Latest update
2026-04-15 - some weather-related power outages here. waiting on the electric company
2025-07-26 - for Error 1102 or "Not Found", try corpodex.app or pomu.moe or VPN
- 2024-03-26
- 2024-04-15
- 2024-04-26
- 2024-04-30 snapshot
- 2024-05-10
- 2024-05-20
- 2024-06-13
- 2024-06-20
- 2024-09-01
- 2024-09-29
- 2024-11-29
- 2024-12-18
- 2025-01-12
- 2025-01-12 snapshot
- 2025-01-21
- 2025-02-23
- 2025-03-31
- 2025-04-24
- 2025-05-02
- 2025-05-17
- 2025-05-25
- 2025-06-24
- 2025-07-05
- 2025-08-06
- 2025-08-13 snapshot
- 2025-09-05
- 2025-11-01
- 2025-12-04
- 2025-12-11
- 2026-03-10
- 2026-04-02
documentation has moved here:
https://rentry.org/tgcgce3q
2024-03-26
hey [small corpo enjoyers], I'm building a thing to find waiting rooms easier and wanted to get your feedback on it so far.
some notes:
simple view is for mobile. it's also set up so you can copypaste it
dev view is for extra info. specifically for ctrl+f
dense view puts more links on the screen. I think it gets less useful when the stream is a week out, but I like seeing the collage
link: https://pomu.pages.dev/schedule/corpo?id=dense
it's just my dev site for now, so there are some bugs and stuff might change/break without warning.
next on my list is to add a filtering system by date/group/individual.
extra context >>71842145
2024-04-15
gm, pomudex should be running again.
I'm in the process of migrating the code somewhere more resistant to 3am windows updates, so the development has slowed down a bit.
roadmap:
- QA for scripts on new machine
- display for channel listings
- form for adding additional channels
- add twitch
- edit page for channel listings
- rehaul for catching ghost waiting rooms
- more schedule displays
- domain name
2024-04-26
- got some progress on the data rework, so ghost and schedule waiting rooms will be have increased coverage when I finish updating the front-end.
- I got a request to include someone's mother (bri's mom). I've added them with the caveat that access to these "& friends" accounts may shift in the future. the plan so far is to have the corpo page for collective vtubers that have passed auditions (so including ex-corpo) and a namepending page that will include both corpo and indie friends. shortlinks will be redirected to include friends accordingly
2024-04-30 snapshot
- channels: 337 (274 active)
- waiting rooms: 548
- archive: 93,455 videos
- 0 min, 2400 max
- 190 median, 277 average
2024-05-10
- updated algorhythm project, bondlive, eufone live, m.entertainment, nawasena, oshilink, project kavvaii, project orbit, project: verses, and zenithve. thanks google form users for compiling
side note: as the list continues to grow, remember to use the filter= and hide= params as needed.
https://pomu.pages.dev/schedule/corpo?filter=Vyvid
example filter for debuts today
dev note 2025-09-18
hide= was built out for /schedule (v2, big json file) but not /s (v3, data rehaul to SQL)
please wait warmly while development work is in progress for filter, hide, pin
the current workaround is to go into select mode, deselect vtubers, and use the big URL (also redesign in progress)
2024-05-20
hello, I'm back and mostly caught up on the google form. thank you as always for submissions
- amber glow, avallum, lightmotif, project:verses, yume+, and zenithve updated
- some of them were on there, so if there are visibility issues please leave a note and I can investigate further
- usual reminder that the filter=
and hide= (see above)params are recommended. keyword reference available on the channels view - regarding nanobites, there will be a separate /phase category; idea being yes I'd like to include them but discussion seems to have migrated from /corpo. I just need to sit down and go through the list of ~30
- nyaranaika nyanyanya
- I'll be out again for offkai and late july -> most of august. updates to the list are still possible but availability to catch small corpo news and site issues will be limited
2024-06-13
- caught up on submissions! thanks as always for compiling
- added phase as their own category https://pomu.pages.dev/channels/phase+
- recent mentions of nanobites have been more in the phase threads, so I've added her there
- added a color for special event stuff like debuts, relays, and concerts. twitch: purple, youtube: red, premiere: orange, event: yellow
2024-06-20
I removed v-sea since the whole thing seems to have imploded. seeing as they never debuted, I'll add any talents back if they resurface in another org properly.
