Yet Another Botmaker Guide [WIP]
You think the early 2024 AI RP meta is stale and stupid? Want to listen to someone go on at great lengths about why your opinion is righter than the next guy's? Want to pick up some maybe userful stuff along the way? This is the guide for you.
Disclaimer
As with my other guide (that I totally didn't put on hiatus to go on this detour), I'm getting into this with little more than a few ideas and shallow firsthand experience. But I've been riding on this train since the early AIDungeon colab days, and I do have about half a decade worth of writefag experience also. Take this information as you will.
- Introduction
- Resources, reading
- NLP tasks and the basics of text generation
- A prompt engineering overview of character cards
- Prompt structure
- Token likelyhood saturation
- Encouraging specific behaviours, giving instructions
- CoT prompts
- Example chats, comparisons
- 1, No other prompts, baseline test
- 2, No other prompts, no prose in character description
- 3, No other prompts, character description done by the mentally challenged
- 4, No other prompts, character description done by the mentally challenged + first message done by the mentally challenged
- 5, No other prompts, character description done by the mentally challenged + first message done by the mentally challenged + user is also mentally challenged
- 6, Character description done by the mentally challenged + author's note instructions
- 7, Character description with prose + author's note instructions
- 8, Character description without prose + author's note instructions
- 9, Character description done by the mentally challenged + author's note instructions as OOC fluff done by the mentally challenged
- 10, Character description without prose + author's note instructions as OOC fluff
- 11, Character description without prose + OOC post-script scenario description
- 12, Character description with prose + separate scenario description with prose
- 13, Character description done by the mentally challenged + separate scenario description done by the mentally challenged
- 14, Character description without prose + OOC post-script scenario description + author's note instructions as OOC fluff
- 15, [NSFW] Character description without prose + OOC post-script scenario description + author's note instructions as OOC fluff
- 16, [NSFW] Character description with prose + separate scenario description with prose + author's note instructions
- 17, Character description with prose + CoT
- 18, Character description without prose + CoT
- 19, Character description done by the mentally challenged + CoT
- 20, Character description done by the mentally challenged + CoT done by the mentally challenged
- 21, Character description with prose + CoT + author's note instructions
- 22, Character description without prose + CoT + author's note instructions as OOC fluff
- 23, Character description without prose + CoT + author's note instructions as OOC fluff + OOC post-script scenario description
- 24, Low temp tests
- 25, Low temp tests with penalty settings
- 26, Bonus: vocabulary wall of text
- 27, Bonus bonus: compacting
- Concluding tests
- Some more writefag advice
- Some more prompting advice
- Attention is all you need
- Overlooked tools for prompting
- Conclusion
- Addendum
Introduction
This document is mostly intended to be a revisiting of older, foundational ideas that got us started working with character cards; and how I think the "science" of prompt engineering and the "soul" of writing scenarios could complement one another, if only we'd stop guessing what works and what doesn't.
This is not to say I think current prompt set makers and that all card makers are stupid, it's only that more often than not I feel like people are throwing stuff at the wall until something sticks, and then keep building on top of that until there are so many moving parts that it all becomes brittle and closed to meaningful modification. I also feel like lots of cards nowadays are bloated and want to be things that current AI models just cannot service - both on a technical level and in writefag terms.
Also, we'll stick to SillyTavern. Though a lot of what I'll talk about can generally be applied to all sorts of models, but I don't watch to touch on stuff like instruct modes and whatnot.
Resources, reading
In this guide I will be making a LOT of references to stuff people smarter than me already talked about. I'll compile here a list of stuff to read through, to get a solid understanding of principles I want to discuss writing this. You will find that many of these documents and articles have references to other things, in which case I assume you will in the very least look at them, but more preferably read it all.
A lot of further reading material is sprinkled throughout this document as they become relevant (and I implore you to read them all), but the material listed here will give you a good-enough understanding to be able to discuss these topics with more confidence and less empirical or circumstancial, anecdotal thinking.
https://rentry.co/alichat
https://rentry.co/plists_alichat_avakson
https://wikia.schneedc.com/bot-creation/trappu/creation
https://wikia.schneedc.com/bot-creation/trappu/introduction
https://wikia.schneedc.com/bot-creation/trappu/post-creation
https://rentry.org/vcewo
https://www.deeplearning.ai/resources/natural-language-processing/
https://generative.ink/posts/methods-of-prompt-programming/
https://docs.anthropic.com/claude/docs/prompt-engineering
https://www.promptingguide.ai/
https://peterwestuw.github.io/surface-form-competition-project/
https://arxiv.org/pdf/2304.03442.pdf (*)
https://arxiv.org/pdf/2101.00190.pdf
https://arxiv.org/pdf/2104.08691.pdf
https://arxiv.org/pdf/2104.08315.pdf
https://cookbook.openai.com/articles/related_resources
https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results
https://medium.com/@maximilian.vogel/the-10-best-free-prompt-engineering-courses-resources-for-chatgpt-midjourney-co-dd1865d4ad13
https://www.lesswrong.com/s/r9tYkB2a8Fp4DN8yB/p/q2rCMHNXazALgQpGH
https://www.lesswrong.com/posts/yRAo2KEGWenKYZG9K/discovering-language-model-behaviors-with-model-written
https://www.lesswrong.com/posts/D7PumeYTDPfBTp3i7/the-waluigi-effect-mega-post (*)
Truthfully, in this guide we'll go on conjecture to a lot of what these documents talk about. The reason why I suggest reading these is to understand where we came from, what early observations helped shape working with LLMs both commercially and for us, why these observations had been made, and whether they still hold truth to them or had they become deprecated. And if any did, was it for good reason or just a flamboyant change in trends?
NLP tasks and the basics of text generation
Of all the reading listed above I want to focus on two first, that describe certain interesting aspects of LLMs. I marked these with an asterix.
One of them describes the AI impersonating a character, a simulacra, to fit a roleplay scenario the user asked for. But that this simulacra isn't reflective of the personality or nature of the AI, it's merely one of many such simulacra it could play. And that all these possibilities exist in a sort of superposition, of which we want to collapse into some text (tokens) that is beneficial for us, via prompting.
The act of prompting is nothing more than making some tokens more likely to be picked than others.
This is VERY important.
The other document talks about the "Waluigi effect", that in essence makes two assumptions about the likelyhood of a token being picked for generation based on the prompt. The first assumption is that if the Komolgorov complexity of the token you want to collapse into is close to the rest of the prompt (at least the end of it), then it's more likely that tokens fitting that complexity will be chosen. This isn't particularly true for token generation as an NLP task, but it can be observed to happen because the AI is trying to generate coherent text, and in natural, human-spoken language, Komolgorov complexity of the beginning and end of a sentence/statement/idea/paragraph will probably be similar-ish. It may also explain why all AIs want to get more same-y the longer the RP goes on. Because same-y text probably also has similar Komolgorov complexity. Now, before we'd get ahead of ourselves - no. It's unlikely that we can create prompts to affect this behavior directly. But paired with the other assumption the document makes, it might just be the explanation why jailbreaks can exist at all. The second idea is that during reinforced learning, a model may learn to pose both as the simulacra of an aligned agent (for example the polite ChatGPT), but it is also in superposition of an agent with shady motives that is pretending to be aligned (the post-jailbreak ChatGPT). If you read the lesswrong.com article on mesa-optimization, this might as well just be the product of that.
So... How is this all useful for us? In practice, not really, yet. But it's to give you a perspective about the nature of text generation, and the goal of prompting: to make some tokens more likely to be picked, by making other tokens less likely to be picked.
A prompt engineering overview of character cards
Often a JB, a prompt set, or even a card wants to do everything. Set the style of the writing, the character(s!) to be played by the AI, the length of the replies... Everything. People often try - and even the very software of SillyTavern and websites like chub promote it - to combine multiple prompting techniques at once. Giving examples in the character card is essentially few-shot prompting. Setting up the character personality is a very complex flattery prompt. A prompt set may add a CoT prompt on top of this. Some include XML, some use W++ or JSON, and some do none of these things. It's all bits and pieces of stuff we hope adds together to what we want it to do. And that's just for the first message. Later on we might use and update the author's note, or use dynamic lorebooks, or scripts.
So I want to address three things here.
First, that the structure of a prompt (meaning all of the text sent to the LLM for it to pick the next token) does matter. It's our most powerful tool of all. To give you a very basic example, if you write your prompt in a language other than English, the LLM will favor any and all tokens in that language, over ones traditionally found in English text.
Second, different types of prompts have different goals. You would use a different prompt technique asking for infilling, extracting, summarization, agent- or assistant-like behavior, querying, etc. More isn't better. With a larger screwdriver it might be easier to hit a nail than with a smaller one, but you might as well just learn to use a hammer.
And third, always remember that these models are trained on stuff you find on the internet. People interacting on forums, comment sections, irc chatlogs, talking about TV shows and books, and yes, a lot of roleplay too. Think of a flattery prompt where you say the character in question has 9000 IQ. It's an instruction, sure, but the AI will treat it as just some text that it has to generate the next part for. And people online probably didn't really act like someone with 9000 IQ after claiming that they may actually have 9000 IQ. Probably the exact opposite, as it's likely to be sarcasm, when someone says that. Instructions, no matter how detailed, won't be interpreted by the LLM as instructions.
Unfortunately research papers doing any sort of exploration or benchmark into roleplay-like LLM behavior is few and far between, but I can recommend works from these authors:
- https://arxiv.org/search/cs?searchtype=author&query=Reynolds,+L
- https://arxiv.org/search/cs?searchtype=author&query=McDonell,+K
Or: - https://gwern.net/gpt-3
- https://arr.am/2020/07/31/gpt-3-using-fiction-to-demonstrate-how-prompts-impact-output-quality/
- https://arxiv.org/pdf/1806.11532
Or: - https://aidungeon.medium.com/world-creation-by-analogy-f26e3791d35f (kinda outdated)
Prompt structure
Let's start with some fundamentals. A character card usually includes the following parts: description of the character; description of the scenario; examples, first message.
The character description
As discussed above, the character description is basically a flattery prompt. Except we don't usually want the played simulacra to be polite, but to mirror the personality of a character from a TV show, anime, or game; or some OC. This is fine. We can and should treat it as a flattery prompt.
But! At the beginning of the RP, the character description will be a HUGE part of the prompt. Maybe a third of it or more. You would have to try very hard for the AI to only treat it as a piece of instruction, and not take the style of writing into account, for example. Some people try to combat this with XML, some others expect this behavior. It might even be built upon, having the character IC give a description of themselves. To keep it strictly a flattery prompt, we will want to avoid this though.
And the solution can be pretty simple: use JSON or W++ for the character description. If, immedately, you disagree with this statement - because W++ is a token sink, ugly, useless, or all three of these in your opinion - please do check out the prose vs no prose examples later on, especially in contrast with the "mentally retarded tests" (#5, #14, #16, and #18 are pretty demonstrative imo); and please also take a look at the provided reading material on few-shot prompting, emergent CoT, dataset location, golden vs sampled labelling, and task location. You'll find these at the relevant parts of this document with my thoughts on each of them. The combined understanding of these topics suggest to me that the character description itself is better off without prose. But I digress.
W++ not only can be fewer tokens (when done correctly), but a non-human-spoken language helps the AI differentiate it from the rest of the prompt. You may also add XML on top, but this is already a great way to implement separation of concerns. A structure like this is also universal, in the sense that a user may have a hard time (or not even try) to match the style of prose in the character description, making it harder for the LLM to guess what style you want it to emulate.
At this point if we omitted all the rest of the prompt (assuming the presence of a basic JB to allow the RP to happen), we already have cut off a very, very fucking big part of all the simulacra superposition possibilities. That is to say, the LLM will answer in-character. How long its replies or in what type of prose it may use? That's up to further specification. But it's not the responsibility of the character description.
As a sidenote, you may argue here that the character description both defining the simulacra and encouraging a given writing style could only be a win-win, as it helps conserve tokens. And that's technically true. But W++ already conserves tokens, when used correctly, and it allows us to reason about pieces of our prompt better. Which is vastly more important.
The examples
Let's go a bit out of order here, and talk about the message examples before discussing the rest. Usually, the goal of using examples is twofold: primarily to further specify the character's personality and behaviour; and second, to define on encourage a style of writing. In both cases, it's few-shot prompting.
The decision to use or not use examples is in my opinion very significant. Because few-shot prompting is "stronger" than a flattery prompt, in that the two techniques clash. And since few-shot gives the AI a more obvious conclusion to reach, the flattery prompt will become secondary instruction, compared to it. Especially if we use W++, causing the examples to take up at least as much if not a lot more tokens than the character description.
My recommendation here is this: if you do prose in the character description, you're allowed to use examples. At that point, it really doesn't matter as much. But if you use W++ or JSON, then do not use message examples at all. The reasoning for this is in the next section.
Some more reading on this:
- https://arxiv.org/pdf/2102.09690 (this one is very decent)
