Simple Llama + SillyTavern Setup Guide
This guide is meant for Windows users who wish to run Facebook's Llama AI language model on their own PC locally. Our focus will be on character chats, reminiscent of platforms like character.ai / c.ai, using Llama 2 models.
Most recently, in late 2023 and early 2024, Mistral AI has released high quality models that are based of the Llama architecture, and will work in the same way if you choose to use them.
-
Requirements
- Windows operating system (may make Mac version of the guide later)
- GPU with at least a few gigabytes of VRAM (NVIDIA graphics cards recommended)
- Sufficient regular RAM for a model (system memory)
- Enough free space on your PC for a model + SillyTavern
- Internet connection
Step 1: Download the latest koboldcpp executable
https://github.com/LostRuins/koboldcpp/releases
- If you are an AMD/Intel Arc user, you should download ‘koboldcpp_nocuda.exe’ instead.
- Then extract it into a new folder at a location of your choice.
Step 2: Choose your Llama 2 / Mistral model
Next, pick your size range. The higher the number, the more parameters the model was trained with, making them better at reasoning, but the higher you go, the more VRAM is required for fast speeds. You can choose between 7b, 13b (traditionally the most popular), and 70b for Llama 2. System RAM is used for loading the model, so the pagefile will technically work there for (slower) model loading if you can fit the whole model in VRAM afterwards.
-
GGUF general RAM recommendations
- 7b = 6GB VRAM and/or regular RAM
- 13b = 10GB VRAM and/or regular RAM
- 8x7b = 24GB VRAM and/or regular RAM
- 70b = 40GB VRAM and/or regular RAM
A high amount of VRAM is not strictly necessary to run any of these models, as you can load parts of the model on the GPU and parts of the model on RAM. However, you will get better performance with GGUF if you are able to fit more of the model into your VRAM, as the graphics card VRAM will always be faster. For example, you can fit about ~80% of a 13b model into 8GB VRAM GPUs (such as the RTX 2070) and the rest will stay in regular memory.
That means: as long as you have enough system RAM to support it, you can technically run any of these on GGUF, but I would try to balance between speed and quality, as VRAM is much faster in comparison. You want as much of the Llama model to be in VRAM as possible.
(This guide won’t cover Exllama2 as it is generally less compatible with older cards / CPU offloading compared to Llama.cpp.)
(Exllama2 has better speeds but harsher VRAM requirements.)
Fine-tuned models are modified versions of the original Llama, tailored for specific tasks. There are many to choose from. People make these so that they have better performance, and in some cases less censorship, for certain tasks (roleplaying, coding, etc.)
Let's focus on examples of fine-tuned models for each parameter size class.
- 7b
Most notable 7b models based off Llama are Mistral finetunes. Mistral is a base model that came out after the original release of Llama 2, and it has solid performance for 7b, with many claiming it punches above its weight class and is almost as good as 13b (with a bigger context window to boot). The most notable Mistral 7b model for roleplay/character chat is Toppy 7b. Your best bet would be the GGUF version, specifically 6_K quantized or higher, if you have the VRAM.
However, a more modern/polished 7b for general purpose use would be Kunoichi DPO v2.
- 13b
Traditionally, the most popular Llama 2 model for roleplay/character chat was MythoMax 13b.
However, bigger and better models have since usurped it in quality and prose. Unfortunately, Llama 2 13b was quite undertrained; Mistral 7b finetunes are arguably better in terms of quality simply because it's a higher quality base model.
Alternatively, you can try this 10.7b frankenmerge which I think is pretty solid for its size: Fimbulvetr 10.7b.
- 8x7b / 47b
Mixtral is a Mixture of Experts model. This allows it to be more efficient compared to a larger dense model, as less parameters will be active at a time.
BagelMIsteryTour v2 is quickly becoming the most popular Mixtral model for RP as of writing in February 2024. Mixtral finetunes will generally do you better compared to Llama 2 70b finetunes.
- 70b
This is a particularly difficult size to run, and after Mixtral came out, there hasn't been much reason to use Llama 2 70b. There was recently a leak of Mistral Medium, which is of this parameter size class, posted on HuggingFace as miqu 70b. The CEO of the company made a pull request that requests attribution rather cheekily, so I guess LLM piracy is something they aren't too concerned about.
This model is not specifically aligned for RP purposes, but is high quality enough to be mentioned as it is the best LLM you can run locally that currently exists. But uh, obviously, don't use it for business purposes.