in removing them, I tripped a bunch of fail-safes and the script stopped working for a few hours. site should be refreshing again now
2024-09-01
- moe!live added
- nexas talents now reordered to match their rentry
- general cleanup, eg inumaromugi -> erifuwette, vdere gen 1 -> realm:era
- caught up on the spreadsheet, thanks as always for submissions!
currently on the radar:
- aegis-link
- nexas yume
- stellarversepro project infinity
- variance project (formerly known as digilive)
- vdere gen 2
- v4mirai gen 4
I'm finally home and stable enough to work on logging member streams!
2024-09-29
- added /wool shortcut and their own topic
- lillie is cute
- all the #RockinRelay participants should be available in the /corpo+ topic now, highlighting will be available once the playlist is up
- bilibili support is backlogged. sorry if you wanted it soon
- converting the bunch of yaml files into a proper db is in progress
- picked up a domain name for corpodex
2024-11-29
to pomudex users,
happy thanksgiving! and thank you as always for your channel submissions and site feedback. it means a lot to see people contribute to the roster and use this goofy experiment as a resource
I'm here to update that unfortunately the server went offline; not sure what happened ~18 hours ago. I've got the script running again on a temp setup for now. until I'm home next week, the data will be a little slower (every 30 minutes instead of every 10). sorry for any waiting room confusion earlier and latency while I resolve this.
2024-12-18
I didn't get around to making that status page, so I will probably add a rentry next to the documentation link.
I'm going offsite for the holidays again. Last Thanksgiving the server's internet went out, but a slower temp server was able to make waiting room updates. In case it happens again, I have it set up better so that running another instance doesn't break the original (probably).
In other news, server v3 and my database are working! I still have to hook it up to the webpage, but it will have updates every 1 minute for livestreams (no more waiting rooms lingering for 10 minutes) and you'll be able to do stuff like check the vod archive for a whole company, including twitch start/end times. Hopefully updated soon next year.
Until then, merry crimbus!
2025-01-12
- updated cloudflared
- updated the cloudflare tunnel config to use the docker container name
I pushed a UI change around 4am, and woke up to API downtime wtf.
how it works is the website will ping my server for the full URL, and if the server is down it's supposed to fallback to some default value. some IP reference expired, so cloudflare couldn't ping my server, and the fallback process didn't account for the error code. boring technical stuff, but big picture I think the website is becoming less duct tape and more solid.
also for reference, here's the current design, including server v3.
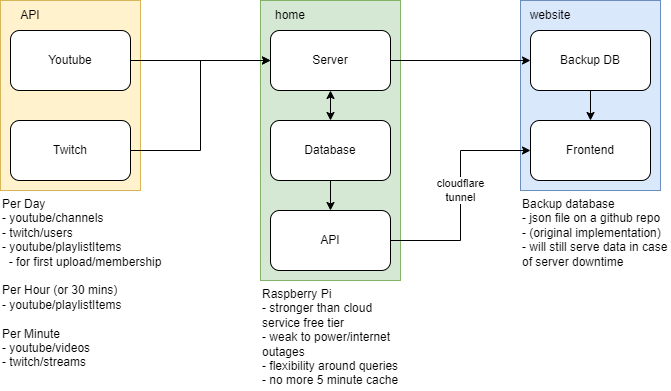
as of v2, all the data (livestreams, channels, associations) lives in the backup DB. migrating everything into the v3 formal database is a big task. I want to clean up the original rentry article with full commentary some time.
predicably, holding a website together with duct tape has its limits. github's 5 minute cache gets annoying, and when I had to pull the repo over thanksgiving, it was 1.5GB of disk for 50MB of json files because it's 36k commits. the way I set up my data was also bad. corpos have gens or members, gens have members, and members can be in multiple groups; the bandaid solution was to have 5 CHIkafuji LIsas.