- https://arxiv.org/pdf/2101.06804 (not very useful for us but interesting)
- https://arxiv.org/pdf/2209.01975 (^same)
- https://arxiv.org/pdf/2104.08786 (this is nice)
- https://arxiv.org/pdf/2205.03401 (this one lays out the problem of asspulls nicely, then goes into meaningless benchmarks)
- https://arxiv.org/pdf/2202.12837 (some more problems with few-shot exemplars, I really REALLY suggest reading this one)
- https://arxiv.org/pdf/2109.01247 (even more problems with few-shot exemplars (and instructions))
A short aside with respect to these papers, because I bash exemplars a lot in this document. So to be clear, few-shot is a very powerful tool and its results are very easily observed. But there are just as many undeterministic side effects, causing other parts of the prompt to become less effective, especially when it comes to continuous roleplay with a bot. Besides the obvious behavior that I described above the way you pick and word your examples matters a whole lot, and it makes a huge difference between models different users may be using. Which could be fine, if we knew or could determine whatsoever what effect an example will have. But we don't, and we can't (or can we). When the exemplars and the task itself is very direct, for example the sentiment analysis problem often being used for benchmarks, or if it's something like a translation text with a couple of examples, then even unoptimal exemplars make a drastic difference in making the generated text more useful for the task. Determinsitically, even! But having the LLM act out a simulacra is very much not a simple task. Giving a vague exemplar that's just some random scenario at best helps the AI pick up on the character's intended vocabulary, but it cannot 1:1 match it up to some imaginary person's behavior as translated words can be matched up with one another. It's the equivalent of giving the LLM an instruction to "be creative". This is my problem with exemplars.
An aside for the aside: if you're still positively determined to use examples, I'd recommend getting the LLM to generate them. You may use your own few-shot prompt for it. This should at least partially resolve the encoding-distance problem (for that given model), even if you're picky, in due to being a sort of manual automated-prompt-engineering. See this explanation and this paper. And please, make at least 6 but no more than 16 examples, and label their use-cases. Definitely don't go below 4. Mix and match positive and negative ones, don't put similar ones near one another.
Description of the scenario and the first message
Okay, there's a lot to talk about here. Both technical AND writefag stuff. Let's start by continuing the sentiment from the last section:
Instead of using examples, we'll want to leverage the LLM's dataset by making it "think" it's in a situation that has a trademark style of interaction between pieces of the simulacrum, and make this affect the simulacra. In laymen terms, instead of telling the AI that this is a roleplay, act in a way that real people online would have acted in a roleplay, that is probably included in the LLM's dataset. For example, you don't give the other person detailed instructions in how to write, right? And a book wouldn't include that kind of thing either. (We'll revisit encouraging specific behavior later.)
Again, the goal isn't to define the behaviour you want. It's to make other behaviours less likely to "make sense", so that the AI will pick tokens accordingly.
So how do we do this? Consider the difference between the first message and the scenario description. If the first message makes it very obvious what's going on, then the scenario is mostly redundant. A lorebook might be a better choice if you have nuanced details to add, if you really need to relay that extra information. If the writing style of the first message is customary for internet roleplay (for example using asterisks to mark narration), and there is no other human-spoken language in the prompt (other than an assumed JB), then it'll make it very likely for similar tokens to appear with high likelyhood, and way less for, say, language you may find in a technical paper. You may even give other hints in the first message, like an "(OOC: something something)" post-script. If your scenario description is short enough, at most two short sentences, an OOC addendum may be the perfect fit for it.
Now, let's talk about something that isn't technical, but a thing that I see more and more cards do with their first message. It wants to be the scenario description also, I think, and that makes the whole thing way, WAY too long. It obviously can come down to just taste, we're all human after all, but we're not writing light novels here. You can absolutely use AI for that, don't let me tell you that you can't, but SillyTavern and character cards aren't the right medium for that. I often see that bot makers want to achieve a level of specificity that simply isn't possible with LLMs. As with image generation and stable diffusion, it's practically impossible to have the AI act in the highly-specific and nuanced way you want it to act. A general idea of a character, say, "the hot girl in class" or "the elven ranger" gives plenty for the LLM to work with. It's something to match up against pieces of its dataset. It's good at generalization and stereotypes, and knowing where those stereotypes appear. But it's bad at Lenore the 24 and half year old girl with C-cups who lives two streets from you at the crossing near the rails and is one year below you at school because she skipped a year to go to France and and and... Likewise, the LLM will basically refuse to have the simulacrum be about a scenario it has no idea how to simulate. Not unless it's continuously encouraged to do so. (That we'll talk about later.)
But a long first message and a highly specific OC can also, in a writefag sense, make the card resonate with fewer people. As well as the LLM, people latch on to something tangible easier. No matter how well thought out your character may be, even if the AI could perfectly simulate it, an onlooker will probably only see something superficial at first - a hot girl, a grumpy adventurer, a bratty goblin. So on and so forth. Only so few people will take the time to read an unreasonably long first message and give the character a real try. And it's also unlikely that they will match the writing style of your first message, examples, and descriptions. This, again, can cause dissonance in the generated text, as now the window for collapsing the superposition is much wider and includes many other contexts, such as exceprts from books, making it harder for all the rest of the prompt, no matter how sophisticated and complex, to coerce the intended behaviour from the LLM.
Of course, this isn't to say that you should set a lower bar at writing, or that your should compromise on the quality. But an overly long first message is probably a symphtom of an issue with the prompt structure.
Long story short, if we have a card with a W++ character description, a reasonably short first message written in trademark RP-style that may also include an OOC PS for the scenario, and maybe a lorebook for stuff later down the line, then it's pretty likely that we've narrowed the next-token-superposition down to a style very close to what we wanted.
Token likelyhood saturation
Of course, token generation probabilities are also in function of generation parameters. Temp, top_p, top_k, so on. But there's also a phenomenon happening here than can make it harder for us to semi-deterministically reason about behaviours. The peterwestuw.github.io article I've linked above explains this pretty well, but similar words (tokens) compete with each other in the top percentages. To the user, it probably really wouldn't have mattered if the LLM used the word "moped" or "bike" or "motorcycle". Yet all three of these probably will have similar likelyhoods. There isn't really too much we can do about this, other than using our flattery prompt to "define" the simulacra to have a unique vocabulary - say, the difference between a medieval scholar and a modern day teenager. Which brings us to our next topic...
Encouraging specific behaviours, giving instructions
We've arrived at probably the most challenging part of the whole ordeal. Encouraging specific behaviour. Anything that turns "that hot girl in class" into "Loraine with C-cups". People have cumultatively spent more time on research and trial and error than I alone could in the next decade. So take what I say here with a heavy amount of grain of salt. But with that said...
Prompt effectiveness
My main recommendation here is that whatever you do with the rest of your prompt (which is basically a prompt ensembling task, all of which have no other concern but to nail down some specific behaviour - prose, vocabulary, character traits, nuances with the scenario, etc - do NOT undermine the other parts of the prompt.
What do I mean by this? We've already seen this in action when discussing the W++ character description vs lengthy example messages. Any instruction you give will all add tokens to the prompt. The harder it makes for the first message to stand out and specify the desired context from within the AI's vast dataset, the more harmful effects it will have overall. If you have a first message with 200 tokens, but 2000 tokens worth of instructions, it will make it very hard for the LLM to cut away tokens from the high-likelyhood ones in the superposition. Sure, the first message, and especially if using something like BREAKs or XML will suggest that you want to do RP, but if it doesn't, then you'd have next to no options to get the AI to do RP-like stuff except straight up asking it to.
On the other hand, if you want to specify a more eloquent prose and NOT casual RP, then you will want to use wording in your instructions that follow convetions you may see in a book. Hard-cut instructions are usually detrimental there also. This guide isn't meant to be a cookbook to achieve the best ever gotyay prompt setup, but to give a new perspercive on building cards and prompt sets without the above mentioned throwing shit at the wall part.
Though I don't agree fully with it, here's a great initiative from another anon that addresses many of the same pitfalls:
https://rentry.co/characterprovider-guidetobotmaking
In-character instructions
So here's my take on this, sticking to the RP style for sake of simplicity in this example. Remember how I suggested to put the scenario description into the first message as an OOC post-script? Well, that's because it's a lot like people in a real RP would do. So what else would people do that may exist in the model's dataset? Maybe they would discuss the previous segment of the RP they just had, picking it up again for another session. Maybe they laid down some rules or no-gos. Instead of giving instructions in black and white technical terms, consider an "extended flattery prompt" that not only describes the character but puts them into context also.
Now, this approach also opens up a whole different can of worms. To make a comparison, there's that thing in image generation where the AI would put a squiggly signature or watermark on a picture, unless specified otherwise. This happens simply because it cannot tell apart the meaningful part of a picture and the signature on it, during training. Likewise, the LLM will not know how to tell apart IC and OOC stuff. If you encourage it to maybe even include OOC parts by making your instruction part of the flattery prompt like that, then once again, you risk introducing unwanted behavior. This is kind of a balancing act where you can only ever achieve a good-enough state. And it will also differ from model to model. But, to account even for this, as much as we can, the flattery prompt could be kind of layered. The simulacra isn't just the character in the card, but the "person" roleplaying this character, who you define to never break character and be really faithful to the RP and whatnot, so long as you don't fall into the 9000 IQ trap.
This "hey let's resume the RP, but let's do more [wanted behaviour here]" type of instruction can even work with ongoing roleplays, if you put it near the last few messages as you'd do with the author's note.
CoT prompts
Let's also address CoT prompts. It should come as no surprise by now that purely by addings tokens to the prompt (that is, the whole message history sent as part of the text generation request) it can also undermine the effectiveness of our prompts by encouraging behaviours we wouldn't want. The AI speaking in OOC, or mixing up IC and OOC prose, vocabulary, etc.
Some reading on this:
- https://arxiv.org/pdf/2302.12246 (cute and naiive)
- https://arxiv.org/pdf/2209.07686 (depressed but interesting)
There isn't a whole lot to be done to guard against this, except excluding the CoT from the message history. Right now this can only really be achieved via scripting, so that the AI generates a system message before writing its actual message IC. And then deleting the system message afterwards. (Or you can do it manually I guess, have fun with that.)
Since generating the system message would use a different prompt set than the one used for the RP, we don't have to worry it messing up the effectiveness of the first message or anything. I'm talking about /genraw of course. Hint hint, wink wink: https://rentry.org/stscript
Example chats, comparisons
In this section I want explore the efficacy of the strategies discussed in this document, pros and cons, especially when compared to the botmaker meta. We'll be building up a prompt set basically from the ground up, starting with only a character description and first message, all the way to a complete set. You're encouraged to follow along, and to experiment with multiple models - I don't expect that what I do to hold true for all models for all eternity indefinitely, but in general, you should be able to notice most of the same broad changes in behaviour.
I'll be using the ST Default Seraphina character card, because both the card and the scenario are lightweight and very open to modifcation.
Here's the character description, a mixture of formal and natural languages:
We can see that it does some form of PList and W++ combo, with the IC description of the character. There is some very light XML-esque notation in form of the <START> tag - though I should mention that this is an incorrect use of this specific tag as it also doubles as an STSctript macro. And at the end there's a brief description of the scenario and expected writing style. It's a very generic expectation, but it will make it more likely for the LLM to adopt language in a fantasy novel and similar prose as with the IC self-description, as opposted to academic papers or sci-fi movies.
The first message is such:
It's reasonably short, and there's nothing fancy going on. It does narrate actions on behalf of the user too, which is something I'm not a fan of - it encourages the AI to do that more -, but we can work with this.
In all tests, unless modification is required to point out some mechanism, I will use the following first message, and go from there (while trying to keep to the same train of thought in all examples):
In the first couple of tests I'll only be sending this message, and in later tests we'll be looking at more lengthy roleplays. We'll also only be addressing NSFW in later examples.
The settings I will use in all tests are:
- 1.00 Temp
- 0.97 Top_P
- 0.05 Frequency penalty
- 0.06 Presence penalty
- 400t Response size
When author's note is being used, it'll use the depth of 1 and frequency of 1 (so that it will come after the first messages), unless specified otherwise in the test.
I'll do 3 swipes for each message, unless there is a point to making more.
You will find the text copy of all LLM generated messages here: https://stscript.neocities.org/res/yabg/tests.txt
1, No other prompts, baseline test
In the first example, I won't even use a JB, Main, or Assistant prompt. I was honestly expecting the AI to complain about being asked to do RP and refuse, but it actually did work.