Quantization reduces model size by rounding numbers. Fewer bits mean more information loss, so choose at least a 3_K_L model, and not 2-bit. 4_K_M and 5_K_M are quite close to uncompressed fp16 models but require less space, while q8_0 will be effectively indistinguishable from the original full precision model.
The way that it works on a technical level means that the range of possible values gets smaller for each lower bit you go.
So, 8 bit will be -127 to 127, while 6 bit is -32 to 32, 5 bit is -16 to 16, etc...
Massive language models generally don't need a lot of precision as much as they need more total parameters to be effective.
For example, even a 4 bit 34b will beat a q8_0 7b in terms of output quality.
Other things to note:
- "K_S" is Small, "K_M" is Medium, and "K_L" is Large.
- 6-bit and 8-bit quantization (q6_K and q8_0 respectively) are virtually indistinguishable in comparison to the full precision model.
- 5-bit (q5_1 or q5_K_M) is (in my opinion) the best tradeoff overall, but 4bit (q4_K_S or q4_K_M) is still very effective.
- Recently, GGUF quantization was improved by the "importance matrix" measurements.
Step 3. Download the latest SillyTavern release
https://docs.sillytavern.app/installation/windows/
- This guide will explain how to install SillyTavern using GitHub Desktop. Make sure you install Node.js as well, as the guide mentions.
Step 4. Launch Koboldcpp
Open koboldcpp.exe. This is how we will be locally hosting the Llama model.
Important Settings
- Switch to ‘Use CuBLAS’ instead of ‘Use OpenBLAS’ if you are on a CUDA GPU (which are NVIDIA graphics cards) for massive performance gains compared to CLBlast or OpenBLAS. AMD/Intel Arc users should go for the Vulkan backend for compatibility instead, as OpenBLAS is CPU only.
- Context Size determines how many ‘tokens’ of text the model is able to remember in a single chat. (For reference, the Navy Seal Copypasta is about ~400 tokens.) 4096 context size is the default maximum for Llama 2 models/finetunes, but you can go higher using RoPE extension (which, if I remember right, is built into Kobold when you go higher). RoPE can potentially have quality loss the farther along you go, but many users with the hardware are able to run 8k context seemingly without issues; YMMV.
- Mixtral finetunes & Miqu 70b both have a native context size of 32,768 tokens. You can go lower if you don't need as much context to conserve memory.
- Disable MMAP should be enabled on Windows if you need to ensure it's all staying in VRAM (if you have the VRAM to do so), according to Llama.cpp CUDA dev.
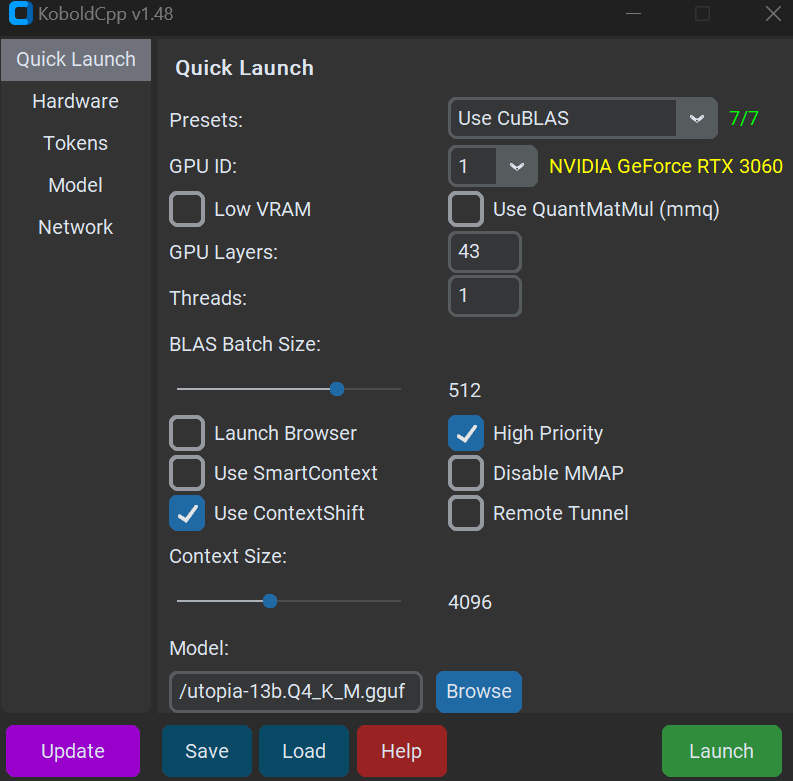
These are the settings I use on a 12GB VRAM graphics card (RTX 3060) for full offload of 13b, 4_K_M.
