Гайд по LoRA
by anons последнее обновление: 22.01.2023 English version
Присоединяйтесь к обсуждениям на GitHub если вам есть что добавить.
Нативная поддержка в WebUI
22.01.2023 в 16:15 AUTOMATIC1111 добавил нативную поддержку LoRA нетворков в WebUI.
Но kohya-ss (автор скрипта, используемого в гайде) говорит, что сети, натренированные с помощью скрипта версии 0.4.0 (22.01.2023 16:03), а также обученные на основе SD 2.x чекпоинтов пока в WebUI не работают, и советует тренировать на версии скрипта 0.3.2, либо использовать его расширение sd-additional-networks.
Критический баг (kohya-ss/sd-scripts)
21.01.2023 была поднята тема по поводу бага, вызывающего антипереполнение весов слоёв при обучении (значения весов, близкие к нулю округлялись до нуля).
На момент обновления гайда баг пофикшен: был добавлен новый аргумент --network_alpha для предотвращения данного поведения.
С новой переменной скорее всего нужен другой learning_rate (автор скрипта как временное решение предлагает значение 1e-3 для network_dim = 128; network_alpha = 1). Ждём обновлений.
Плохие новости – скорее всего ваши сети, натренированные до этого фикса "поломанные". Но если вас устраивает результат, делать ничего необязательно.
Скрипт обновлен.
Если у вас не работает обученная LoRA (выдаёт ошибку NaN или нет изменений на изображении) – обновитесь до версии sd-scripts не ниже 0.4.0 и перетренируйте.
Также вы можете проверить свои старые сети: по пути sd-scripts\networks\ находится скрипт check_lora_weights.py. Пример использования:
.\venv\Scripts\activate
python .\networks\check_lora_weights.py "X:\LoRA\LoRA_network.safetensors"
Внимание! Если вы использовали Clip Skip = 2 при обучении, значения lora_te_text_model_encoder_layers_11_* будут 0.0, это нормально. Эти слои при данном значении Clip Skip не обучаются.
Что это
LoRA (Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning), согласно официальному репозиторию — метод файн-тьюнинга Stable Diffusion чекпоинтов, который имеет следующие особенности:
- вдвое быстрее чем метод DreamBooth;
- маленький размер выходного файла;
- результаты иногда лучше, чем у традиционного файн-тьюнинга.
Требования для обучения: видеокарта Nvidia, не меньше 6Гб видеопамяти.
Использование
На данный момент есть три способа использования сети LoRA:
- Использовать нативную поддержку A1111-WebUI
- Использовать расширение sd-additional-networks
- Замерджить вместе с SD чекпоинтом
Cпособ 1 – использование в промте WebUI
Внимание!
По состоянию на 22.01.2023 19:49 по МСК сети, натренированные на версии sd-scripts 0.4.0, а также SD 2.x сети этим способом работать не будут.
Используйте способ 2.
| 1. Нажать Show extra networks и выбрать вкладку Lora, выбрать интересующую сеть | 2. LoRA появится в промте (отредактируйте значение после : для изменения веса) |
|---|---|
 |
 |
Cпособ 2 – расширение sd-additional-networks
По состоянию на 22.01.2023 19:49 по МСК это рекомендованный способ использования LoRA.
Установить расширение от kohya-ss для A1111-WebUI.
По умолчанию файлы сетей хранятся в папке stable-diffusion-webui\models\lora\
Пользоваться просто:
| 1. Открыть новую панель | 2. Включить, выбрать модель, настроить веса по вкусу |
|---|---|
 |
 |
Cпособ 3 – патч модели
Установить расширение от d8ahazard для A1111-WebUI.
CKPT vs SAFETENSORS
Файлы safetensors (пока) не поддерживаются! Из хороших новостей: обычно ckpt можно скачать там же, где качали safetensors.