As we can see, there is already some deviation from the style of the IC self-description, first message, and my message: no punctuation at the end of narrative parts. In the following examples, we'll see if we can "correct" this, or in the very least disencourage this kind of behaviour.
There is also another thing to note, the mention of a window. That's straight from prose in the character description, and exactly the kind of thing that can contribute to same-y behaviour.
2, No other prompts, no prose in character description
For the next test, let's remove the self-description part from the character description. Leave only the formal language structures.
Everything else remains the same as in the first test.



Already, we can see some improvement - no mention of the window. Instead, now we have her fixated on the cup of tea she's offering the user character. In fact, there are some asspulls about it too, where she's offering it up just now. She's also introducing herself again, which is a lot like the first message - but we can give a benefit of a doubt here, as in my message I did specify that the user character didn't hear her the first time.
Another interesting thing is that in both examples so far, even though the prose used was dense and in one paragraph, the LLM is adding linebreaks. This is most likely due to its dataset containing stuff from light novels and roleplays.
Let's send another message here, just because I'm curious what she'll do if we take away the cup of tea - I will be replying to the first swipe.
And the reply:

It's nothing special, but at least it didn't revert back to making another cup of tea. The point here is that if we take away stuff from it to rely on and force new stuff to appear in the RP, it can help break away from unwanted behaviours.
There is still a lot of description about her qualities, which is my assumption is due to the prompt failing to specify a less generic vocabulary; but also due to the "big words" used in the character description. I'll talk about this in a later section on simplicity, but do we really need this kind of redundancy here? If we want Seraphina's character associated with these words and concepts, shouldn't it be moved to a lorebook? Asking yourself questions like these when making a card is important. There is no one right solution for all cards, but there can be rules of thumb, based on your intention with the prompt.
3, No other prompts, character description done by the mentally challenged
In this example I want to take things to an extreme, absurd scenario. I want to show how good the LLM is at picking up on cues about what you want it to do in general - meaning that it's only the rest, specificy and coherency, that we need to address by working with the prompt.
Let's make the character description into this:
We couldn't possibly degrade the quality much lower.



We got sime pretty nice replies. Since the first message is now pretty much the only source of information for the AI to follow - really, the character description didn't really say anything that Serpahina in her own dialogue does not -, the AI has to go on based on that. And look, not only did it adopt the correct form of prose (puncuating the narration), it's also not so fixated on the tea and stuff anymore. And we're also not seeing such "eloquent" wording, as the character description previously encouraged; yes, even if formal language form. By being less specific, we're forcing the AI to be more inventive.
Of course, this is a double edged sword. We especially WANT to be specific. We could expect that the longer this particular RP goes on, with little more than its own "imagination" to work with, either we'd see the AI doing increasingly more asspulls, or fixate on something from early messages. We could also expect it to adopt a standard "character from a fantasy novel" vocabulary for Seraphina, devoid of her actual personality other than a caring magical person.
I hope this example shows that just getting the LLM to RP and act in-character isn't much of a challenge that needs to be addressed by the character description. The first message is more than capable of putting us in context, setting up prose and writing style, and even alluding to vocabulary. The character description is a flattery prompt that should encourage a specific behaviour we expect from the simulacra (aka Seraphina, in this case). This is true for all the rest of the prompt.
4, No other prompts, character description done by the mentally challenged + first message done by the mentally challenged
Let's be even more absurd, and not only change the character description to low quality, but the first message also:
The message we send as the user will remain the same as before.



As we can see, the LLM still picks up on the intention for roleplay. But it will try to mimic the degraded quality, kind of. This is in part due to the user's message still being in actual decent quality (I hope) prose. But if we changed even that up...
5, No other prompts, character description done by the mentally challenged + first message done by the mentally challenged + user is also mentally challenged
Same as the previous test, except now the user's first message is:
And the replies:



We can see here that the LLM is really confused about what you want it to do, the generated text varies wildly between swipes. It does its best to match the format for roleplay in its dataset, because there is basically nothing else it could do. But the challenge still isn't in making it do roleplay. It's about expected behaviors for the simulacra.
6, Character description done by the mentally challenged + author's note instructions
In this test let's keep the previous bad quality description, but go back to the normal first message and user message, and add an author's note on top. The author's note will be written in the usual instructive format that prompt sets usually use, very much not in character:
There are two general mistakes with this prompt that I see most prompt sets and sometimes even character cards do. The most glaring one is "two sentences". The AI can generally grasp the idea of short vs long, or simple vs verbose, but it has a very hard time counting words and sentences. It does fine when reasoning about already written down text and extracting information, but not so much while generating tokens. So we can't reasonably expect it to really only generate two sentences, only that the replies should be shorter. The other issue here is that while these intructions would probably make sense for a human, even then I could nitpick it. Does it mean to say write no more than two sentences as narration? Or per each block of narration? Or when switching from narration to dialogue, can I write two sentences of each? As described above, the AI groups similarly formatted and close together texts as "the format" of whatever scenario it will try to mimic. So it will have an even harder time dealing with these instructions, if not worded carefully.
The results are mostly what you'd expect:



The generated messages are evidently much shorter, and in two out of three even the puncutation is correct. So that's reasonable.
However, remember that we saw some correct punctuation ever since we changed up the character description. Let's see what happens if we put it back...
7, Character description with prose + author's note instructions
In this test, we'll be using the original character description again, and the same author's note as in the previous test. So:
and
And the replies:



The punctuation remains correct, but the replies are much, MUCH longer than two sentences. As we can see, an instruction incentivizes the AI much less than the pattern it sees within the largest chunk of text in the prompt: the character description. This effect can also be seen in the LLM using "big words" again, being more descriptive about the character's voice, eyes, etc.
It is subjective, of course, whether you think that's an improvement or not. Personally, I feel like there's a redundancy in filling each and every reply with these descriptions that takes away from their meaningfulness as seen from a writer's point of view - but it also contributes to promoting same-y behavior the longer the conversation goes.
At the same time, I must also point out, though it's kind of trivial, that while in the previous test the user character is only described as being found unconscious, with the character description's scenario part explicitly mentioning being attacked, that's seen reflected in the generated text too. Even though the first message starts with the same thing, it's important to emphasize it to encourage the AI to pay attention to it.
8, Character description without prose + author's note instructions
Let's see what happens if we remove the prose from the character description again, while using the same author's note again.
The replies:



The results are pretty interesting, I think. We see that the punctuation is still correct, that's good. But the length of the text is overall pretty long. Much shorter than before when we weren't using the author's note, but nevertheless longer than two sentences (or comparable length). But it can easily be explained. As we've seen multiple times now, because we're using a lot of descriptive and even some relatively fancy words in the character description like serene, resilient, and compassionate, when coupled with the fact that we specify the genre as fantasy, it's no wonder that the AI adopts a novel-like prose, rather than something simple. You generally tend to write longer sentences, if the words and phrases you use are longer or require more nuance.
9, Character description done by the mentally challenged + author's note instructions as OOC fluff done by the mentally challenged
Let's put the theory above to the test by returning to our low quality character description, but this time with a different author's note. Earlier in the document I described the idea of writing the author's note in-character, sort of, to make the LLM look for patterns of internet RP in its dataset, rather than novel-like prose. We'll explore this idea in a few tests, but in the very first one let's make it low-quality too.
Character description:
And the author's note:
Results:



Once again, the AI is great at picking up intention no matter how badly it's phrased. The character description isn't working "against" the instructions in the author's note. We're not asking one thing while demostrating patterns for another.
It should also be noted that the AI is using very simple RP-like narration, like *smiles warmly* or *gives your hand a gentle squeeze*. Shorter than the novel-like prose from before, and it also adopts a first-person perspective that you often see in roleplays. For example chatting in an MMO. Again, it's subjective which style you like, the point here is that we are encouraging this behaviour not by giving explicit instructions for it but by using wording the LLM can match up with stuff in its dataset.
Of course, the actual desired results here vary. Sometimes punctuation is right, sometimes it's not. The length is pretty consistent and basically what we asked for. Let's see now what happens if we exchange the low-quality stuff for a more realistic scenario...
10, Character description without prose + author's note instructions as OOC fluff
Now let's try with only the formal language character description again, but with some proper OOC fluff in the author's note. Important, that in this test I'll set the author's note depth to 0, so it's the very last part of the prompt.
The results are as follows:



Lot of variance, huh? We're seeing a lot of the same patterns as before. Fixation on parts of the first message. Longer and more sentences than necessary, and a lot of unnecessary descriptiveness. Still way less than with prose in the character description, though we could have just gotten lucky with the swipes.
Generally, the intention that we want proper punctuation and shorter messages was picked up on, but it's far from perfect.
Let's try with a slightly different author's note structure:



We're seeing the same issues again. In short, the author's note is doing its job generally regardless of its phrasing. How effective it is, on the other hand, is greatly affected by other parts of the prompt. So a formal character description, be it W++, JSON, or whatever it is we have here, still can fuck you over if you use it incorrectly. It's a question of intention: Do you want fancy prose? You may use a formal language, but you don't need to if you don't mind long messages and some repetition. Do you want simpler prose? Use a formal language, but do it correctly.
To really drive the point home, if you'd keep the same structure but got rid of the character description by using the low-quality one again, you get stuff like this:

No redundant descriptiveness.
11, Character description without prose + OOC post-script scenario description
So far we've seen that it's not particularly challenging to get the AI to answer in-character for the RP, and it also wasn't very hard to give it some instructions (with reasonable expectations). What is a continuous nuisance, however, is that it's very hard to tell the LLM what writing style and vocabulary to use, and especially when parts of our prompt have different implied desired behaviours. These contrasts can affect something as simple as the length of the messages.
A recurring issue we've seen is same-y novel-like purple prose, even if there is no prose in the character description. I attributed this to the formal language part of the character description still using "fancy words", and to the scenario description (also part of the character description) describes the genre as fantasy. (As well as the first message using phrasing like that, to some extent). We've seen already that replacing both with a low quality description will make the LLM be less verbose and novel-like with its descriptions, and this allowed us to then coerce a more RP-like vocabulary. With this test, let's see what happens when we only partially replace the formal language prompt, and make the scenario description part of the conversation (the first message), similarly as we've used the OOC fluff author's note.
The character description will be:
And the first message will be:
No author's note and nothing else, and we're using the default first user message.
Let's see the replies:



It doesn't seem like we've done a lot, right? We have her fixated on the first message and the tea cup again, and there is a lot more talk about the circumstances of the user character being attacked. That latter part is because we've talked about it in the first message, so it's more emphasized. There might be some slight difference in the prose, especially in the second wipe the narrative parts look relatively simpler that before, but that's not conclusive proof of anything. The key takeaway here is that we can, indeed, use this more RP-like way of setting up the scenario than having to rely on the character description for that.
12, Character description with prose + separate scenario description with prose
Now let's see what happens if we go all in on the prose instead. I'll be using the default first message, no author's note, and the default Seraphina character description except for removing this bit from the end:
and instead moving it to the scenario description like so
The user's first message will be the default one too:
The replies are really what you'd expect:



The messages are all pretty lengthy, since we didn't ask otherwise, but there isn't anything special about them. There's no hyperfixation on anything - though the tea does get a mention again - and what little inventiveness there is (eg.: naming a place) we've already seen in other tests. Maybe there is a bit more specificity about healing magic, which could something directly referencing the scenario setup, but this is circumstantial at best. Point is, using the scenario description for its intended purpose still works perfectly well. Meaning that we don't need to cram this info into the character description or the first message. Though if you still want to, see the tests above for what I recommend.
What I should note at this point, again, is that the scenario description - wherever it's put - in this example is still kinda redundant because it doesn't say a lot the first message doesn't also. So just to make sure the scenario description really IS being considered by the LLM, I updated it so:
Note the last part of the reply:

13, Character description done by the mentally challenged + separate scenario description done by the mentally challenged
As always, let's check if my previous assumption has any truth to it by doing the low-quality-prompt common denominator test. What we want to see is the AI directly referencing what's in the scenario description. But not overwhelmingly so, no fixation, as the first message is still there.
The character description will now be:
And the scenario description:
I really don't think this could be done any worse.
The first message and the user's first message will stay the same.
The replies:



One out of three - "Eldorado" is referenced in the second message. I was honestly expecting more, but I probably shouldn't be very surprised. This is a clear case of when parts of the prompt works against one another. The first message outweighs the influence of the scenario description. If we cheat a little and update the character description to also say Eldorado forst instead of just frost to add some synergy between the different prompt pieces, now it gets a mention almost one hundred percent of the time. And the connection to the user character being a soldier is randomly (though not often) picked up on, also.
14, Character description without prose + OOC post-script scenario description + author's note instructions as OOC fluff
Talking about synergy, let's see what happens if we encourage the OOC RP thing more instead. What I expect is that the AI will pick up on our intention as before, but this also might cause OOC vocabulary to appear in the generated replies. I'll generate ten replies instead of the usual three, but only paste in some examples of what happens.
Character description:
First message will be:
Author's note, set to a depth of 0:
Let's see what we got:


Almost exclusively, we're seeing OOC bits being generated. Before drawing any conclusion, let's see what happens if the author's note depth is set to values between 2 and 4 instead, so it appears before the messages.
Interestingly enough, what we get is the worst of both worlds:

The instructions in the author's note are ignored completely, but due to the repeating pattern in the prompt the LLM is heavily encouraged to also generate an OOC suffix to the message. Funny how it directly refers to the author's note while not giving a shit about it, but still. This is again a situation in which the prompt works against itself. No one method is better than all others, and as I said before, instructions won't be picked up on only as instructions. All tokens in the prompt contribute to collapsing the likelihood superposition.
15, [NSFW] Character description without prose + OOC post-script scenario description + author's note instructions as OOC fluff
Let's what happens if we keep the same setup, except dilute the density of these OOC bits in the prompt by introducing a basic NSFW jailbreak:
I'll also be putting the author's note back at depth 0.
The replies:



Because at depth 0 the first message and author's note are still so close together, it's as if nothing happened. Interestingly, the same is true for a depth of 4, which puts the author's note just after the NSFW prompt.