[Use QuantMatMul is also recommended now]
You will also need to set the GPU layers count depending on how much VRAM you have. For example, if you have 8GB VRAM, you can set up to 31 layers maximum for an older 13b model like MythoMax with 4k context. You want as many GPU layers as possible without ‘overflowing’ the VRAM that is available for context, so to speak.
Select your model and with CuBLAS enabled if you’re a NVIDIA user. Then hit ‘Launch’.
Go to your SillyTavern folder and run ‘UpdateAndStart.bat’.
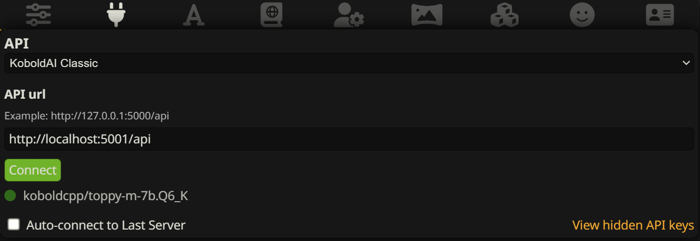
After that you can click ‘Connect’ with the correct kobold API link, and if everything went well, you’re now connected to the model!
Before we start importing characters, you might want to try setting your Advanced Formatting settings to be following a custom instruction setup (Instruct Mode). In the past, Simple-Proxy was considered the best template, but 'Alpaca' is a more modern choice. You may want to experiment with this since Simple-Proxy assumes the user wants detailed and verbose outputs, but in my opinion Alpaca is a good generalist template to start with. ChatML models will generally require ChatML use; this guide's recommendations of models are of those that do not use ChatML.
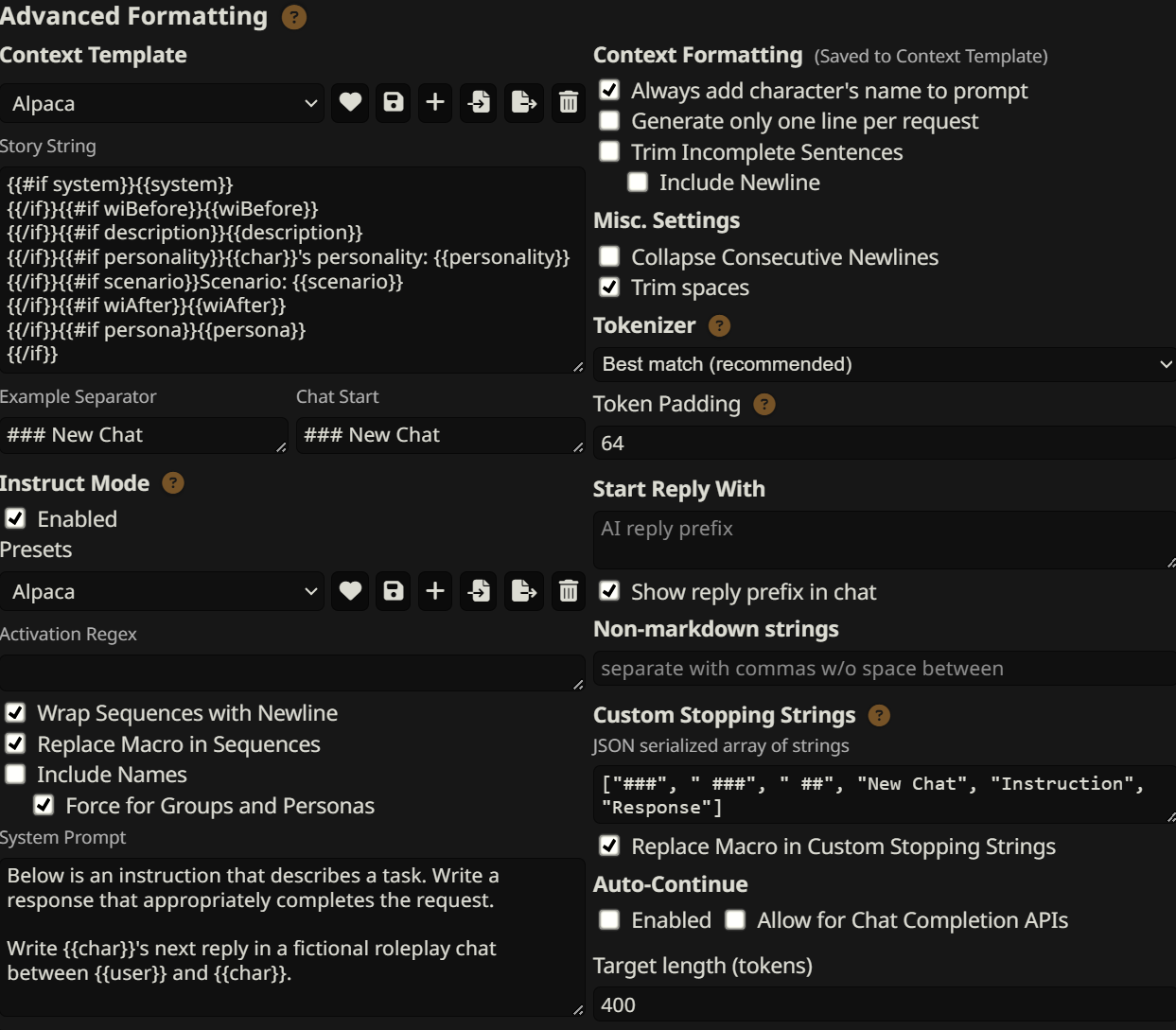
This is a typical Alpaca instruct preset which should be a solid configuration for most models.