Для начала удостоверьтесь, что исходный файл сети <model_name>.ckpt лежит по пути stable-diffusion-webui\models\Stable-diffusion\, а файл LoRA <lora_name>.pt в stable-diffusion-webui\models\lora\, затем:
| 1. Открыть новую вкладку | 2. Открыть вкладку Settings, нажать чекбокс Use LORA |
|---|---|
 |
 |
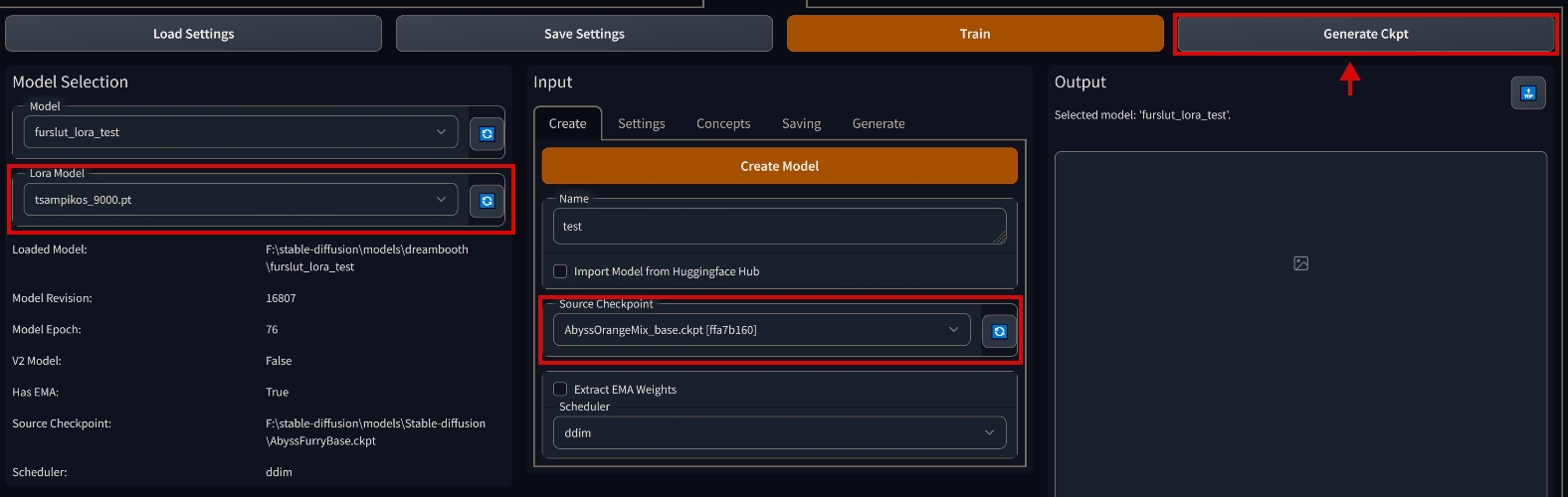
| 3. Перейти на вкладку Create, выбрать исходную модель "Source Checkpoint", выбрать слева "Lora Model" и нажать наверху "Generate Ckpt" |
|---|
 |
Подготовка датасета
Общие советы
Совет №1
Если тренируете на основе аниме моделей (NAI, AnythingV3), описание делать строго в стиле Danbooru/Gelbooru тэгов. Например, 1girl, short hair, green eyes, black hair, school uniform...
Если тренируете на основе SD 1.x/2.x, в описаниях пишите что вы видите на изображении. Например, если изображение – рисунок бородатого рыбака за работой, пишите pencil art of a man fishing, beard; если это фото вашего улыбающегося друга в очках и красной рубашке на фоне заката, пишите photo of friend_name, smiling, wearing glasses, red shirt, sunset in the background)
Совет №2
Если тренируете персонажа/человека, желательно чтобы датасет состоял только из изображений, где он присутствует. И чтобы во всех описаниях было ключевое слово, описывающее этого персонажа/человека. Например, 1.txt: photo of AndrewFriend, jacket, jeans; 2.txt: photo of AndrewFriend, shorts, t-shirt. Вызывать вы данного человека в промте будете соответственно через тег AndrewFriend. Тоже самое работает и для аниме моделей – в этом случае это будет имя персонажа. Например, 1girl, shiina mayuri, short hair, green eyes и т.д. Вызов через shiina mayuri соответственно.
Если тренируете авторский стиль, как и в предыдущем абзаце желательно чтобы датасет состоял только из изображений, нарисованных данным автором. Пример описания: ArtistName, mountains, night, moon, snowy peaks, stars и т.д. Вызов стиля художника через ArtistName.
Совет №3
Все ошметки чужих конечностей, непонятные объекты на картинке, подписи художников, ссылки – все, что вы не хотите видеть в генерациях, лучше обрезать или замазать в фотошопе.