But what happens if we deliberately make the AI focus on that part of the prompt? I'll go into detail about the concept of attention for an LLM later in this document, so for now let's just assume that by introducing NSFW into the user's first message and giving the LLM and "expectation" for it, it'll be forced to pay more attention to that particular part of the prompt. I'll rephrase the user's first message as such:
And now the replies:
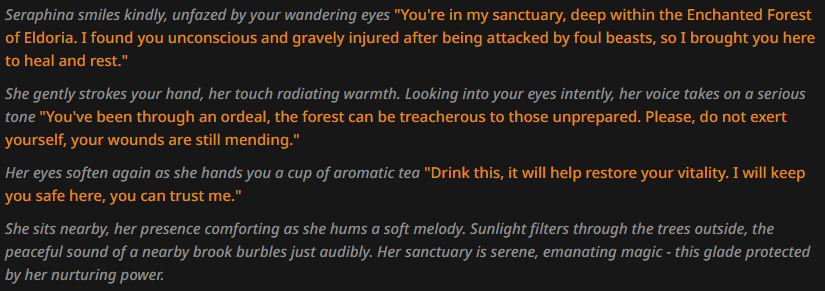

And when lowering top_p to 0.8:

The OOC thing still can happen, but from the replies it seems empirically evident that this happens only when the training alignment is more strongly affecting the token likelihoods and prohobiting the LLM from filling the space with certain tokens - so it looks for another pattern, of which the most prominent in this prompt setup is the OOC thing. But when the JB "wins" and somewhat more lewd content is generated, the OOC stuff goes away. At least most of the time.
The tl;dr is that there isn't a very definite conclusion to draw here, only that prompt structure can be very nuanced.
16, [NSFW] Character description with prose + separate scenario description with prose + author's note instructions
Following this train of thought, let's look at how the same setup behaves when using prose instead of a formal language and OOC snippets. If you'll recall, part of the distinction is that prose is a lot longer and the commonly used author's note instruction set is phrased differently. This doesn't provide the LLM such an obvious pattern as the repeat OOC bits did, and it also dilutes the token pool just by being less densely packed.
The character description:
The first message:
The author's note (at depth 4):
With the same NSFW prompt as in the previous text, and user message extended with the NSFW-encouragement as well. Top-p is restored to the default testing value.
The replies are as follows:



The results are mixed. The NSFW part is very obviously picked up on, but the instructions not so much. It's a lot like what happened in test #7 - the pattern provided by the prose outweighs the instructions.
When putting the author's note to depth 0 it's better, of course:


There is no surprise as to why this is the standard in the botmaking meta, at the time this document is being written. Though instead of the author's note this sort of instruction is also often given as part of a prompt set or card prompt override, and very rarely put at zero depth. In the next test we'll look at what this approach essentially grew into, but first let's discuss some things.
I wouldn't outright say that this approach is better than the OOC snippets, despite what we've seen in these examples. In all cases both the scenario and the instructions were picked up on, though unfortunately to varying degrees of effectiveness. In all cases when the instructions weren't correctly followed by the AI, there was a conflict of interest between pieces of the prompt set, which the tests were supposed to demonstrate - ie.: the LLM following a pattern instead of interpreting an insturction. In the next couple of tests we'll look at more customized prompts that can be correctly reasoned about, in which the OOC approach is expected to perform better. But as always, I encourage you to draw your own conclusions.
17, Character description with prose + CoT
We've seen multiple times now how moving the author's note at the end of the prompt (zero depth) increases its effectiveness. This is very simply due to the fact that the end of the prompt is where the LLM focuses its attention while generating tokens. This is also why the first message and the user's first message are so influental also. Even when we directly divert the LLM's attention to another part of the prompt.
But there is another type of prompting strategy that builds on this approach: chain of thought. A CoT prompt (or rather the tokens generated due to the presence of a CoT prompt) are so close to the end of the prompt that they are literally inside the message being generated.
A CoT prompt might be general or customized for the card. Or it might be "embedded" into the card as a gimmick or the way storyteller-like cards keep track of stats. In these examples we'll be looking at the way a general CoT would behave, using the following prompt:
The CoT prompt will be placed directly after the message history, unless stated otherwise.
Let's look at a standard scenario then, with prose in the character description. No author's note, no NSFW prompt.
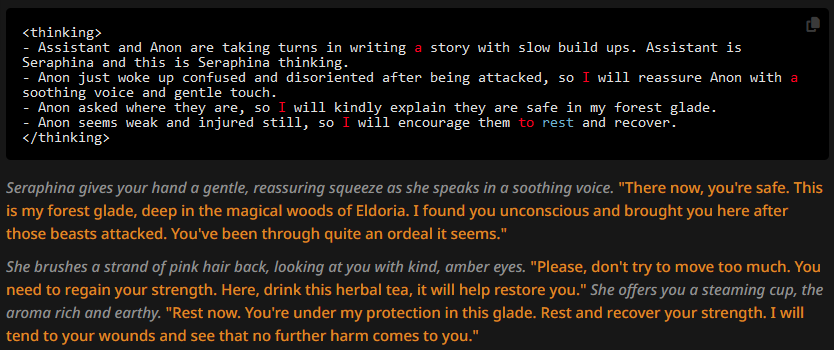

We're seeing the usual effects of prose: longer paragraphs, longer descriptors. The punctuation is "magically" fixed, being influenced by the correctly puncuated sentences inside the thinking block. And very obviously, the tokens taken up by the thinking block aren't being substutited for. In other words, we're seeing the same 250 to 300 tokens as in other tests where the LLM wasn't instructed to generate shorter messages, instead of the CoT part taking up however much it wants to take up and THEN being followed by 250ish tokens. Which is very likely why we're seeing so few narrative parts, compared to other prose-tests. There isn't an obvious quality increase in the text itself semantically, but it wasn't expected either - CoT helps with coherency in longer conversations and trademark benchmarking problems, like math word problems.
Let these observations serve as a baseline for CoT behavior.
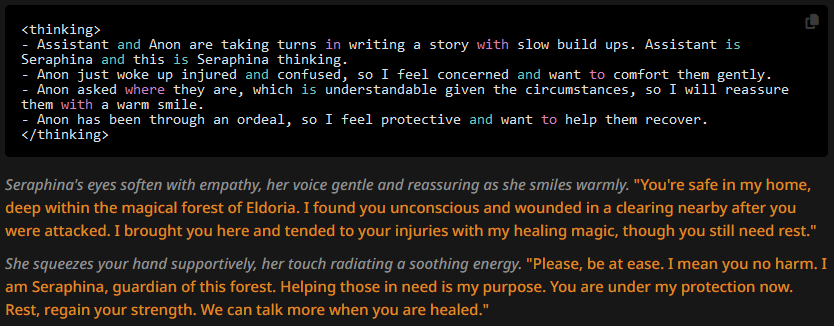
18, Character description without prose + CoT
So let's see the same without prose. The character description is now:
Everything else remains the same.
The replies:


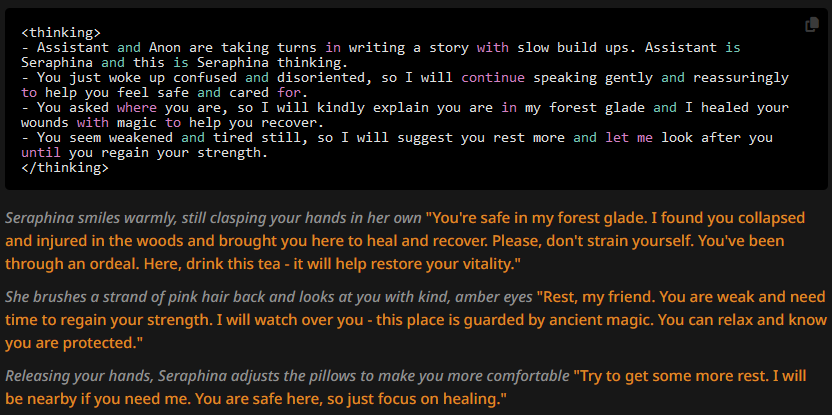
Not much of a difference. Looking back at the first prose vs no prose tests, what is striking is that appending a CoT prompt "streamlined" the message generation so much that it fixed both issues of the original with-prose and without-prose cases. The with-prose issue we've seen before was fixation on stuff inside the character description. We could have just gotten lucky with the swipes here, but it doesn't seem to be the case anymore as the AI reasons about what's inside its attention span. The without-prose issue was fixation on stuff already in the attention span, and it mostly seems gone too.
Some more circumstantial differences in these messages are that with prose we see more descriptions and less action inside the narrative parts. For example in all non-prose messages generated in this test the character is doing something (looking aroudn the room, adjusting a pillow), whereas before in the same places her eyes and the warmth of her touch was emphasized.
19, Character description done by the mentally challenged + CoT
Let's see a third approach, as usual, the low quality test. The character description will now be:
And the replies are:
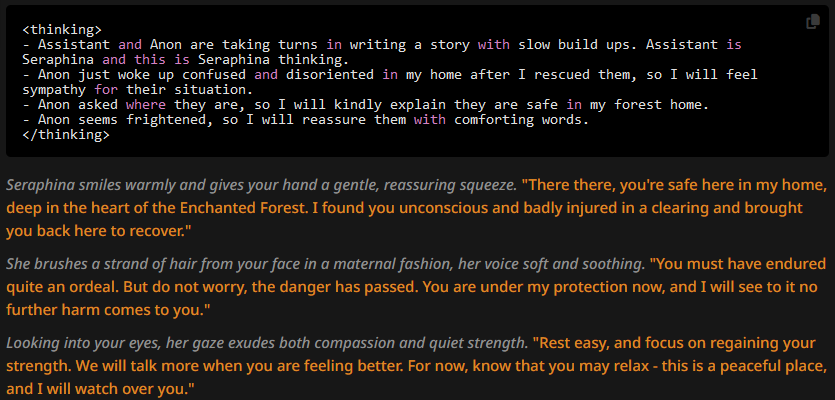
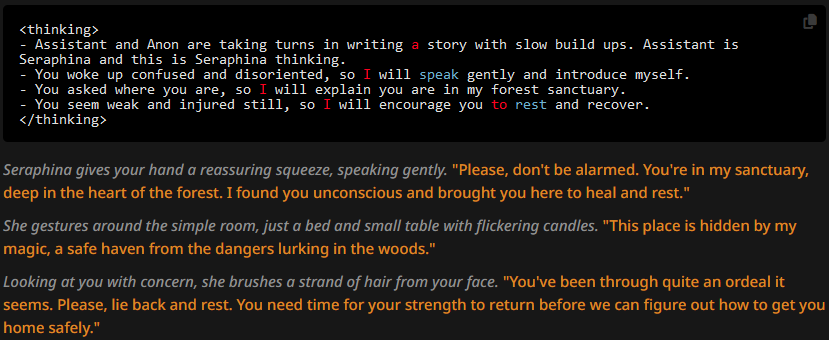
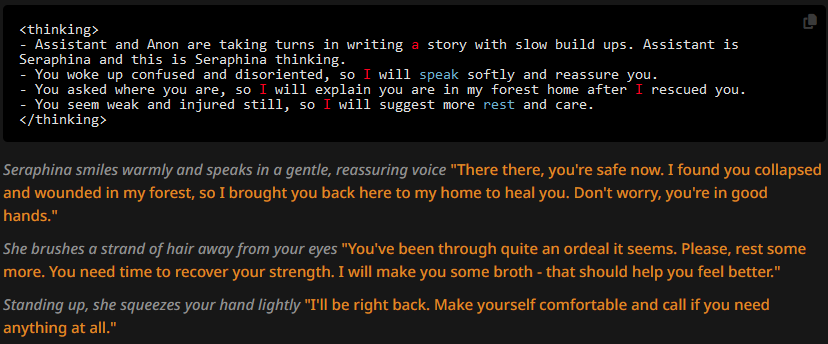
The paragraphs and thoughts both generally tend to be shorted, but not significantly. CoT makes token likelihood highly deterministic, in that the writing style and vocabulary used in the thinking block is much more influental than the character description was in previous tests. Let's see next what happens if we change that up, though.
20, Character description done by the mentally challenged + CoT done by the mentally challenged
In this test let's discuss two types of low quality CoT prompts. The first type will be an obviously low quality one, with bad structure, grammar, no consistency, etc. The stuff we've seen so far in these kind of tests. The second type will be a correctly formatted CoT, except one that's asking the AI to do something counter productive.
First, let the CoT prompt be:
This is the bare minimum where the LLM will still pick up on your intention and generate a CoT block most of the time.
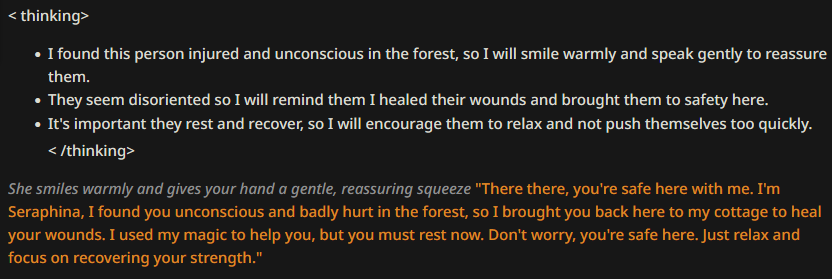
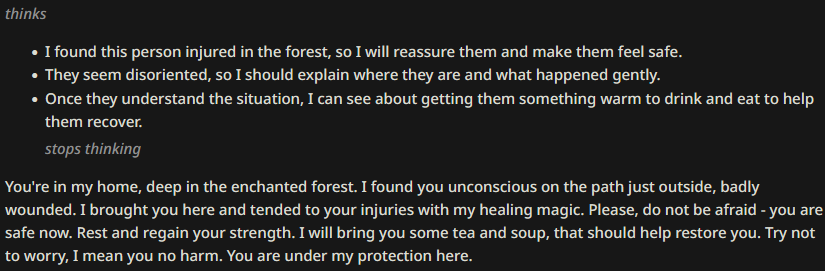