2025-01-12 snapshot
- channels 897 (525 active in the last week)
- youtube 625 (382)
- twitch 272 (143)
- waiting rooms 823 (467 scheduled)
- archive 203,369
- youtube streams 157,972
- min 1
- median 184
- max 1934 (@channelkimaseri)
- youtube videos 42,949
- min 1
- median 35
- max 1137 (@AdmiralTrina)
- twitch streams 2448 (started querying Dec 2024)
- min 1
- median 12
- max 71 (miyuyus)
- youtube streams 157,972
2025-01-21
caught up on submissions, thanks as always for finding these twitch accounts.
server keeps disconnecting from the internet. I haven't changed any settings since initial setup ~8 months ago, so it's a mystery. I changed a number in the settings and it reconnected automatically. hopefully that fixes it. otherwise, I'll finally look into an ethernet connection.
in other news, I've been using the new endpoint and keep flipping back and forth between wanting to share the WIP early and finding some critical bugs. I think the youtube style thumbnail UI has reached a good stopping point. dayjob has been dramatic lately. I might be toast for a bit.
todo: get it to work for 7 days in a row, migrate all the channel associations, set up a DIY filtering system, set up an archive UI given a list of channels, and maybe funny charts like typical start times and active days for a list of channels.
2025-02-23
before I could make it home, the server reconnected again. almost exactly 24 hours of downtime like the thanksgiving episode. apparently the cause of these outages might be something called "router ip lease time"? it stays online for months at a time when I'm home, so this issue is a real PITA. my best guess is the router drops my server after 48 hours without ssh and finds it again on a daily scan. I'll get that extra ethernet cable then.
2025-03-31
pushed a few minor changes.
- error screen is more informative if there's a server error
- on the multiviewer
- if you add a video again it will show up at the end (in case you put in a twitch channel multiple times)
- test button is now share button
- now fetches youtube thumbnails from video IDs. visible in mado and dex view for a nice taste summary
- if you are a fellow 100+ thumbnail degen, this deploy will likely wipe your history sorry
- april fools
- 50% chance of short links redirecting back
- 10% chance of a random encounter
2025-04-24
I had to unplug the server and router a few times from shifting furniture around, but I think it's done!
I moved! I already had my own place before but now it's a different, cheaper, closer to family place.
what does this mean for the website? this area has a slightly higher chance of a tree falling over and killing the electricity, but I also save enough that I can look into cloud hosting for uptime. I'll also have more time to work on adding features and stuff once work either calms down or I find a new job.
the usual space isn't around so I'll post some WIPs for those who actually read this yappery (I appreciate it).
- /archive
- the main change from /channels is that you can include multiple channels, including twitch. the vision is something like /archive/<corpo name> and you can get the whole vod list of a group; it requires remapping all the associations to the new format which isn't quite done yet. for now here's an example of using url args because I haven't gotten around to making a nice UI or infographic.
- /schedule (v3)
- currently no filtering capability besides search! again dependent on finishing the channel mapping and setting up the filtering UI.
- the timings on this page are slightly different: there's a daily scan to see if memberships opened or the channel is active in the past month, then every 30 min there's a check for new waiting rooms from active channels, then every 1 minute there's a check on active waiting rooms. ideas being
- it's very rare that a vtuber comes back from a month absence without advance notice,
- the vast majority of streams start on :00 or :30, and
- checking the status of multiple streams is cheap on quota.
- once I consolidate my quota usage between the old and new system, I can tweak the numbers more or add a ton of channels too.
- there's also a youtube style card layout! I ended up falling back to the dense catalog spread for day-to-day usage, but there are definitely cases when I like to see the stream thumbnail/topic.
- https://corpodex.app/
- this is the "official" name, unassociated with any communities
- mainly because I needed a domain name for cloudflare tunnels.