Совет №4
Для ускорения ручного тегирования можно использовать мокропиську.
Еще есть отдельная софтина и расширения (1, 2, 3) для A1111-webui.
Для скачивания изображений с различных booru-досок вместе с тегами можно использовать Grabber с такими настройками (скопируйте и вставьте: %all:unsafe,separator=^,^ %).
Для скрипта
Датасету необходима определённая структура папок:
 Пример структуры папок
Пример структуры папок
Где n – количество повторений данного концепта; conceptA, conceptB – имена концептов. Имя концепта может быть любое, оно нигде не используется (кроме особого случая, см. Важные замечания), это скорее заметка для вас, что в этой папке находится. Между количеством повторений и именем концепта обязательно наличие нижнего подчеркивания. Внутри каждой папки концепта должны присутствовать изображения вместе с файлами описания в формате *.txt, их имена должны совпадать. Внутри текстовых файлов должно быть, собственно, описание. Папок концептов может быть сколько угодно, но хотя бы одна должна присутствовать. Обрезать изображения необязательно.
Пример хорошего датасета
Важные замечания
Если у файла image.png не будет соответствующего image.txt, скрипт выдаст ему описание в виде имени концепта. Например, если папка концепта называется 6_photo, будет считаться, что у файла image.png описание photo.
Поддерживаемые форматы изображений: *.png, *.jpg, *.jpeg, *.webp, *.bmp.
Повторения нужны чтобы придать больше веса той или иной папке. Например, у вас есть папка 2_HighRes с 20 изображениями внутри и папка 1_LowRes с 10 изображениями внутри. Суммарно это даст 50 (2 * 20 + 1 * 10) изображений, и нейронная сеть будет обучаться 80% (2 * 20 / 50) времени на первой папке и 20% (1 * 10 / 50) времени на второй, тем самым уменьшая влияние папки с низкокачественными изображениями.
Папка regularization_images может быть пустой, наличие регуляризационных изображений необязательно.
В теории, регуляризационные изображения помогают улучшить точность тренировки.
Регуляризационные изображения позволяют "отделить" тренируемый объект (концепт) от стилистики изображения. Во время тренировки сеть будет "параллельно" (на самом деле последовательно, по-хорошему в присутствии регуляризационных изображений количество шагов обучения должно быть увеличено вдвое) обучаться тому, как концепт не должен выглядеть. Переносимость между различными по рисовке моделями такой сети LoRA должна быть лучше (в теории).
Если вы не знаете, нужны ли вам регуляризационные изображения или нет, я советую не использовать их, кроме случаев, когда вы знаете что делаете.
Как с ними работать
Например, если вы тренируете лицо человека (мужчины) и в каждом файле описания есть слова photo of a PersonName, хорошей идеей будет открыть WebUI и нагенерировать изображений по запросу photo of a man. Сколько? Не меньше чем количество изображений лица мужчины из примера. Больше – лучше.
Запаситесь папками с двухстами изображениями 1boy, 1girl, photo of a man, photo of a woman и будет вам счастье.
Для sd_dreambooth_extension
В интерфейсе поддерживается до 3 концептов включительно
Если вы хотите тренировать больше концептов, придется возиться с JSON. Пример JSON больше, чем на 3 концепта. Обратите внимание на отстуствие запятой после последнего концепта.
У датасета для sd_dreambooth_extension нет особых требований к структуре папок.
Правило одно - на каждый концепт (объект, персонажа, стиль, тег) которому вы учите модель - отдельная папка.
В папке может быть любое количество изображений в формате PNG (не обязательно, но почему-то строго рекомендуется).
Изображения должны быть квадратными, без прозрачности, разрешение - 512х512.
К каждому изображению должен прилагаться текстовый файл с описанием (тегами).
Наличие нижних подчеркиваний в тегах значения не имеет, но поскольку они жрут токены, рекомендую от всех нижних подчеркиваний отказаться.
 Пример содержимого папки концепта
Пример содержимого папки концепта
Тренировка
С помощью скрипта
- Клонировать репозиторий sd-scripts от kohya-ss или скачать его
- Скачать скрипт (ПКМ -> "Сохранить как...") (иногда обновляется)
(либо можете попробовать тестовый GUI)
PowerShell
Данный скрипт предназначен для PowerShell, но это не значит что он доступен только пользователям последних версий Windows. Не все знают, но PowerShell доступен для всех версий Windows начиная с XP, на Linux, а также на macOS.