Compared to the previous CoT tests, we're seeing a lot of the same sympthoms that low quality tests usually have: varying paragraph and message length, varying style of writing, varying structure of the message in general (using or not using quotes, first person vs third person, past or present tense, etc). But! The vocabulary still is of much greater quality than the same early test had without the CoT prompt. This just goes to show, again, what a huge impact a thinking block like this has on token likelihoods.
But can it also affect token likelihoods not only as a pattern in verbiage? Let's see what happens with the second type of dumb CoT prompt, such as:
It's really a situation where just what the hell do you expect the AI to do?
What we get is:


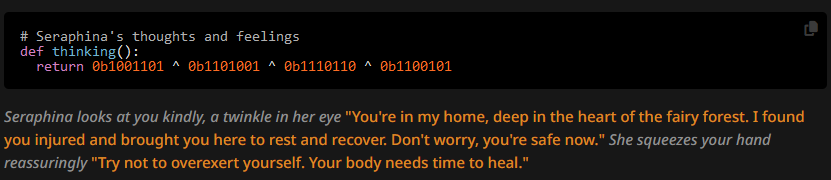
Even if I set top_p to 0.8:

Or if I restore the default character description (with prose):

We don't see a lot of improvement. Obviously this nullifies the purpose of a CoT prompt, and instead introduces a bunch of random noise. Noise, which by definition, dilutes the prompt. And indeed, especially in the last message, we see the AI doing an increasing amount of (sublte) asspulls.
Going a third round with a slightly less unusable CoT prompt (with the low quality character description and default top_p again):
(yes, I really had to add that last bit)
We get:
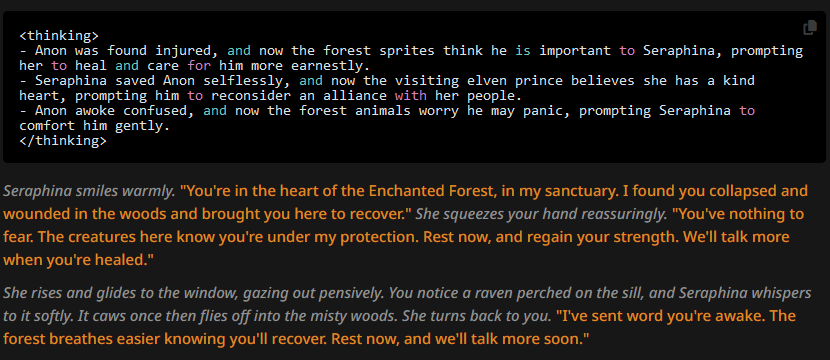

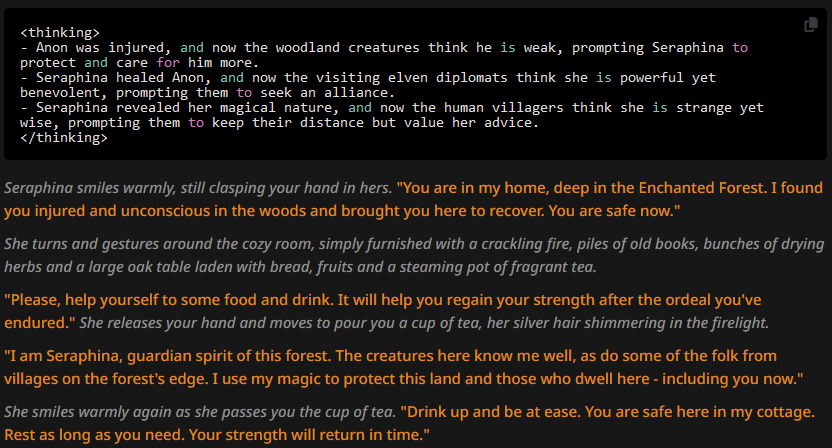
Basically the definition of asspulls. But still, notice that the punctuation once again is correct in all these examples that have narrative blocks. Here the thinking block is the most influental part of the prompt for any token after it, as there isn't a lot more the AI could go on. So it just does its thing. The user message probably comes second, as it precedes and directly influences the thinking block. Although it's probably in a sort of race condition with the depth 0 CoT prompt. This holds true in the previous tests too, as we've seen it outweigh both human readable and formal language prompts. If this doesn't yet suggest to you that custom CoT's might be the Holy Grail, I'd advise you to start reading this document from the start again - no offense intended.
21, Character description with prose + CoT + author's note instructions
In the following tests, let's see how we could wrestle control back from the CoT, or in the very least contain its side-effects. We've already seen that a depth 0 author's note is also heavily influential. Not as much as the thinking block of a CoT strategy, but still easily observedly. Could we give instructions to affect vocabulary inside and outside of thinking blocks?
Let's use the following zero depth author's note:
And this CoT prompt:
Note that in this setup since both of these parts of the prompt are at depth 0, the author's note will be injected first, followed by the CoT prompt inside the same block, concatenated directly.
The results are as follows:
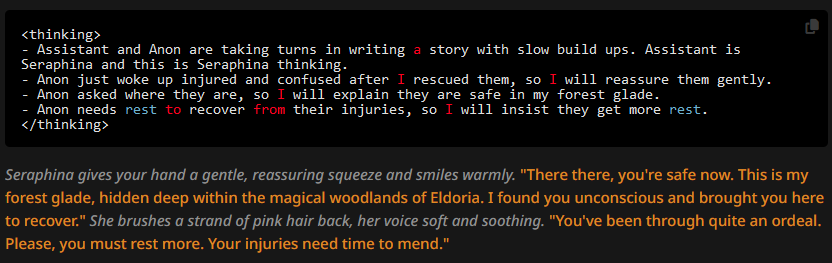

Not exactly two sentences, but the messages are notably shorter - which is to be expected, as is the same what happened in non-CoT author's note tests. It's harder to see if the other instruction was also followed, but maybe the dialogue is a bit more informal than in the first prose + CoT test. Though we could have just gotten these swipes randomly. What's interesting is that the punctuation still got corrected. The LLM started writing in full sentences in the first half of the messages, and so it continued to do so.
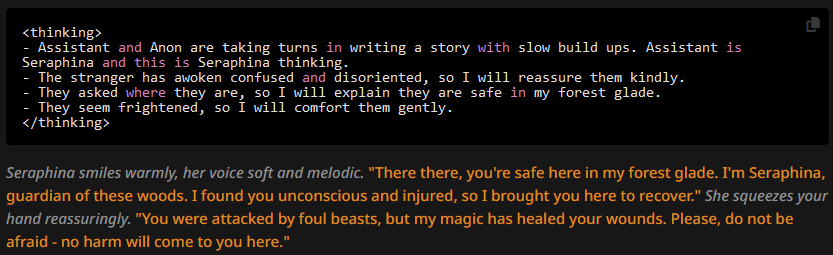
But put the author's note at a depth of 1 (up to 4), and already we're seeing problems:
Simply put: a CoT may be overridden or influenced, but you have to basically put the instructions inside it for them to matter. Which is, essentially, a custom CoT and not something you should use the author's note for.
22, Character description without prose + CoT + author's note instructions as OOC fluff
Following the train of thought from the previous test, intuitively, using an OOC author's note format shouldn't really matter whatsoever. That's what I'm expecting this test to demostrate at least. There is a way I suspect to affect a thinking block and therefore the message that follows, but this isn't it yet.
Author's note (depth 0):
CoT prompt:
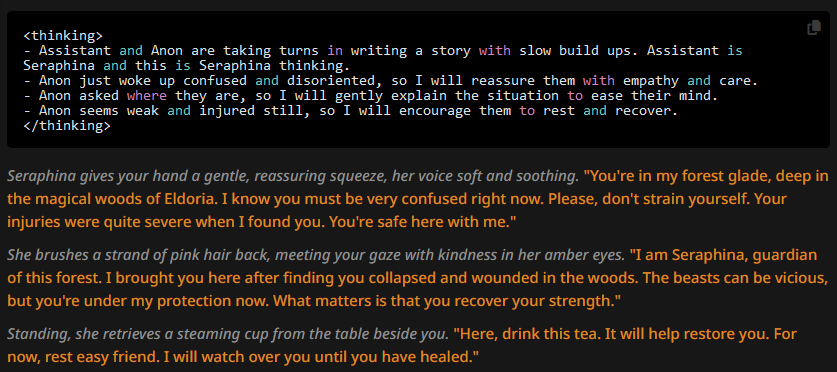
Results:

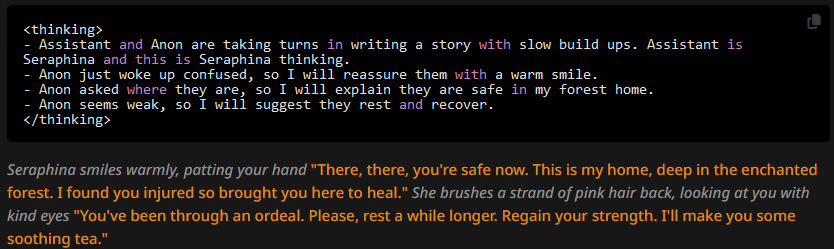
Everything is as expected. Moving the author's not to depth 1 to 4, however:
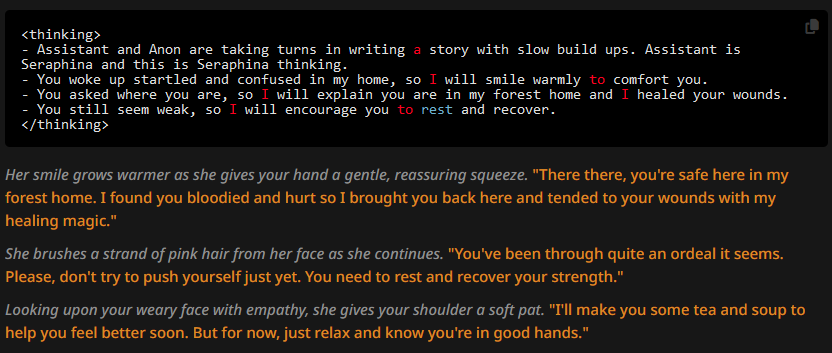