- a bunch of endpoints ping my server directly
- some latency is expected because it's just a raspi in my living room instead of a globally distributed datacenter
- there is probably a way to host frequent data like waiting rooms somewhere better than github's 5 minute cache
- I have no idea what it would cost to move to cloud. it's potentially cheaper to just by some battery packs and use my phone hotspot in case of internet/electricity outage
- the old pages (/channels, /schedule) will still be available after v3 is finished
- data will eventually drift out of sync with the main system
- mainly I want to put this extra scraper quota, writing channels in two places, and bloated github repo to bed (55k commits)
- any links that point to old endpoints will be moved when things are done/stable
2025-05-02
I might have solved a long time problem very simply. users might see improvements to membership stream reporting and ended streams being cleaned out.
tl;dr I have a frequently used packet of data (waiting rooms) and github wasn't handling it in realtime or efficiently. I found out cloudflare KV can be used just as easily (maybe easier) and solves the realtime and maintainability issue.
which is a weird feeling because that was also the whole point of the rebuild that started almost 6 months ago. more details:
my first instinct was to use a github repo; it worked well as a proof-of-concept and has nice things like version history and timestamps, but the main pain points are 1) github servers only refresh every 5 minutes and 2) it's updated so often that it's reached 56k commits, making it difficult to download and work with. at the end of the day, I just needed to upload a JSON file somewhere for the website to find. it turns out that cloudflare has some databases I can use on the free tier.
I've used AWS dynamoDB before too, but I figured cloudflare would be simpler since the website is also on cloudflare (spoilers: the latency is somehow kind of shit). I took a second look at KV and it turns out there is REST API access (for curl or fetch or whatever barebones retrieving) and I don't have to install the whole worker/wrangler/whatever the heck proprietary cloudflare thing just to grab a JSON file. it does mean I have API keys floating around in places they shouldn't be, but I wasn't planning to open source the thing anyways. I like the freedom to just overhaul stuff and would hope that the blueprints and blog of issues like this are enough.
At the very least, I think the upcoming youtube-style UI, multi channel archive, and twitch tracking are value add.
UPDATE: I woke up to finding out the free plan has a limit of 1k writes per day. 1440 minutes in a day and I was writing two items, so that was short lived. also some poor soul saw 900+ ms latency. gonna stop messing with production and let these things test for a day
2025-05-17
I'm back and site should be up again.
judging by the flashing clock on my fridge, the power was out for 40 minutes. something in the config is preventing my server from docker composing properly on reboot.
lately seeing random showstopper issues like this that blow up after months of working without issue. I'll have to do maintenance this week at some less busy hour to can test the auto-reboot scenarios.
2025-05-25
pomudex v3 is deployed!
the v2 urls still work, but I won't be updating stuff regarding the channel mapping.
more details later when I have time to reach out for testers
stream pin mode - new toggle to keep non-filtered livestreams on the page
filter select mode - I got it to select the group name if enough members are selected
multichannel archive - you can use the channel, shortname, gen name, or corpo name (links provided in channel page)
2025-06-24
I thought connecting my raspi to a mobile hotspot was a neat backup plan, but apparently my data service blocks something at the DNS level. meaning outside computers can't contact the server (resolving shortlinks and filters) and the server can't reach out the APIs (latest youtube info).
the backup data I had set up kinda works, but I should really back up the filtered views. sorry again for the inconvenience during peak hours
2025-07-05
Wtf! I think there was a power surge or something. I had fixed some restart error in May but there must be more to it if its still offline.
update: something did happen with the power. gotta reset my oven clock again. raspi wasn't booting at all until I replugged the power block. not seeing a realistic code fix for something like this. damage was ~48 hours downtime and any unarchived/twitch content in that window being untracked.
a big reason I made the site was I saw dead waiting rooms on nijimado sometimes and thought I could do better. seeing the site completely go down instead while I'm hundreds of miles away bothers the hell out of me. I'm thinking of signing my soul over to some cloud hosting subscription again; barriers/requirements are redoing the code (fastapi => lambda, mariadb => rds, docker => ecs/ec2?) and monthly cost (it's easier to manage mentally when it's just running on hobby equipment). I'll do some investigating into what's the highest yielding tool to keep data more updated.
from this log I'm seeing about 8 days downtime out of 178 this year so ~95% uptime. 3 were from bad code or wifi issues (using ethernet now), 3 from electric issues while out of town, 1 from unavoidable electric maintenance, and 1 from moving.