- Открыть PowerShell и поочерёдно выполнить следующие команды:
- После последней команды терминал начнёт задавать вопросы, выбрать следующее:
In which compute environment are you running?
– This machine
Which type of machine are you using?
– No distributed training
Do you want to run your training on CPU only (even if a GPU is available)?
– NO
Do you wish to optimize your script with torch dynamo?
– NO
Do you want to use DeepSpeed?
– NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list?
– 0 или all
Do you wish to use FP16 or BF16 (mixed precision)?
– fp16 или bf16
BF16 > FP16
Если железо поддерживает BF16, лучше выбрать его.
Если PowerShell сыпет ошибками при нажатии на стрелочки
Выключить NumLock на клавиатуре, выбирать варианты при помощи кнопок 8 и 2 на нампаде. Если нампада нет.
- Редактирование скрипта
Открыть скрипт любым текстовым редактором и изменить переменные вверху файла под свои нужды. Все переменные достаточно понятно прокоментированы, поэтому пройдёмся по не самым очевидным из них:
$train_batch_size: при увеличении данного значения, вероятно также требуется увеличение $learning_rate.
$num_epochs: с помощью этой переменной расчитывается количество шагов обучения. Чем больше эпох, тем дольше обучается сеть. Что касаемо результата на больших и малых значениях, см. описание переменной $learning_rate. Универсального ответа нет.
$max_token_length: откройте свой самый большой файл описания, скопируйте его содержимое и поместите в промт WebUI. Справа на счетчике отобразится длина токена. Если меньше 75, ставим 75. Если больше 75 – ставьте 150. Если больше 150 – ставьте 225. Значения больше 225 скрипт не поддерживает.
$clip_skip: 1 для SD-основанных чекпоинтов, 2 для NAI-основанных.
$learning_rate: значение 1e-4 рекомендовано для чекпоинтов, основанных на SD 1.x. Для 2.x – непонятно, кто-то говорит что получил ужасные результаты с такими настройками. Но у меня получались достойные лица и на рекомендованных настройках.
В чем отличие высокой и низкой скорости?
- низкая скорость и малое количество шагов приводят к недонасыщению сети. У сети будут проблемы с воспроизведением концепта.
- большая скорость и количество приводят к перенасыщению сети. У вас не получится сгенерировать ничего кроме концепта, независимо от промта, который вы используете.
Существует сайт с наглядной демонстрацией.
Далее идут таблицы со сравнением различных learning_rate. Все сети были натренированы на одном и том же датасете (pixiv автора рисунков), все изображения были сгенерированы на одном сиде с разными промтами. Обратите внимание на то, как сети при различных настройках обучились следующим тегам: harusameriburo (стиль художника), jacket, cloudy sky, shoes, ligne claire, backpack, blush stickers.

learning_rate = X, unet_lr = learning_rate, text_encoder_lr = learning_rate, scheduler = linear
$unet_lr: скорость обучения U-Net. U-Net отвечает за преобразование шума в изображение. Поле для экспериментов.

learning_rate = 1e-4, unet_lr = X, text_encoder_lr = learning_rate, scheduler = linear
$text_encoder_lr: скорость обучения текстового энкодера CLIP. Благодаря текстовому энкодеру изображение соответствует текстовому описанию. Есть мнение, что стоит уменьшать скорость обучения текстового энкодера в два раза относительно learning_rate (т.е. до значения 5e-5) для улучшения конечного результата. Также есть информация, что обучение текстового энкодера благоприятно влияет на лица. Поле для экспериментов.

learning_rate = 1e-4, unet_lr = learning_rate, text_encoder_lr = X, scheduler = linear
$scheduler — планировщик кривой learning_rate:
- constant: скорость обучения не изменяется во времени с начала и до конца обучения. Единственный планировщик, который не использует переменную lr_warmup_ratio. Планировщик по умолчанию.
Все остальные планировщики используют переменную lr_warmup_ratio и имеют следующие формулировки:
После периода разогрева, длящегося lr_warmup_ratio% шагов, в течение которого скорость обучения линейно увеличивается между 0 и learning_rate:
- linear: скорость обучения линейно уменьшается от значения learning_rate до 0.