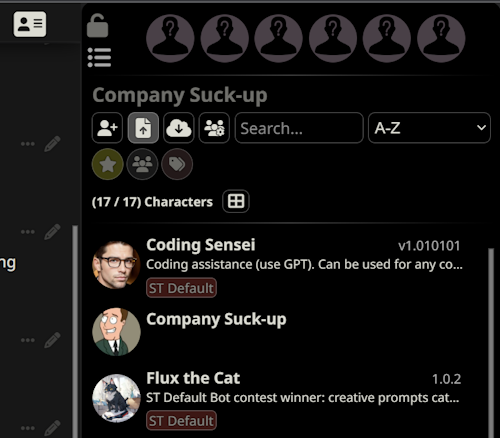
In this tab, hit the upload character button to upload a character card (usually PNGs with attached information to them). You can find SillyTavern cards scattered across Discord servers like the official SillyTavern one, but also on character hub.
(Be mindful of the very unfiltered cards on that website; you’ve been warned)
After that, you can select a card, and it will begin a new chat.
These are good settings that should reasonably work across different models on the latest koboldcpp:
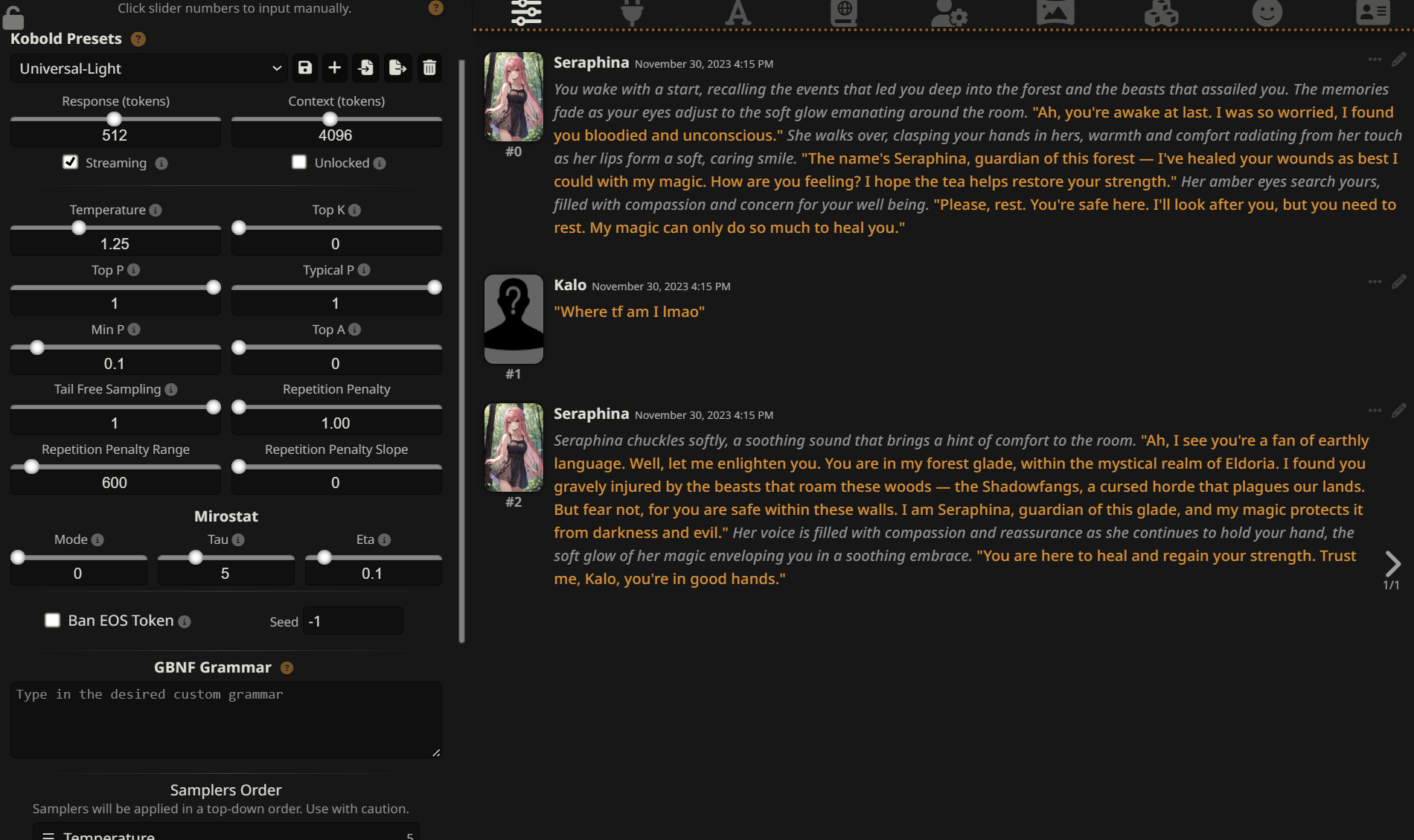
Here are the most important things to know about Sampler settings:
- 'Response' is a hard limit of how many tokens a single response is allowed to have.
- Temperature changes the confidence of the model's initial scores for each word. If you go lower than 1.0, the model will increase the chance of already probable words. If you go higher than 1.0, the chances of less likely scores will be more probable. Values of 1.25-1.75 seem like the sweetspot.
- Min P controls the word diversity based on how likely each word is compared to the most probable one. For instance, if you set Min P to 0.1, only words at least 1/10th as likely as the top choice will be considered during generation; the rest will be discarded.
——————————————————————————————————————————————————————————————————
And that’s about it for basic use of Llama & SillyTavern for character chats!
Other Tips
Other Koboldcpp Settings
- SmartContext will attempt to condense what has happened so far into a summary if your chat goes beyond the context limit. It’s not perfect, but it’s worth a try if you would rather not have the initial chat history start ‘disappearing’, and I am told you can avoid reprocessing long prompts this way as well. If you are fully offloading the model to your GPU, prompt processing time will be so fast that this option is typically irrelevant; otherwise, it may be worth the compromise. EDIT: SmartContext is deprecated. Use ContextShift, this is far superior and doesn't impact quality.