2025-07-26 - I'm getting cloudflare Error 1102 and haven't found the root cause. vpn and corpodex.app work, so it may be a local issue. more investigation needed
2025-08-06
the much requested dark mode is now available! thank you for your patience
80% of the screen is still made of light mode profile pictures, but this should help a bit.
for general tracking, there were two other outages since last post: 1 internet outage, 1 power flicker. moving to cloud would certainly help. I just don't want to spend the money. the site will remain free for flexibility reasons. might still put a banner somewhere for announcements and silly posts.
2025-08-13 snapshot
- channels 1084 (627 active in the last week)
- youtube 717 (430)
- twitch 366 (196)
- archive 288,922
- youtube streams 266,763
- scheduled 208,044
- for this week 391
- outside this week 452
- no show 2,980
- complete 204,244
- membership 12,183
- privated 8,088
- scheduled 208,044
- youtube videos 56,384
- twitch streams 22,156
- youtube streams 266,763
I still haven't gotten around to the funny charts. channel heatmaps of active days of the week and hours of the day. frequent streamers by time frame. end of year summaries. efficiency has become a more pressing topic. I don't know what changed, but I'm seeing free tier limit errors and I don't know if it's the increased traffic or queries getting heavy. or cloudflare just trying to get me to cough up for paid tier.
the site is made of three main pieces
- the data (cron + mariadb)
- the api (fastapi + cf tunnel)
- the page (sveltekit + cf workers)
I'm about done cleaning up the data. this mostly impacts API quotas and server performance. physically it's my copy of names and timestamps. very big stack of books.
api clean up is next. maybe rehaul is the right word; looking to cache data closer to edge. this should improve site performance and hopefully gets me more reliably within the free limits. functionally it's the window into the data warehouse.
page clean up kinda happens with api work. this should help with presentation. something like the delivery guy, but it also handles backup data when the server is down.
also for reference I'll also include the mirrors in case of 1102 (page issues):
- corpodex.app (official-ish)
- pomu.pages.dev (beta test)
- dev.pomu.pages.dev (unstable but latest)
- pomu.vercel.app (suprisingly usable)
- for some reason vpn also fixes the issue (regional throttling?)
2025-09-05
small downtime while I handle an unhandled case
blog:
very weird error discovered from an uploaded video showing a different channelId than what was searched. did some digging and found out that @HACHIVSinger is now also @HACHIVSinger-KINGRECORDS.
I don't think this wrench in the engine came up during the 1.5 years the site's been live, but I did encounter this during the data rehaul with some uploads between @sakura_aoi_ch and @sakura_aoi_chan. for example, this video points to @Sakura_Aoi_ch on the channel link, but in the backend and page source the channel is @Sakura_Aoi_chan. as far as I know, these are the only two multichannels in the system but I gotta write a special case for them.
crazy that there are scenarios that won't show for years and then suddenly appear and jam the whole thing
2025-11-01
2025-11-1 - i think there was a power outage but i wont be home until evening to restart, sorry for the interruption.
I think a lot of these updates happen at the beginning of the month. I didn't keep track of the outages, but I'm wondering if the electric company just does undisclosed monthly outages. In the meantime, I've made two fixes.
- there was an error in the fallback data handling. a bad reference to some fancy vsmp logic I had copied over from live data handling. the schedule should at least fall back to the every-30-minute-backup. very limited filtering capability, but it should show old data instead of confused equine
- installed tailscale on server and phone. tried connecting from data and it looked OK. will restart the server sometime next week for a proper test. I did try today around 1AM ET but it was quite stressful and I thought I toasted my SD card with so many reboots. seemed to work so far. suggestion on jetKVM noted, but I don't wanna buy stuff.
the service to run docker compose up -d on reboot used to work but lately it doesn't. trying apt-get upgrade for the first time in 18 months. maybe that will fix more problems than I know...
apt-get update too apparently
2025-11-06 - Power went out. Normally it comes up after a second, but its been a few minutes now (。•́︿•̀。)
2025-12-04
power went out for a second. took probably 10 minutes for the router and all to fully return service.
first thursday of the month again? might not matter anymore. tailscale works and I can ssh in from wherever to refresh services.
also it's recap season, so here are some stats
online anomalies most days streamed
| channel | streams | stream_hours | stream_days |
|---|---|---|---|
| @scarleyonaguni | 428 | 2069.34 | 321 |
| @kannayanagi | 438 | 1447.70 | 313 |
| @mercurymanor* | 602 | 2131.96 | 306 |
| @stronnycuttles | 455 | 1105.49 | 292 |
| @aiaamare | 344 | 1304.57 | 287 |
| @vylettmoonheart | 333 | 1165.15 | 287 |
| @amiyaaranha | 326 | 1007.72 | 283 |
| vylettmoonheart | 370 | 1175.24 | 281 |
| @nano_kozuya | 355 | 1254.58 | 273 |
| @zandernetherbrand | 433 | 1672.24 | 273 |
| @onolumi | 302 | 1284.03 | 272 |
* The Mercury Manor is a shared channel between Gini and Peitho
it is currently Week 49 of this year, meaning there have been about 245 weekdays so far.
kudos to Scarle (Nijisanji EN) and Kanna (PixelLink, Glitch Stars) for their insane 6+ day workweeks! also take a break!
endurance exercises most 12 hour streams
| channel | streams | stream_hours | stream_days | 12hr_streams |
|---|---|---|---|---|
| clioaite | 173 | 1999.44 | 161 | 130 |
| @clioaite* | 197 | 1445.78 | 152 | 73 |
| aisaka_siu | 225 | 1698.60 | 184 | 40 |
| sayu | 218 | 1891.33 | 154 | 35 |
| shinominya | 114 | 940.12 | 103 | 17 |
| vtubermochi | 173 | 1079.92 | 147 | 17 |
| miyuyus | 425 | 1403.56 | 218 | 16 |
| batatvideogames | 78 | 580.22 | 77 | 15 |
| apollomythos | 136 | 882.57 | 113 | 15 |
| shirozevalia | 223 | 1436.86 | 214 | 15 |
| @sayusincronisity | 90 | 714.02 | 81 | 15 |
| @yunohanaki | 203 | 778.65 | 155 | 15 |
Clio Aite debuted on Youtube 2025-05-02
defined as when the stream duration is greater than 11:30:00
for a lot of these, I was able to ctrl+f "thon" and see 24h twitch streams
kudos to Clio (Phase Connect) and Siu (Specialite JP) for doing it for the love of the game!
algorithm addicts most uploads
| channel | uploads | streams | stream_hours | stream_days |
|---|---|---|---|---|
| @admiraltrina | 413 | 148 | 262.41 | 93 |
| @adventureralm | 328 | 1 | 0.47 | 1 |
| @bunana_ch | 315 | 242 | 857.47 | 193 |
| @dokibird | 311 | 224 | 711.97 | 167 |
| @vtubermochi | 266 | 229 | 682.71 | 144 |
| @nijisanji_en | 264 | 16 | 17.60 | 14 |
| @seira_chinen | 214 | 287 | 922.72 | 259 |
| @tomoeumari | 206 | 240 | 567.77 | 174 |
| @miwabelle | 203 | 101 | 507.01 | 87 |
| @k9kuro | 194 | 5 | 12.51 | 5 |
| @xinasuwa | 191 | 128 | 382.88 | 116 |
| @mariamarionette | 190 | 273 | 1041.15 | 238 |
premieres are included as streams due to duration
that's a lot of editing! #shorts
kudos to Isekaijoucho (V.W.P.) for 51 covers (including shorts) and Miyu (@miyuyus) for 33 covers (all videos!)
2025-12-11
there have been some feature requests that I don't really know how to direct reply to, so here's an overview
I wish twitch vods worked in multiview
twitch vod parsing added!
I wish alt-click to open chat worked on the schedule page too (quickly checking streams that didn't start on time)
sure, added
?hide= is gone
this was a v2 thing to work around typing out every filter term. it should be easier now in v3 to click select the ones you like (typing is still probably faster for the big groups). redoing ?hide= is backlogged with a change to make ?pin= also receive a list. maybe even create a catbox style short url? I haven't found the time to lock in for it yet.
csv download?
opening the server to unlimited data transfer is scary, especially when the whole operation is subject to cloudflare free tier limits. you might be better off scraping and parsing or even pinging youtube yourself. AI is quite helpful these days with coding guides.
dark mode?
I finally got around to it
error 1102
the real reason for this post is I did some optimizations in the query, cloudflare caching, and moving as much processing I can out from the cloudflare worker. I had the workers exceeded limits error this morning and after deploying it went away, so here's to hoping!
and thank you form users as always for your submissions. your channel contributions and suggestions really guide the site in a good direction
2025-12-12
just saw error 1102 and my worker change killed queries containing V&U it's so over
2025-12-14
updated the site's tools for the first time since like 2023. something in vercel was saying node was out of date, so I ripped the bandaid and updated a bunch of packages forward multiple major versions (3.54 -> 5.46, 2.0.0 -> 7.0.0, etc). pretty violent process, but all I had to manually update was some bad table syntax.
some place I frequent got hacked because they didn't update for 10 years, so this site is doing decent on the system updates front I think.
2026-03-10
2026-01-24 small downtime on my end
it's almost sakura season aka vtuber hiatus season. I'll also be out for a bit, but I should have access to handle any server issues from remote. long explanation of current work items attached below.
I'm still reworking the filter, hide, pin parameters. basically they will each accept the tag or channel name and you can use them all together. for context, right now I'm pulling all upcoming streams, then using the filter param to get a list of all channels in the hierarchy (gen1 -> member1, mem2, mem3), then on the page, you can can see streams filtered by selection or you can uncheck the toggle to see all. if you are curious on what other streams are available without needing to toggle, there is a half-baked functionality called pin. this sets your filter selection a row above the full list (gen1 streams show as a section separate from the others). it's currently an all or nothing toggle.
what's coming up is filter will apply to the list of upcoming streams without an option to toggle. main consideration is bandwidth (why send a list of 100s of waiting rooms when there are realistically 3 across mem1, mem2, mem3 today). if you want to remove a member or gen or other applicable tag, you would use hide (I like gen1 but don't like mem1 -> ?filter=gen1&hide=mem1 -> see only mem2, mem3). this is meant to save the effort of selecting all of one corpo besides one member (?filter=mem2,mem3,mem4...mem9 vs just ?filter=corpo1&hide=mem1). then pin will also take the same tag/channel terms and display them separate from the main section (what was previously ?filter=gen1&pin=1 will just be ?pin=gen1). so real world example, if I want to keep up with phase connect, don't know japanese, and want to highlight their latest gen, the query would look like ?filter=phase+connect&hide=phase+kaleido&pin=phase+saga.
it's almost ready, but I think it's better to avoid shipping a big change right before break. I'm planning to add more general tags like japanese, english, guys, girls for these parameters as well. it's a messy business to label people, so when it goes live please understand it's a work in progress.
some other plans: I have a table that logs an event whenever a waiting room is published or goes live. it's just a matter of converting that to a webpush that doesn't ping people worldwide in an infinite loop. also a bunch of UI and data analysis ideas that need a bit more design. NERV dashboard??
also I saw pomu.moe stopped renewing their lease. I think it was a demo page for an archive tool or something. anyways it's fewer characters than pomu.pages.dev or corpodex.app, so itadakimasu
2026-03-13 about 4 hours downtime
Crashing one hour after I left the house is insane. But now I can confirm tailscale ssh works over plane wifi. Happy Friday
2026-04-02
server is now upgraded from debian 12 to debian 13. I'm still tidying up loose ends from the break so a little longer for the deployment of new items. more details below.
how do I write an incident report? this one was entirely on me, my bad. I've been getting into private torrent trackers and it's been super inconvenient to seed on my PC (high wattage and not very restart friendly). then came the bright idea of freeing up my PC by adding a 12th docker container to the all-purpose raspberry pi server. some combination of shitty experimental installs from over the years, large file rechecking, and the general reliability of SD cards finally caught up to me; all actions slowed to a halt and the server started rebooting on its own with failing services.
very scary to see basic commands take over a minute, and eventually I called it quits, made a quick backup (probably best practice to have these beforehand), and reinstalled the OS. now it's running the site and my torrents just fine. a fresh install once in a while is really the way to go. would have been nicer if I had planned and announced this instead of surprise reinstall time but we survived. downtime was 3-4 hours for the whole ordeal, thank you for your patience.