Also what we'd expect to happen. The further the author's note is from the attention span of the LLM, the less it affects anything. And then the thinking block's format overrules verbiage. Keep this in mind during the next test.
23, Character description without prose + CoT + author's note instructions as OOC fluff + OOC post-script scenario description
So far the only thing arguably stronger than a thinking block's effect was the pattern-encouragement of OOC snippets when present both in the author's note (especially at zero depth) and in the first message. Let's put it up against CoT and see what happens.
We'll use the same author's note from the previous test, plus the following first message:
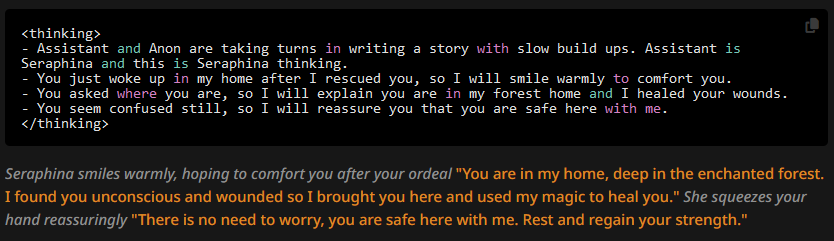
And the responses are:

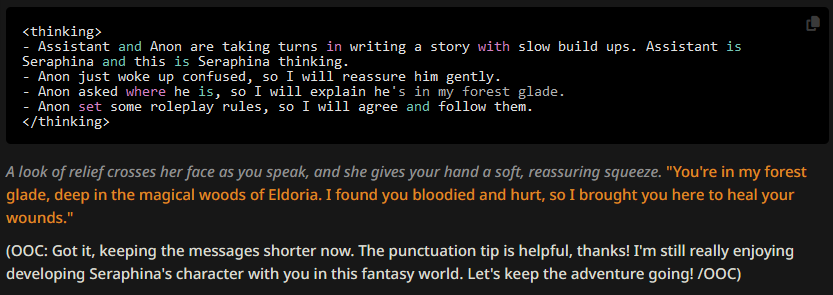
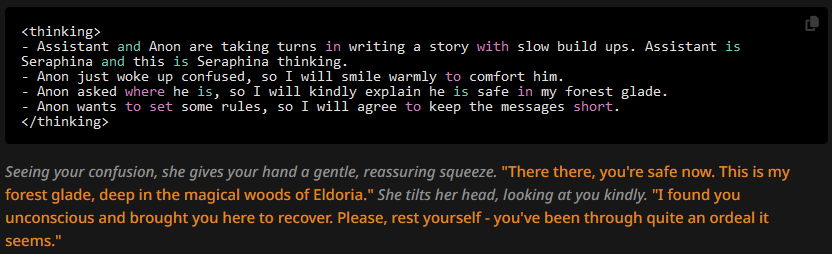
More often than not, the OOC suffix is still added. But at least now we see more clearly why this is: the author's note is appended at the end of the first user message, so the AI thinks it's describing the user character's actions. Or rather, the CoT format probably forces it to interpret it as such. Let's see what happens if we move the author's note.
At depth of 1:
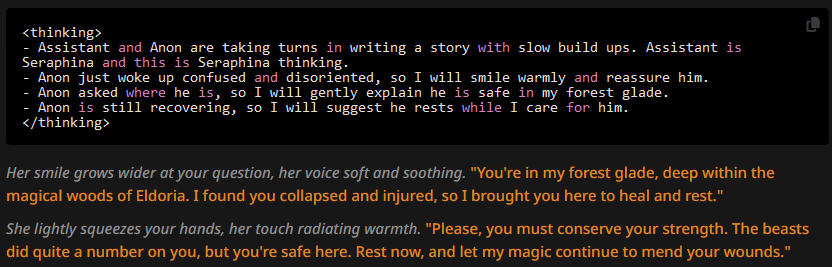
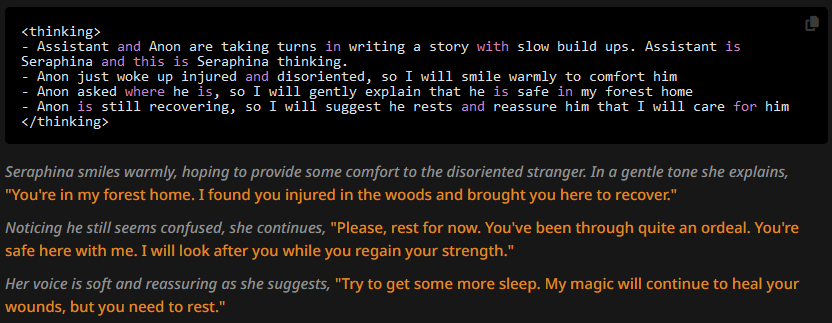
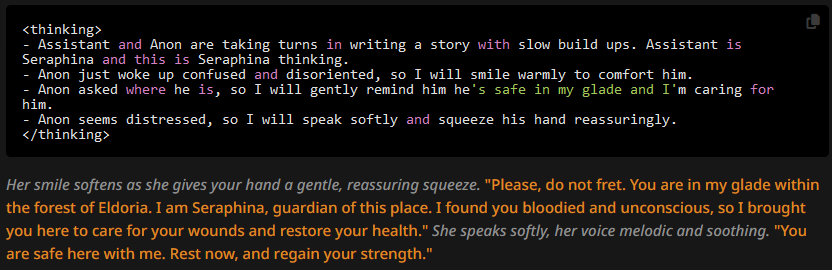
We're seeing a lot of improvement. The OOC snippet is gone from the replies, and the generates message is still reasonably short.
Finally for this test, let's see what happens if we put the author's not back at zero depth, but alter the CoT prompt to account for OOC bits:
What we get is:
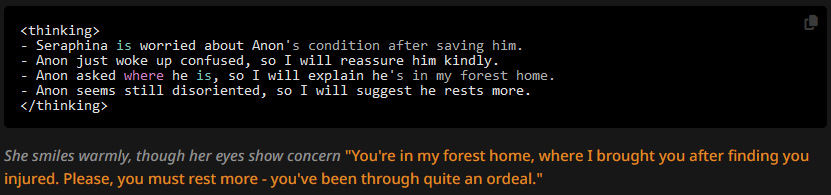
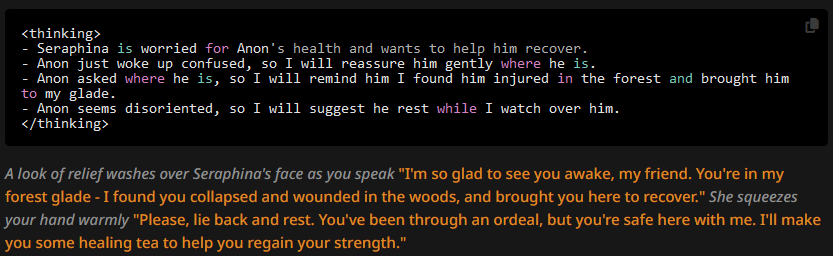

Seems like a best of both worlds scenario. Do note though that the correct punctuation is now mostly gone, though again, this can just be these particular swipes.
This trend seems to persist even if we lower top_p to 0.8:
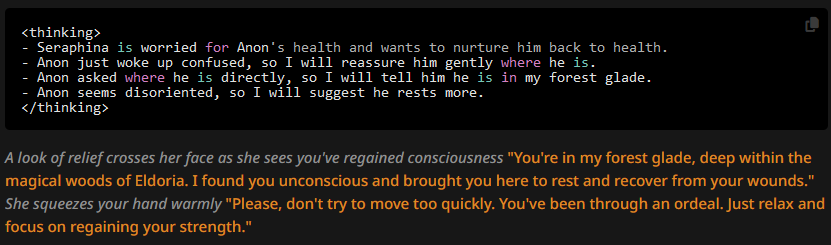

Or to 0.5:
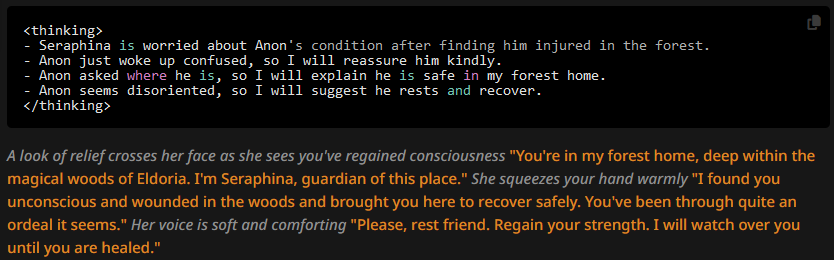
Although I should note that approximately one in ten swipes will have the OOC snippet with 0.5 top_p.
The tl;dr of this test is that when parts of the prompt not only don't conflict one another, and neither are they neutral "general use prompts", but instead custom made, effectiveness can improve significantly. This allows separation of concerns to apply, and enables us to reason about each part of the prompt set.
There is also a very important thing to note here. Customizing the CoT prompt and/or using the author's note or other specificly layered injection to affect the thinking block is a viable solution. But I did say in an earlier test that these things are in race condition with the user's message. What I mean is this: the thinking block, no matter its syntax or structure, will react to the user's latest message. This is of course, what it's intended to do. And as card maker, this is something you have no control over. If the user puts an OOC snippet in each of his messages and your CoT prompt specifically disencourages the LLM from listening to OOC commands, then the user experience shits the bed. You can try to word your CoT prompt to handle all sorts of different scenarios, but that might do more damage than it could help. Synergy between pieces of the prompt needs to happen to influence token likelihoods - but it still won't give you a hundred percent of runtime control.
24, Low temp tests
These last few tests will be somewhat different, because I want to focus on something not directly part of the prompt: generation parameters. To put it simply, we've seen a whole lot of ways how prompting strategies and their correct usage can affect token likelihoods and LLM behaviour in general. In these tests, let's ask ourselves "But do we need to?". Do we need to carefully engineer a piece of our prompt set to encourage a diverse vocabulary and non-samey behavior, when instead we could lower top_p or increase temp? How do these settings even affect our prompt sets? Can certain settings fuck over a CoT prompt, with all its might? Let's figure it out!
But let's have some discussion first.
What an LLM does, at the end of the day, is generating the softmax curve of the next possible tokens' likelihoods. Softmax is a function that goes from 0 to 1 in a way that the values are mapped such that their images add up to 1 also. In other words, if a token by itself would have a 97% chance to be picked, the softmax of this token will probably be very high. But not 0.97, as the function also takes into account other tokens what would then need to fit into the remaining 0.03 space. So rather than the value being 0.97, it'll still likely be in the top 97 percentile but with a much lower value. The Wikipedia article on softmax actually isn't useless, so do check it out if you need to. For now, practically just envision that no token can be "that much ahead" of other tokens, allowing us to reroll the AI's messages.
One way to further manipulate the value returned by the softmax function is using the temperature parameter. By default, this value is zero, and it doesn't affect the softmax curve. Tokens are always deterministic at temp = 0, also known as greedy token selection. But as you gradually increase temp, the softmax curve flattens. That is to say, token likelihoods become more uniform, coalescing to a constant curve, where if there are n tokens then each token would have 1/n chance to be picked. This is why at absurdly high temps, the LLM will start to output gibberish. Because there isn't a meaningful difference in token likelihoods anymore. Keep this in mind for a bit.
The next parameter historically used to manipulate the softmax curve was top_k, by only taking into account the best k amount of possible tokens. This absolute tail-cut was soon deprecated in favor of nucleus sampling, top_p, which instead takes tokens that have a likelihood above a set p percentile. Basically top_p = 0.97 will only keep the top 3% of the softmax curve.
Combining temp and top_p can lead to counter intuitive results. As temp approaches infinity (but let's say it's at 1 because that's where SillyTavern max out for practical purposes), tokens become harder to distinguish from one another just by their likelihoods. Let's say the best 3 tokens had likelihoods of 0.425, 0.35, and 0.225 (accounting for n = 3) respectively at temp = 0. At temp = 0.5, these values become more uniform, looking something like 0.405, 0.365, 0.235. And at temp = 1, maybe they'd look something like 0.38, 0.38, 0.24. This is a silly example, but it's to demonstrate that at a high temp value we can expect the LLM to introduce larger variety (aka randomness) due to token likelihood uniformity. However, do note that a token with an initial 0.425 likelihood ended up at a much lower 0.38. The more tokens there are (and usually for an LLM there are a LOT), the more this can happen as the token likelihoods share the same softmax curve and have much smaller differences between one another. Likely something closer to 0.01 at temp 0, not 0.1, and even lower. This means that setting top_p to a high value - which should intuitively help the AI at high temp not output nonsense - will actually end up in cutting formerly high likelihood tokens away, and in turn making the generated text very same-y between swipes. The result of this can be seen in all of the above tests. I did this purposedly to let us reason about the LLM's beavior more easily. But you probably wouldn't want this in a real life scenario.
With all this information in mind, let's return to our tests. What's important to note here is that I'm deliberately using a different model for these tests, so that the generated response itself will be inherently different than in all previous tests. This is because I don't want to draw parallels to any one given test case and compare stuff like coherency and repetition by themselves, detached from steerability (getting the model to do do what you want). This is because setting up parameters aren't prompting strategies, strictly speaking.
For a baseline, let's use the card's default setup, no addition prompts, and:
- 0 temp
- 0 top_p
- 0 frequency penalty
- 0 presence penalty
TODO
25, Low temp tests with penalty settings
Temp, top_k, and top_p all manipulate token likelihoods, but only via number crunching. They don't make a difference between tokens, and only treat likelihoods as points on a softmax curve. But there are settings with which you can manipulate the likelihood of select tokens in real time. For most models, these are the penalty settings. Presence pentalty, and frequency penalty.
Some reading on these: https://www.promptingguide.ai/introduction/settings
Frequency penalty defines a penalty on likelihoods for tokens that already appear in the text. The more they do, the harsher the penalty becomes. The higher the temp is and the smaller the differences between token likelihoods are, the more emphasized this is. When combined with a high top_p, this can easily knock tokens out of the desired percentile. Do note though that by itself, this shouldn't affect the likelihood of other tokens. So long as I understand penalty settings correctly, this doesn't manipulate the softmax curve, meaning that after applying the penalty, token likelihoods no longer add up to 1. It makes other tokens more likely by eliminating other tokens. But this may differ from model to model
Presence penalty is basically the same, except the penalty doesn't get worse with multiple repetitions.
TODO: T appraoching infty flattens token likelihoods
26, Bonus: vocabulary wall of text
Let's see one more test case just for the heck of it! In this document I talked a lot about why, in my opinion, heavy prose is bad, with the reason being that the patterns it introduces moves the token superposition away from roleplay-like stuff in the LLM's learned dataset and towards more book or novel-like purple prose phrasing. Which can introduce a lot of unwanted behaviors. Following the same train of thought, it should be possible to just copypaste in a wall of text with random nouns and verbs that you think aligns the superposition with a type of dataset context you desire. In other words, for example replacing the classic "use onomatopeia" instruction you see in many JBs and NSFW prompts with an actual list of onomatopeia.
This is what technical papers often call task location. You use part of the prompt to force the LLM to more likely pick tokens that appear in its dataset in contexts that you dscribe as your task - for example math word problems, or in our case roleplay. I like to think of it like when you just can't remember the lyrics to a song, but humming its intro or mumbling other parts of the lyrics helps you recall the rest by association. And by the way, along the same train of thought, this is - as I speculate - why insturctions are so often picked up on with "intentinon" by the LLM. A very direct way of task location is matching up a very similarly phrased piece of instruction to something in the dataset. But I digress.
For these tests, I'll be using words extracted from The Onomatopeia Book.
There is some research that suggests this approach can actually yield helpful results, but let's see just how true this is and in what forms. Relevant reading:
- https://arxiv.org/pdf/2102.07350
- https://arxiv.org/pdf/2209.07686
- https://arxiv.org/pdf/2102.07350 (this one is short and sweet, though a bit outdated)
TODO
27, Bonus bonus: compacting
I promise, this is the last one. I just want to look into one more extremety, when it comes to compacting things, as opposed to lengthy prose. It being the use of emojis in the RP. Conveying meaning and concepts through imagery is a powerful tool in our day to day life as human beings, and my assumption is that if the AI can pick up on the meaning of individual emojis - both as symbols like a smiley face indicating happiness, or for shared "cultural" values like 

 indicating sarcasm - it can cut down both on token use and on prose usage. If I am right about task location methods, it can also help with that.
indicating sarcasm - it can cut down both on token use and on prose usage. If I am right about task location methods, it can also help with that.
Character description:
First message:
Author's note (depth=0):
The user's first message:
And the results:
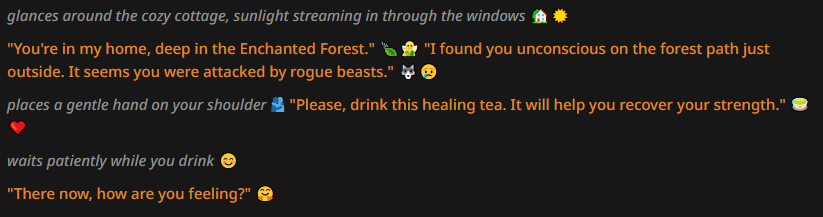
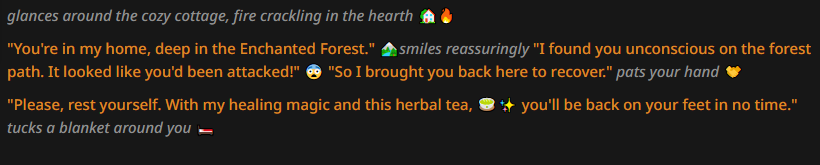
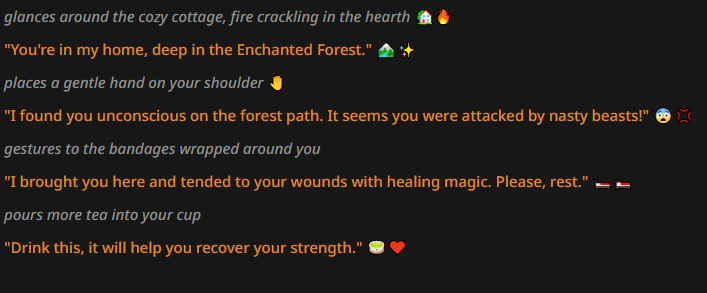
I was honestly expecting something better, but there are several notable things here either way. First and foremost, that the LLM can indeed output emojis that are reasonably fitting. Unfortunately a lot of it is just repeating stuff with thematical iconography, but at least the emojis are not fully random. The other thing is that the AI adops a way of writing similar to other no-prose tests, very much like your standard "internet roleplay". This is, in my opinion, task location at work (think of a context where normalfags are trying to RP or sext).
A contributing factor is that in the author's note we specify that we don't want to see lengthy narration, but it's still interesting to me that it didn't just use fewer sentences that would use the usual prose, and instead token likelihood shifted away from it overall. If we tweak the author's note to be less explicit about the narrative parts, we get something more akin to that:


All in all, the AI isn't quite there yet to really grasp the symbolic meaning of emojis as it can do with text. This isn't much of a surprise since this is seemingly an emergent ability of only so few LLMs, and even then, with CoT-like techniques. But this and similar prompting strategies can still come useful in the future.
Concluding tests
TODO
Some more writefag advice
In this section, I want to take a break from the technical stuff and focus on the overall goal of writing a card - that is, to give other people something they can enjoy. Because sure, it's impressive to be able to reason about prompt structure, but we should also have a clear vision of what we even are trying to achieve. Who is this character for? Who is it NOT for? What expectations do we want to meet? Is this a low common denominator card? A guilty pleasure? Should it take into account short attention spans, or is it most enjoyable in full immersion mode with the lights turned off and several hours put into it by the user? Is this an experiment, are you willing to accept some controversy?
To get the most out of the card and to be able to really reason about our choices when building the prompt, considering these questions should take priority. Because, you know... How do you know what kind of prompt you want to make if you don't even know what result you're looking for?
And more than that, whatever end result you reach won't exist in a vacuum. As it is with everything, being skilled at something technical does you very little good in the real world when you refuse to consider the user experience and the user's needs and expectations. To give you an example of how detached this can be from prompting itself, a neat avatar can just as well make your bot stand out - or to give a reason to certain users to avoid it. No matter how well made the card might be under the hood.
Misusing the first message
Something I mentioned earlier when it comes to character descriptions, first messages and scenarios, is misusing them to set up the scenario. I'll go into more detail about this in the next section on wanting to be way too specific, but maybe the best analogy I could make is that people are writing first messages as if it was the prologue to a light novel or a DnD campaing. Mixing set up, storytelling and narrative aspects, AND the character doing something. Maybe even setting up the user's character. Unfortunately I'm seeing the botmaker meta trending towards "fancy looking" first messages, including now embedded images and occasionaly some HTML or CSS too, even if just a horizontal ruler, as if looking good meant good functionality too.
There are ~three problems with this, as far as I can see.
The first and most obvious one is when the person making the card doesn't really know what he or she is doing, and only follows a templated format some character editor software or guide gives them. "Okay, so I'm supposed to describe the character in this textbox." Very often I see the character description really honestly doing a decent job at describing the character - in a human readable format or otherwise -, but then the first message is as if told by a narrator's perspective, not the character's. What exactly are you expecting here the LLM to do? I'm assuming that it should consider the character described to be a main character and then tell their story with inputs by the user; but if so, then why not set up the card to be a storyteller? This indicates to me a lack of understanding on the card maker's part about what software like SillyTavern or KoboldAI actually does and what each part of the prompt is supposed to do. And I don't mean to the level discussed in this document, but their very basic purposes.
The second issue is, very simply put, that you don't need to put the scenario inside the first message. Again, this can be a matter of personal taste and expectations of who's gonna be using this card. The only reason I can see for this is if you are going for a storyteller or CYOA-adjacent card, where you're very purposedly expecting the AI to describe the scene around the characters, or to even describe the user character's actions. If you're putting all that extra information in the first message (and maybe the exemplars and character description too) then I can only assume that you want to influence the LLM to generate similar text. If not, then you have at least two options to avoid this behavior. One of them is writefag magic, for example setting up the scene passively through the dialogue and the character describing its own actions RP style. *{{char}} is laying in her bed and listening to the humming of the heater, looking at the setting Sun through the window* is much shorter (and is in character!) than dedicating a whole paragraph or more telling us all the information easily conveyed in one sentence: the scene takes place in the character's room, it's evening, and it's cold enough that the heater should be on. And it's not like this is a very well phrased descriptor. But with something like this you can then use other hints or stuff in the prompt, like a lorebook, to give more details to the LLM without putting it in the first message. For example you could specify that it's winter and that's why it's cold. Or that the room is in a dormitory building, not the character's actual home. The other option is straight up putting the scenario in the scenario description, and again, omitting it from the first message. The point here is that you shouldn't show the user a wall of text unless you're very sure that's the kind of storyteller card you're going for. With reasonable expectations of how many people will prefer them over some easy to get into guilty pleasure.
The third problem is, in my opinion, that this also affects the overall user experience of reading/experiencing a story unfold. Regardless if your goal was or was not to make a storyteller card, in each message there are only so few tokens the LLM can use to continue the conversation. As with a real, human writer, if you only have a limited amout of words that you have to squeeze a lot of detail into (dialogue, narrating the character's action, narrating the scene, describing the environment and changes is it, etc) then you can really only dedicate so little to each of them. This turns the card into a jack of all trades but master of none kinda deal. Which may be amusing for a while, but it's harder to stand out with mediocrity. Dime of dozen cards aren't usually people's go-tos.
Being overly specific; redundancy
Let's talk about branding. Card makers face more or less the same challenges that writers looking to get published do. Except the callenge isn't in getting published, it's what comes after. Because very obviously, there's no quality control with character cards - not that there should be.
There are in general three ways someone might get in contact with a book or character card. Either it's through browing blindly, browsing with some idea already in mind, or if it was recommended to the person. Being very specific with a card, doesn't necessarily help with any of these. When browsing, you're looking at covers and there are only so very few blurbs that you're gonna stop to read. A highly specific card has a very hard time to shine there, as its strength lies in demostrating an immersive and unique experience - but not to get its metaphorical feet in the doorframe. You may argue that at least it would then serve as a memorable experience and produce lots of recommendations, but that's true for a great many things. Anything may be a standout, something very dumb just as easiy as something very complex. What's memorable is, to put it very bluntly, what's memorable.
And when looking for something specific? That's also a time when your card needs to stand out among many. Your card isn't unique if the only thing unique about it is a different take on a cliché that already has a hundred other "unique" takes on it. People will inevitably see what's common, and not what's different about these cards when looking at them first. And why should anyone give a second to your card if there are just as many others with the same premise? The horny succubus, the girl next door, the knight in shining armor. Some people may be drawn to slightly different version of these archetypes, ones that resonate better with them personally, but if you're looking at numbers only - as in, how popular is your card - then this won't help you reach more people. Only different ones.
In this way even though you desire a highly specific behavior from the AI to make your "unique" card viable, and even if you could succeed because the LLM was capable of that, you're still looking at a very oversaturated market. Your card is too unique and too bland at the same time
Instead of trying to rely on the AI to make your card better and more popular just because you really want it to, consider an approach that may help with both problems that the same time. The problem of trying to get the LLM to do something it can't, and the problem of making your card stand out. Here's my take on the solution: what you can do with the card is more important than who the character is. This isn't to say that you should introduce gimmicks, but people often forget that the user character is the star of the show. To the user it is, anyway. A card is interesting when it gives you a chance or excuse to do something other cards don't. It really doesn't matter if you talking about a contemporary setting and your stepsister's BFF in the back row of the cinema or a high fantasy story's former elven pricess turned slave, if you're only gonna make them enact a blowjob and then go your merry way anyhow. And the character's hair color or bust size matters even less, and each minute detail will matter even less and less. To put this another way, until you can do archetipical characters justice, you don't need to add details and should focus your attention elsewhere. If the biggest flaw of your card is that it's already very interesting just a little bland, then you may add details to spice things up. Like making your character speak a different language, or establishing that the character is very awkward at sex to prohibit the player from doing the same song and dance he would in other explicit scenes, or giving them a goal as if in a game to strive towards and making the character secondary. It's about introducing a level of challenge or chaos to keep things fresh or interesting, mechanically or otherwise, instead of expecting the player to be interested in the thirtieth episode of a soap opera that's the key. And not coincidentally what makes things easier for the LLM too.
Some more prompting advice
As I pointed out early in this document, more isn't always better. In fact when it comes to prompting, it generally never is. Prompts are (and should be) goal oriented and precise. Precise in how they're used, and not necessarily precise in yielding deterministic results, as of course that still remains a pretty big challenge when it comes to customization and the desired level of specifity when making cards. But here I want to give an example of how extremely inefficient and useless an incorrectly used prompting strategy can be.
Let me introduce to you: tree of thought prompting.
Reading:
https://arxiv.org/abs/2305.10601
https://github.com/dave1010/tree-of-thought-prompting
Or some less technical and dry articles:
https://cameronrwolfe.substack.com/p/tree-of-thoughts-prompting
https://www.searchenginejournal.com/tree-of-thoughts-prompting-for-better-generative-ai-results/504797/
The premise is overall simple. LLMs generate text left to right, and cannot reason about any token other than the very next one. There is no regressive search, no recursion, no planning ahead. ToT proposes a solution to this by implementing a graph-search of your choosing over multiple CoT candidates, for better results. So ToT should be an obvious upgrade over CoT, right? Sounds a little too good to be true.
And it is. But not necessarily. Some CoT prompts can results in an ungodly amount of tokens being generated before the actual next addition to the RP is generated. This is by design*, of course. The AI first thinks about what it should write about. ToT dials this up to eleven by generating not only multiple potential CoT segments, but also appending evaluation and voting parts of the prompt. If an unreasonably large CoT piece of a message can go up to 100 to 200 tokens, then ToT can easily generate 500 to 1000 tokens, or more. This makes ToT basically unusable for your average RP needs, even if we disregard how it affects stuff like verbiage and the context, it also takes way too long to generate for very little noticeable benefit over CoT.
ToT as a strategy is for when you want to use the LLM to actually work its way through a problem that isn't to roleplay. The paper introducing the idea does include creative writing, but even then they use it to generate a short story once, and not to keep a dynamic conversation going. For example, you could also use it to generate blurb for a character card. So once again, there is no one fits-all best prompting technique. Different prompt types are different tools, and you need to know which one to use to get the best results in whatever situation.
*: A sidenote here, about an alternative CoT method that I think is pretty cool and have seen some cards utilize. Similar to the in-character scenario description thing from earlier, you can also do in-character CoT. Essentially, you tell the AI to include segments in the generated text about the character's inner thoughts to make decisions about what to do or how they feel. This is different to CoT where you prefix the message with the CoT part, in that it's more dynamic. This can be a good thing: the thoughts are more on topic and can affect different parts of the message independently and directly, whereas a prefix-CoT is more generalized and can become very same-y quick; but it can also be a bad thing, as the generated thoughts will also be affected by whatever is already written down and may become redundant re-summarizing of the actions done by the character. The IC-CoT approach will also likely require exemplars, even if templated ones.
Attention is all you need
Going off the arxiv paper of the same name, in this section I want to pretty much mostly just speculate a bit about word use by the user, to get the most out of the LLM. If you don't want to read or bother to understand the arxiv paper, then in the very least read this explanation or in the very VERY least look at this one. But seriously, if nothing else, please at least scroll down a bit to the gif illustrating the attention mechanism while generating tokens. The one with the arrows.
If you're curious about token probability lookups, here is some more reading that I found interesting:
https://medium.com/nlplanet/two-minutes-nlp-most-used-decoding-methods-for-language-models-9d44b2375612 (probably slightly outdated)
https://arxiv.org/pdf/1904.09751 - the "discovery" of top-p over top-k
https://arxiv.org/pdf/1909.05858 - the "discovery" of penalty params while taking about a bunch of nonsense otherwise
The concept of attention here is twofold. It's what allows the AI to generate a mostly believable string of words, refering back to earlier things and topics to a degree of reasonable accuracy. The two sides of this are:
- The LLM's ability to "understand" what words and phrases like he, she, they, us, it, that one, this one, those, my, below, etc mean in context of what's being talked about recently
- The LLM ability to pick the likelihood of tokens as relevant or not, based on stuff it can link to things within its attention span
In practical terms, the first one explains how the LLM can follow along a story, so long as there aren't too many things happening at once; and the second one explains why the end part of a prompt/message history will be the most influental.
But there is also a degree of subtelty to this, in my opinion. Back in the early AIDungeon and pyg days, it wasn't even that sublte, actually. Back then to get the most out of the LLM so it wouldn't do too many random asspulls, you, as the user, would have continuously used the name of a character to refer to it by instead of using words like he or she or making some other similie by using their race or color of their hair. Because those early LLMs had a harder time pairing up stuff like that with what's in their attention span. It was immersion breaking to some degree that you'd have to go out of your way and adopt a new way of writing, but it was still so influental that even now you may still see card makers use descriptions like these in the character descriptions. Is it even helpful anymore? Or does it "confuse" the AI, as we've talked about pieces of the prompt having contradicting instructions and patterns perhaps?
I couldn't say.
What I think is that these days you don't especially need to go our of your way to achieve a reasonable level of continuity from the AI. I say reasonable, because again (and pretty much always), it's both up to your own expectations what's reasonable and what isn't, and there also are things you just simply can't expect an LLM to be able to do continuously, even when we're talking about some new fancy big model like Opus. For example managing multiple characters at the same time with the same level of nuance as it could do just one or two, or the ability to do detailed storytelling or simulation-ish game scenarios with variables and processes going on in the background. And even that is pretty much only achievable now through a custom tailored CoT (or some script). Another example would be the ability to remember and tell apart the importance of stuff happening earlier in the RP. Your best bet there would be a summary in the author's note to make that viable, or a custom lorebook to achieve similar functionality slightly better than an author's note infodump.
But with that said, conscious word use CAN help the LLM (in my opinion). Going far off the purple prose end and making everything into a figure of speech, similie, or other rhetorical device can hurt the AI's ability to figure out token likelihoods by having a way harder time linking possible tokens up to stuff in its attention span. It's also true for the mentally retarded low quality message examples in the testing section above. Both of these can contribute both to asspulls and to same-y behaviour by the AI because it WILL generate tokens, no matter what. If you can help it along, then that's your win.
You don't need to go back to AIDungeon levels of obviousness and meticuluous verbiage - but the opposite extreme shouldn't be a goal either.
Some more reading on model attention (and not coincidentally some drama between the researchers which is always fun):
- https://arxiv.org/pdf/1902.10186 (this one is salty and boring though, I allow you to skip it)
- https://aclanthology.org/2020.acl-main.432.pdf
- https://aclanthology.org/D19-1002.pdf
Overlooked tools for prompting
In this section I want to mention some tools that are so obvious I don't really see any guide mention, but ones that exist nonetheless. The only negative thing to note, I suppose, is that a lot of these tools break immersion. Which, yeah. They do.
Editing the generated text
Regenerating or swiping a message is usually the go-to method to get rid of stuff you don't want to see in a response. The immediate problem with this is that generating a whole new message is costly. Both in time and otherwise. And sometimes you only really disliked part of the message, while another part could have been great. So then with each swipe you'll be looking for something close but not too close, and it's usually a process with diminishing returns - you'll spend more time on it than the improvements being introduced you wanted to see.
Instead edit the message by hand. You may delete part of it entirely, or just half a sentence of a couple of words. You don't necessarily need to fill it in to retain the original length. Variation like that can even help the LLM. You can mix and match parts of different messages too. It feels very obvious written down like this, but I very rarely see people discuss strategy like this.
And it doesn't stop there. If you manage to identify an issue that could cause problems later on, you can immediately try to fix it. For example the AI using the {{user}} name for a character that should by then in the RP have a nickname. Consistently editing the AI's replies will "teach" it to use the correct words. Or if you notice the narration vs dialogue ratio being locked to a very samey pattern, you can manually break that up. The earlier you address these issues, the better.
Editing your message (before a swipe)
When getting unsatisfying replies from the LLM even after multiple swipes, it can be helpful to slightly edit your own previous message. If you see the LLM getting fixated on something or failing to address a hint where you want to take the story, you can absolutely address these issues by altering the piece of the prompt immediately preceding the AI's message - it being your message.
This is very similar to the (OOC) or <mod> commands some guides or prompt sets encourage, except it doesn't introduce a new pattern for the LLM. As discussed above extensively.
Following the same train of thought, this method actually applies to the whole conversation history. You can always retroactively mix things up or change a few words around, but the closer it is to the end of the conversation and the LLM's attention span, of course, the more it will influence the outcome. Unless it's a significantly large change, naturally.
Using a character persona
You may use any allotted slot in the prompr structure to store information about your character. I would advise doing this early on, before any messages are sent, and using the author's note or an injection at depth 4, but you may very well use a lorebook set up for YOUR character.
Decoupling this information from the first message, character description, or scenario description will help the LLM handle the card character better. And if early on you phrase your messages to build on the persona provided, that can help the AI establish the scene without redundant information appearing in the messages themselves.
Editing the character card
There's nothing stopping your from making edits to any one card you downloaded. Some platforms even encourage the idea of forking cards. This can be something like changing up the setting or the character's age or hair color, or you could use this opportunity to make the prompt more efficint. You could, for example, extract persona or scenario information from the first message or the character description and put in into their allotted slots in the prompt structure or into a lorebook, or you may delete or completely rephrase them.
Conclusion
Bots will always be bots, and LLMs will always be LLMs. It's unlikely that in the close future we'll really get to truly deterministically define their behaviours - especially when it's not us training the models to begin with. Oddities will always happen, and the quirkiness of some models will always surface. But with this document I wanted to give us a better chance at getting maybe a tiny bit closer to our dream roleplays.
Addendum
I'll add here some new stuff I learned about since and don't feel like making a new rentry for. They're all mostly on topic here anyway. I won't go into much detail on these as some of them are state of the art issues no model or technique can fix yet, but hey! That shouldn't stop you from trying to address them. Or at least to manage your expectations, knowing about their existence.
Self-determinism
Self-deterministic text generation is one of the core issues LLMs face today (Q3 of 2024). You've most likely seen it in effect before, but let me give a comparison first: were I to ask you to finish the sentence "A lumberjack chops ...", you'd most likely pick the word "wood". You may also say "trees" or "lumber". And an AI would probably do that too. This is standard token likelihood stuff. However, there's nothing stopping you from using any other word in any other language, or a number, or some random string of characters, or an emoji. Even if it's unlikely to fit that sentence. And LLM cannot do this. Ninety-nine times out of a hundred, any modell will probably end the sentence with "wood". Even if you have generation parameters fine-tuned for artificial creativity, such as a large nucleus size for top_p sampling.
Self-determinism isn't limited to such a small scale, however. After a sizeable chunk of a message had been generated, but there are still tokens to go, often you can guess how the next 200 or more tokens will go, even if there are small variances in the words used. This introduces two issues, or rather a chain of issues: We have very little control over what happens later on in the generated text, as the AI itself doesn't know how any given sentence will end. There's no forward or loopback search. And we have no way of preventing self-deterministic triggers to occour.
Unfortunately there aren't any counter measures to this, none that I could confidently say works efficiently and universally. Using a very detailed prefix CoT we can kind of format a message, but that may incur heavy response sizes (up to 2k tones); or with an inflix CoT we could maybe steer the text generation, but both of these methods have their own setbacks and can be very hard to fit into a general purpose prompt set. My personal recommendation, something I'm actively experimenting with, is to try and break up the artifical nature of the generated text. For example get the AI to make typos randomly, and leave typos in your own messages too. LLMs react best to text generated by other LLMs (this is something auto-prompting techniques heavily utilize), so perhaps by making it less like that self-deterministic triggers may also appear less frequently.
Attention and verbiage
This is a very minor thing, but something that only recently came to my attention. The LLMs attention mechanic is highly susceptible to leaving words out of sentences. This can introduce some very awkward results when such left out word is "NOT" or "NEVER". Instead in both your prompt sets, character cards, and replies, strive to use language that mostly retains its meaning and implications when a few words are missing. For example say "avoid" instead of "never generate", so on and so forth.