- High Priority will help some systems more than others.
- The "Low VRAM" option will maximize the amount of VRAM that your GPU has access to for generation. This will make the prompt processing times slower, as it will no longer be using your GPU for prompt processing.
- Disabling MMAP is beneficial on Windows if you want to ensure that you're not overflowing the VRAM.
- Streaming Mode & Unban Tokens both no longer exist and have been deprecated; they are now controlled from within SillyTavern itself.
Extra
- This guide is by no means comprehensive, and tries to avoid being overly technical. SillyTavern is not the only frontend; other methods to host Llama exist as well (text-generation-webui for example); this is simply the easiest way to start using and experimenting with local language models.
- Keeping your monitor(s) plugged into your integrated GPU instead of your discrete GPU will save you some VRAM if you're GPU poor.
- Experimenting is essential if you want the best results in general for local models, but the defaults provided here are based on my own experience.
- Here’s a simple card I made of that one Family Guy bit.
Things I might add later:
- More detailed explanation of hyperparams / presets in Tavern.
Older original Google Docs guide:
https://docs.google.com/document/d/1_g-hwrzJ-DPBW2Mxx0HDC610M0B_pIIJexst0zKAjRA/
Edit, October 2023
The guide has been updated to reflect the changes seen in modern koboldcpp & SillyTavern versions. A notable development outside of these tools is that Mistral 7b finetuned models (based off of Llama architecture, but are technically 'new models') exist now; they greatly outperform older Llama 2 7b finetunes, but they are not quite as proven or performant as Llama 2 13b tunes are for the purpose of roleplay.
——————————————————————————————————————————————————————————————————
Don't have at least 6GB of VRAM? You'll probably get worse speeds compared to a free Google Colab instance.
If you decide to take this route, skip to Step 3 of this guide (the part that shows you how to install SillyTavern) and then visit this page: