдвиг кэша.
В кэш записывается только неизменная часть промта. Если Борис решит что-то удалить из описания своей персоны, дернуть тогл в пресете, ЧТО-ТО ПОМЕНЯТЬ, весь кэш, который шел после этого изменения, исчезнет. Борис будет платить за новые токены полную цену. И нет, сетка не умеет "нарезать" кэш. - Время - главный враг экономии.
Кэш не хранится вечно. Время хранения кэша зависит от провайдера: например, Google держит кэш в памяти ~1 час, после чего он сгорает. Anthropic хранит его 5 минут (но можно "продлить" до 1 часа, это будет в 2 раза дороже).
Подробности о том, кто и как долго, можно найти в документации самого провайдера - Минимальный порог кэширования.
Кэширование включается только если промт достаточно длинный. Ну, буквально то, что написано на упаковке: если ваш промт слишком короткий, вы пойдете нафиг. К счастью, порог достаточно низок (например, 4096 для Claude Opus 4.5 и Claude Haiku 4.5, 1024 токена для остальных клодиков).
Кэш поддерживают:
- Опенроутер (https://openrouter.ai/docs/guides/best-practices/prompt-caching)
- Deepseek (https://api-docs.deepseek.com/guides/kv_cache)
- OpenAI (https://platform.openai.com/docs/guides/prompt-caching#what-can-be-cached)
- Grok (https://docs.x.ai/docs/models#cached-prompt-tokens)
- Google (https://ai.google.dev/gemini-api/docs/caching)
- И конечно ж любимые нами всеми антропики (https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching)
Да и наверняка кто-то еще поддерживает. Пошарьтесь в документации своего провайдера: если кэширование поддерживается, про это напишут. Гугл тоже может помочь, запрос аля провайдернейм api caching docs творит чудеса.
Рентри на припасть: https://rentry.org/pay-the-piper-less.
Системный промт.

О том, каким должен быть ИДЕАЛЬНЫЙ системный промт, мудрецы спорят тысячелетиями, и мнений тут настолько много, что мое большой погоды не сделает.
Системный промт – это все еще часть контекстного окна, и на него работают такие же правила, как и на все остальное. Это значит, что модель будет более охотно смотреть на то, что написано в начале и становиться все более и более ленивой по ходу дела, обретая какое-то подобие совести только в конце. Чем больше системный промт, тем эти провалы будут заметны.
Значит ли это, что ПРОМТЫ НИНУЖНЫ???
И да, и нет. На системный промт влияют все те же правила, что и на остальное содержимое. Модель внимательнее следит за началом ввода, хуже – за концом, проваливаясь посередине. Если промт содержит слишком много деталей — длинные инструкции, многоэтапный трекинг персонажей или сюжета, модель начинает путаться, потому что не может эффективно выделить самые важные части, и в результате что-то, да потеряет – историю чатика, описание бота или персоны, лорбук, u name it.
Вывод: все эти детальные инструкции по многоэтапному трекингу кто, кого и в какой позе, работают отнюдь не так хорошо, как всем нам кажется, и скорее всего их можно вырезать/переписать ради более эффективного использования контекстного окна.
Определения бота и его карточка
Содержимое карточки бота отправляется прямо в ввод и держится в контекстном окне всегда, поэтому его размер напрямую влияет на размер запросов.

Вам НЕ НУЖНО иметь бота на 7к токенов.
Негласный стандарт коммунити: 1.5к~ токенов для бота. Больше, как правило, и не надо.
Базовые советы по ботоводству:
Автор заметил, что большая часть больших ботов – персонажи с собственным ворлбилдингом или обилием неписей, которые прописаны порой не хуже основного персонажа. Это ни в коем случае не плохо, но не стоит забывать – задача карточки не столько показать вашу фантазию и писательские скиллы, сколько дать ИИ гайд.
Вы – режиссер-сценарист, а нейросетка – актер, который будет играть роль. Актер уже знаком с базой – как показывать те или иные эмоции, как натянуть на себя нужный парик и так далее. Ваша задача – пнуть его в нужном направлении, предоставив ему подсказку и прикладную инструкцию.
Если инфа в вашей карточке не нужна ВСЕГДА И ВЕЗДЕ (например, у вашего персонажа какая-нибудь интересная манера речи, или это драйдер, или что-то еще) – убирайте ее нафиг.
Что можно убрать:
- Детальные описания НПС, которые появляются эпизодически – можно вынести в лорбук, чтоб они подтягивались по ключевым словам, когда этот персонаж заглянет на огонек.
- Детальные описания локаций. Оставить базовые черты (Персонажнейм родился в Кассардисе, рыбацкой деревушке на севере) в карточке, детали (Кассардис – маленькая рыбацкая деревнька, которая стоит на берегу тихого океана, там живет три землекопа и одна собака, а еще там готовят самый вкусный борщик, который славится… блаблабла вы поняли) спрятать в лорбук.
- Излишние детали внешности, которые не имеют значения для повествования (у мафиябосса генадия карие глаза с золотистыми вкраплениями, которые красиво переливаются на солнышке, шрамик 3 см длиной над правой бровью, который он получил когда шмякнулся с качелей, мать тогда его ругала и блаблабла….)
- Бэкстори. Расписывать всю биографию персонажа с детства, если она не определяет его поведение здесь и сейчас, не надо – оставьте ключевые моменты прошлого, которые обьясняют, почему персонаж ведет себя именно так.
- Правила мира, когда не работают ВСЕГДА. Базовые правила – ок, но что-то специфичное – в лорбук. Например, у вас в сеттинге нет магии как таковой – точнее, она есть, но работает только через кристаллы, которые нужно заряжать. В этом случае оставить базовое правило в карточке (В мире нет магии. Заклинания можно юзать через кристаллы) – ок, а саму механику (магия работает через кристаллы, которые необходимо заряжать, есть три вида заряда, которые можно отличать по цвету, красный – это огонь, который… блаблабла) лучше спрятать в лорбук.
- единицы измерений в контексте «его рост был 2.2 метра». ЛЛМ не понимают цифры так, как мы с вами. Гораздо эффективнее использовать сравнительные обороты: напишите, что персонаж низкий или высокий, и этого в целом будет достаточно. Это же и касается писек – если писька персонажа достаточно обычная, описывать ее форму, текстуру, размер до миллиметра (и всякие другие анусы) не надо.
Важно отметить, что все это работает и на описание персон, и на ботов, хотя для персон есть еще кое что:
- Пишите про своих персон только то, что должна знать сама модель (или ваш бот). Это то, как вас ВИДИТ модель и, соответственно, ваша ролочка.
HTML блоки - босс этой качалки и бич этого коммьюнити.
Это будет больно. Это будет грустно.
Таверна умеет выводить красивые HTML блоки и юзать CSS, из-за чего посты могут выглядеть буквально как произведения искусства. Автор оное не любит, то если честно – это вопрос вкусовщины, и об этом тут мы говорить не будем. А вот о чем мы поговорим, так это о том, сколько весит вся эта красота.
Как выглядит блок для нас:
 Для примера: простой (но симпатичный) инфоблок, который помогает нам тречить то, что происходит в сцене, кто в ней участвует и в каком состоянии находится.
Для примера: простой (но симпатичный) инфоблок, который помогает нам тречить то, что происходит в сцене, кто в ней участвует и в каком состоянии находится.
Как он выглядит в виде текста:
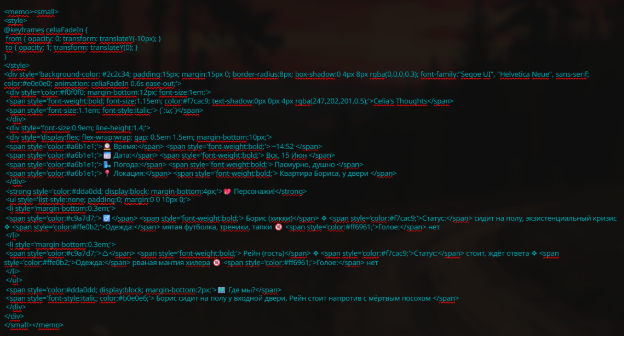
Сам текст внутри занимает всего 295 токена – не так уж и много, правда?

Но если мы посмотрим именно на весь блок и разобьем его на токены…

…увидим это. Милая симпатичная напоминалка превратилась в бомбу замедленного действия и разрослась больше чем в три раза (1020).
И это только в одном посте. А теперь представьте, что будет происходить, если мы будем пилить такие блоки в каждом сообщении и каждый чертов раз скармливать их нашему лобомиту…
Ключ будет плакать и корчиться в конвульсиях, а ваш сосед по прокси может так и не увидеть любимую лисожену, потому что денежки с ключа ушли на украшательства.
Если идея «возлюби ближнего своего» вам не близка, то вот вам другой мотиватор – оно будет заметно отуплять сетку. В вводе будет не только текст, на который лобомит должен будет ответить, так еще и куча всяких скобок и другого мусора, отвлекающего и путающего ИИ.
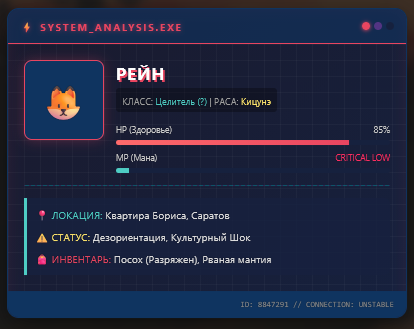 (эта штука весит 1776 токенов… на минуточку….)
(эта штука весит 1776 токенов… на минуточку….)
ТАК ЧТО ЖЕ ДЕЛАТЬ???
1. Самый простой и расово верный вариант: отказываться от подобных украшательств ВООБЩЕ. В конце концов, текстовые сетки генерят текст в первую очередь, и за ним мы сюда пришли.
2. Если вам все ж нужны блоки, используйте их меньше и не в каждом сообщении. Инфоблоки и важную для отслеживания информацию – в обычный текст. Что-то единичное и важное – уже в украшательства.
3. И НЕ ЗАБЫВАЙТЕ УБИРАТЬ БЛОКИ ИЗ ВВОДА. Пожалуйста!
Для этого, собственно, и существуют регексы. Не только для этого, но и для этого в том числе.
Это regex-celia_html_depth_5_vanquisher__.json, взятый из одноименного пресета. Скачать его можно по ссылке ниже.
https://files.catbox.moe/c4xxzl.json
Что он делает?
Убирает из промта все блоки с глубиной в 5. Для вас (визуально) ничего не изменится, и вы и дальше будете любоваться всякими красивостями. Но когда вы будете отправлять новый запрос лобомиту, регекс уберет ВСЕ HTML блоки из запроса, оставив их только в последних 5 сообщениях.
Буквально: включил и забыл, больше от вас ничего не нужно.
Включить регекс можно тут:
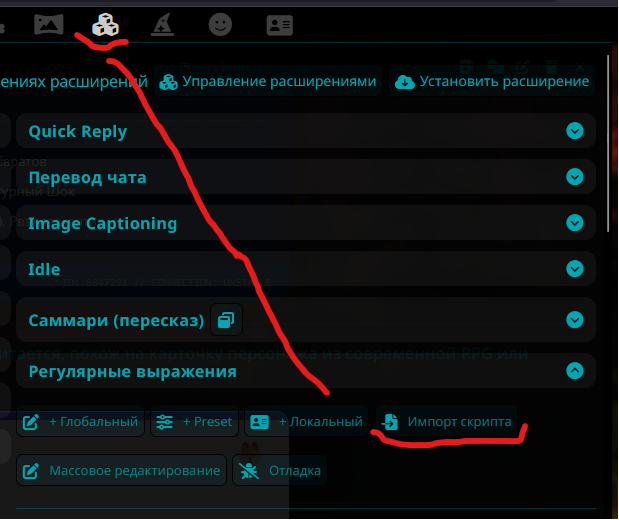
Импорт скрипта => выбирайте скачанный файл => Глобальные скрипты
После этого ваш скрипт появится в списке и вы сможете его включить. Выключенные регексы будут отображаться зачеркнутыми.


Итоги и контактеки
А хз.
Скорее всего будет пополняться, апдейтиться и все такое.
Полезные ссылки:
https://rentry.org/how2claude - олд, бат голд. основные практики промтинга ллм и обьяснения принципов их работы
https://rentry.org/onrms - аналогично, прикладная памятка о том, как и что работает