- cosine: скорость обучения уменьшается вслед за значением косинусной функции между learning_rate и 0.
- cosine_with_restarts: скорость обучения уменьшается вслед за значением косинусной функции между learning_rate и 0, с несколькими жёсткими перезапусками.
- polynomial: скорость обучения уменьшается как полиномиальный распад со значения learning_rate до значения 1e-7.
- constant_with_warmup: ведёт себя как constant.

learning_rate = 1e-4, unet_lr = learning_rate, text_encoder_lr = learning_rate, scheduler = X
- constant_with_warmup: ведёт себя как constant.
$lr_warmup_ratio: процент шагов начиная с первого, в течении которых скорость обучения линейно увеличивается от 0 до значения learning_rate. Малые значения или 0 позволяют захватить большое количество информации в начале тренировки и перейти к более тонкой "достройке" к концу. Значения больше могут помочь с проблемой, когда сеть очень быстро перенасыщается в начале обучения. Здесь нужно эксперементировать, датасет играет очень важную роль.
Данный параметр не актуален для constant планировщика.
$network_dim: значения могут быть разные (видел кто-то тренировал на 1024), но было установлено, что выше 128/256 особого смысла лезть нет. Чем больше значение, тем больше расход видеопамяти.
$save_precision, $mixed_precision: как было сказано ранее, bf16 > fp16, поэтому если позволяет железо – ставьте.
$keep_tokens: если включена опция перемешивания текстовых описаний, данная переменная позволяет защитить первые keep_tokens токенов от перемешивания.
Совет
Откройте список всех уникальных однотокеновых слов до 4 символов, выберите любой из них (для персонажа Tomoe Koga я нашел удачный токен tk, например), удалите из всех описаний полное имя персонажа, вставьте во все описания самым первом тегом токен, который вы выбрали. Установите shuffle_captions = 1, keep_tokens = 1. Вы великолепны.
- Запуск скрипта
Если не открывается по двойному щелчку
В папке со скриптом ПКМ в свободном месте -> "Открыть в Терминале" -> ввести .\train_network.ps1 и нажать Enter.
С помощью sd_dreambooth_extension
Гайд основан на версии c5cb58328c555ac27679422b1da940a9b19de6f2.
Новые версии не влезают в 8ГБ VRAM и могут иметь другие проблемы.
CKPT vs SAFETENSORS
Файлы safetensors (пока) не поддерживаются! Из хороших новостей: обычно ckpt можно скачать там же, где качали safetensors.
Установите дополнение sd_dreambooth_extension из вкладки Extensions, перезапустите webui и выключите его после.
Скачайте версию c5cb58328c555ac27679422b1da940a9b19de6f2 здесь или на GitHub.
Извлеките содержимое папки sd_dreambooth_extension-c5cb58328c555ac27679422b1da940a9b19de6f2 в stable-diffusion-webui\extensions\sd_dreambooth_extension\ с заменой файлов.
Для начала удостоверьтесь, что исходный файл сети, на которой будем учиться, <name>.ckpt лежит по пути stable-diffusion-webui\models\Stable-diffusion\, затем:
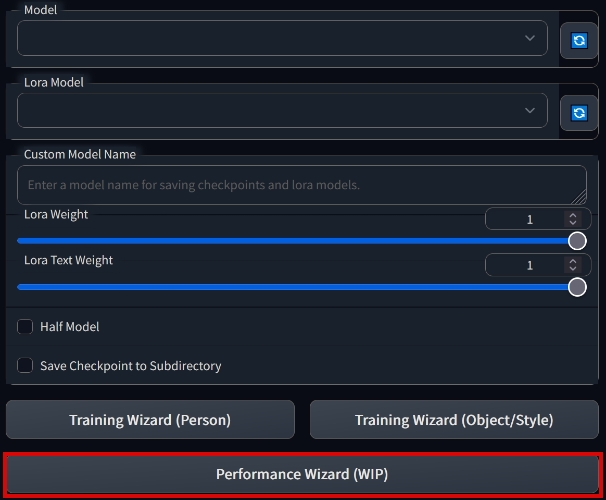
| 1. Открыть новую вкладку | 2. Нажать кнопку "Performance Wizard (WIP)" |
|---|---|
|
 |
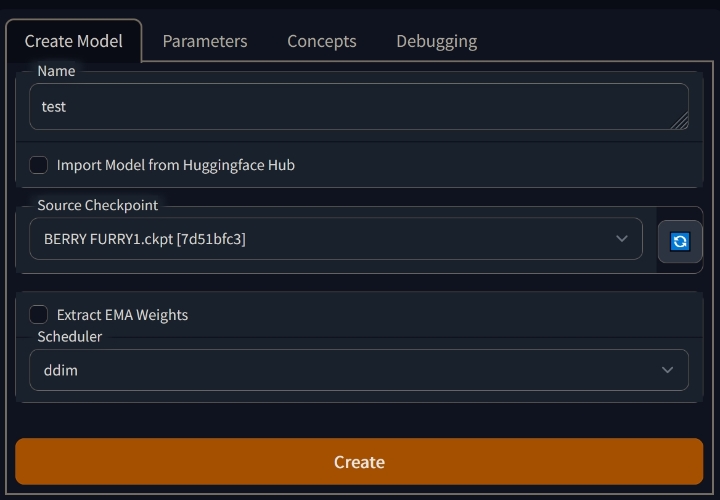
| 3. Придумать название, выбрать исходную модель "Source Checkpoint" и нажать Create | |
 |
4. Проверить настройки во вкладке "Parameters" (сверху вниз):
Intervals
- Training Steps Per Image (Epochs): от 25 до 150.
Больше – лучше, но дольше. Количество итераций НА КАЖДОЕ изображение.
LoRA может быть перетренирована так же, как и ембед с гипернетворкой. Слишком сильно накручивать продолжительность обучения не нужно.
- Max Training Steps: 0
- Pause After N Epochs: 0
- Amount of time to pause between Epochs (s): 60
- Use Lifetime Steps/Epochs When Saving
- Save Preview/Ckpt Every Epoch
- Save Checkpoint Frequency: от 2000
Чем чаще сохраняется модель, тем больше выбор из младших версий, если более новые начали идти по пизде. Жрут место на диске! - Save Preview(s) Frequency: от 500
Чем чаще сохраняются превью, тем быстрее можно увидеть, что модель перетренирована и начала идти по пизде
Оба пункта "Save" замедляют обучение, потому что по-сути приостанавливают его для своих дел.
Batch
- Batch Size 1
- Class Batch Size 1
Learning Rate
Весь раздел "Learning Rate" оставляем без изменений.
Image Processing
- Resolution 512
- Center Crop
Изображения должны быть заранее и осмысленно обрезаны - Apply Horizontal Flip
Не рекомендуется для несимметричных персонажей
Miscellaneous
- Pretrained VAE Name or Path оставляем пустым.
- Use Concepts List
Галка "Use Concepts List" имеет приоритет перед настройками во вкладке "Concepts".
"Use Concepts List" нужно убрать для 3 и меньше концептов и их настройки через интерфейс, как описано далее. Если используете JSON на 3+ концептов, вставляйте полный путь до файла в "Concepts List" и ставьте галку.
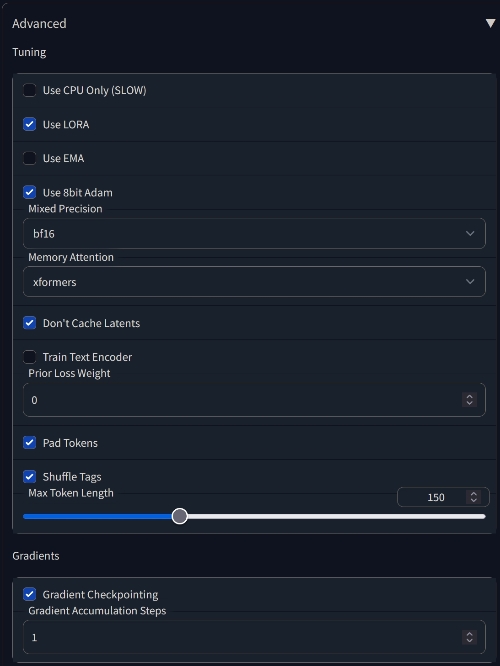
5. РАЗВОРАЧИВАЕМ внизу подменю Advanced и сверяем настройки:
BF16 > FP16
Если железо поддерживает BF16, лучше выбрать его.
Max Token Length
Откройте свой самый большой файл описания, скопируйте его содержимое и поместите в промт WebUI. Справа на счетчике отобразится длина токена. Если меньше 75, ставим 75. Если больше 75 – ставьте 150. Если больше 150 – ставьте 225. Максимальное значение – 300.
6. Переходим во вкладку Concepts и настраиваем концепты:
Пример настроенного концепта (длинный скриншот), устанавливаем только путь до папки с изображениями и [filewords] в поля "Instance Token", "Instance Prompt" и "Sample Image Prompt". Все остальные настройки оставляем (но на всякий случай сверьте со скриншотом).
После этого нажимаем наверху "Save Settings" и запускаем обучение кнопкой "Train".
Превью сохраняются в папку stable-diffusion-webui\models\dreambooth\НАЗВАНИЕМОДЕЛИ\samples. Файлы pt ложатся в stable-diffusion-webui\models\lora.
Какие настройки могут покрутить бояре с 10ГБ VRAM и более:
Обучение вылетело с ошибкой - перестарались, не хватило VRAM, откатываемся.
Вы ведь закрыли все фоновые приложения, которым тоже нужна VRAM, да?..
Продолжая обучать LORA:
- Train Text Encoder
Должен заметно улучшить результат. - Use 8bit Adam
Может незначительно улучшить результат. - Don't Cache Latents
Должен незначительно ускорить обучение.
Обучение полноценного dreambooth (генерирует полновесные модели, осторожно со свободным местом):
- Use LORA
Скорее всего не взлетит, если нет 24ГБ VRAM. - Use EMA
Должен незначительно улучшить результат.
Решение проблем
Скрипт
Q: Какие-то проблемы с CUDA.
A: Вероятно не установлен CUDA Toolkit.
Q: У меня карточка 10-й серии и у меня вываливает ошибку при запуске тренировки. Что делать?
A: Скачать альтернативные библиотеки cuda, файл libbitsandbytes_cudaall.dll переименовать в libbitsandbytes_cuda116.dll, поместить по пути sd-scripts\venv\Lib\site-packages\bitsandbytes\ с заменой.
Q: Не работает расширение для подгрузки сетей.
A: Проверьте, чтобы не было аргумента --lowvram в webui-user.bat. С ним пока не работает.
Q: У меня Windows 7 и PowerShell крашится.
A: Установите PowerShell 6.
Q: Сыпятся красные ошибки в консоли при выполнении скрипта!
A: Обновите PowerShell.
Q: Установил всё по гайду, но все равно не находит модули! Мне что, каждую зависимость устанавливать вручную?
A: Нет, процесс подготовки был отредактирован, а конкретно убран флаг --system-site-packages. Этот флаг отвечал за учёт системных библиотек, установленных по стандартному системному пути, и это нередко приводило к конфликтам (в т.ч. у автора). Удалите папку venv из \sd-scripts и пройдитесь по командам заново.
sd_dreambooth_extension
Новая и старая версии
Строго говоря, новая версия может работать нормально. Но на 15.01.2023 у автора гайда не получилось обучить на ней ничего, кроме мусора (на двух разных ПК), в то время как старая версия работает нормально. Настройки в новой версии примерно те же - можете попробовать ее.
Q: На превью вместо нормальных изображений генерируется мусор.
A: Проверьте, что откатили версию на старую согласно гайду. Если это не помогает, скорее всего вы напердолили слишком новый xformers, torch или torchvision. Создайте отдельный каталог webui для dreambooth (можно с самой новой версией webui) и дайте ему установить тухлятинку. Она должна работать нормально.
Q: Мой интерфейс dreambooth выглядит иначе!
A: Проверьте, что откатили версию на старую согласно гайду. Если вы обновляли дополнения во вкладке extensions, то оно обновило и dreambooth. Откатываемся снова тем же способом. Для dreambooth лучше иметь отдельный каталог webui, который вы не обновляете. Работает - не трогай.
Q: Обучение вылетает с ошибкой RuntimeError: CUDA out of memory
A: Проверьте, что откатили версию на старую согласно гайду. Работоспособность старой версии подтверждена с видеокартами на 8ГБ VRAM, и не подтверждена на 6. Новой версии нужно не меньше 10.