The absolute retard's guide to setting up koboldAI
 last update 2021-06-17
last update 2021-06-17
Kobold's own installation script (install_requirements.bat) finally downloads all the shit you actually need now. At this point, I don't think there's a real need for this guide anymore. Just make sure to install finetuneanon's transformer during the installation, no matter how much vram you have. There's no advantage to using the normal transformer.
Regardless, what's written here still works if anyone wants to install the requirements manually/needs a little handholding.
Pre Check
Check your vram -> task manager > performance > gpu
| Model | vRAM Required with this method |
|---|---|
| GPT Neo 1.3B | 4GB |
| GPT Neo 2.7B | 8GB |
| GPT-2 | 0.6GB |
| GPT-2 Med | 1GB |
| GPT-2 Large | 8GB |
| GPT-2 XL | 8GB |
| GPT-J | 16GB |
Finetuned models (like horni and horni-ln, both based on Neo 2.7B) can be run via the Custom Neo/GPT-2 option. The system requirements of the model they are based on apply. Custom models have to be downloaded seperately.
You're gonna have problems if you choose a model and don't have enough vram to run it.
This guide will be assuming you've got a CUDA capable nvidia graphics card. As long as it was produced in the last decade, this is probably the case.
Installing
Requirements
- uninstall any version of Python you might have previously downloaded
- install Python 3.9 (or .8 if you feel like it)
- the 64 bit version
- make sure to select Add Python to PATH
- make sure you install pip
- make sure to enable the tcl/tk and IDLE bullshit
- enable the py launcher (not required anymore)
- run the following commands in CMD. Make sure that you install everything listed here. don't accidentally forget something.
python --version- if this does not show the version you have just installed, uninstall ALL versions of python on your system and try again
- if this throws an error, you have either not enabled the py launcher or not added python to your PATH
pip --version- this should not throw an error. if it does, you have not installed pip
pip install https://github.com/finetuneanon/transformers/archive/refs/heads/gpt-neo-localattention3.zippip install torch==1.8.1+cu111 -f https://download.pytorch.org/whl/torch_stable.html- this can take a while and might make your pc freeze for a bit
pip install tensorflow-gpupip install Flask==1.1.2pip install Flask-SocketIO==5.0.1pip install requests==2.25.1pip install colorama
Kobold and Models
- download kobold https://github.com/KoboldAI/KoboldAI-Client by clicking the "Code" dropdown on the right and clicking download zip. unzip where you want it
- assuming you've done everything correctly, you should now be able to just click play.bat in the koboldAI directory and follow the instructions.
- kobold will ask you to choose a model. since we have installed a half precision transformer, you can cut the vram requirements in half. You can choose whichever model you have enough vram for. GPT-NEO 2.7B seems to be the thread's preferred choice. The model download will take a while. As of the 8th of June, 2021, EleutherAI has released a 6 billion parameter model called GPT-Jax. For the setup of this model, see the section GPT-Jax below.
- you can check how much vram you have available in your task manager > performance > gpu
- CHECK YOUR VRAM.
- models will be downloaded to
[user]/.cache/huggingface/transformers
- please note that once the console spits out something about "dynamic library cudart_64 etc.", loading can take up to 20 minutes. don't touch it.
- yes, it's normal that your pc becomes borderline unusable after a while. it means that the model is almost done loading. don't touch it.
- kobold will ask you to choose a model. since we have installed a half precision transformer, you can cut the vram requirements in half. You can choose whichever model you have enough vram for. GPT-NEO 2.7B seems to be the thread's preferred choice. The model download will take a while. As of the 8th of June, 2021, EleutherAI has released a 6 billion parameter model called GPT-Jax. For the setup of this model, see the section GPT-Jax below.
- This userscript implements some hotkeys into kobold for easier one handed operation
Errors
Post your error message
- make a .bat file with the content
cmd- If that's too challenging, you can download the .bat here. It's good practice to open any .bat files you download from the internet with a text editor to make sure they're not gonna delete your system32
- place the file in your koboldAI directory and run it
- that's the one with the play.bat, aiserver.py, etc files. the default name of the directory would be "KoboldAI-Client-main", though you might have renamed it.
- run the command
play.bat - follow the instructions until you hit an error
- post screenshot of the error
- wait for our highly trained team of hobby code monkeys to arrive on site
Or read here
I can't even open koboldAI
- you probably didn't install the py launcher or didn't install python to your PATH
It's crashing as soon as I select a model
- make sure you have all packages listed above installed
- possibly, your GPU does not support CUDA. if that is the case, the following might help
pip uninstall torchpip install torch==1.8.1
ModuleNotFoundError: No module named '[module name here]'
- you forgot to install one of the modules listed above
- go through the above list again
- or you still have multiple versions of python installed and pip downloaded to the wrong python installation.
- uninstall all python versions other than the one you will be using to run kobold or wrangle with python until you manage to make shit install to the right directory
reinstall modules above to the correct directory.
- uninstall all python versions other than the one you will be using to run kobold or wrangle with python until you manage to make shit install to the right directory
Runtime Error: LayerNormKerneImpl not implemented for Half
- Apparently when running torch on CPU, you can't use half precision. This means that you will need to actually meet the vram requirements kobold tells you.
pip uninstall transformerspip install transformers==4.5.1
Can't get my GPU to be recognised on WSL

https://developer.nvidia.com/cuda/wsl
you use linux. figure out the rest yourself.
Mobile Setup
Anon made this fantastic guide: https://rentry.co/itsthateasy
GPT-J Setup
GPT-J is a model comparable in size to AI Dungeon's griffin. To comfortably run it locally, you'll need a graphics card with 16GB of VRAM or more.
But worry not, faithful, there is a way you can still experience the blessings of our lord and saviour Jesus A. Christ (or JAX for short) on your own machine.
V2 Colab
This method requires a google account.
Torch compatible GPT-J:
Links for Torched GPT-J:
Torrent 1
Torrent 2 (newer, gzipped => considerably smaller than the other options)
Mega mirror 1
Mega mirror 2
Be sure to thank anon for those.
- Download the Torched GPT-J above and upload it to your google drive. It should not be in a folder
- Open this colab
- I recommend you make your own copy to your google drive:

- I recommend you make your own copy to your google drive:
- Make sure you're running a GPU instance:
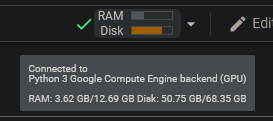
- If this does not say GPU, in the
Runtimemenu, clickChange runtime typeand selectGPU
- If this does not say GPU, in the
- Create a new cell with the following command and run it:
!nvidia-smi- This will produce the following output:
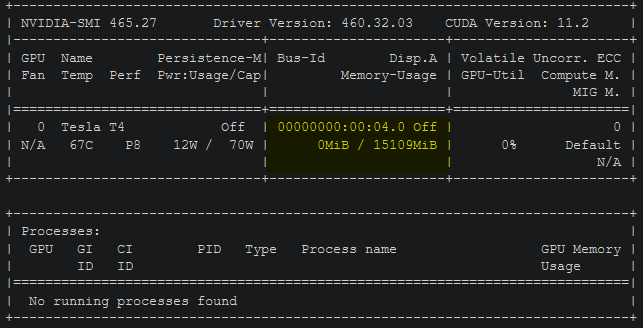
- Check the highlighted area to confirm how much vram your instance has. You will need 15gb or more to run this. If you got one with less, try to terminate and reconnect the instance once or twice, and if it still won't give you one, go do something else for 20-30 minutes and try again. Alternatively, try to get the V1 colab working (see below)
- Follow the instructions in the colab
V1 Colab
The V1 colab runs faster than V2 but uses experimental libraries and you might have to do some troubleshooting yourself.
Old and by now probably outdated information on how to get it running can be found in the archive.
Colab in Flight Encryption
https://rentry.co/koboldEncrypt Basic encryption for colab V1 and V2. Basically the only thing this does is make sure that your ISP and ngrok/cloudflare can't read your shit. Google already knows what you coom to anyways :^)
Anon made a good writeup concerning the "privacy" of google colab:
They also get a decent amount of "good will good boy points" by letting us (as in everyone) use that stuff. It's a bit of "sure you pay with user data, but we give value back (heart emoji)" kind of stunt. Kind of a win/win. Google's soulless corporate heart is also unlikely to go moral crusader on us, since that obscures a lot of data they can be collecting for themselves.
Mind you (this is more for the thread than reply, now) it's more likely they only care about "what" you are doing than the actual data you are processing. Colab has a built-in profiler and I bet they are monitoring the actual function calls and their execution times with voracious interest, more than what is actually going through the pipes. Data at that scale about programming languages, command usages and libraries is actually valuable for a company interested in indexing everything they can, perhaps much more real-money-value than coom and cunny and wanton violence.
Machines get flushed and restored every time you disconnect, meaning any data not stored in a GDrive unit is lost to them (they could keep them on hold, but that could bottleneck their VM pool for little gain). That doesn't stop them from indexing actual files you upload or generate as the session is active, but they can only intercept so much data flowing through the pipes in real time without severely gimping execution (which would make their service less competitive with other providers). In our use case, the value is in what we are doing, what packages we are installing, what shell commands we run, what files we create or upload (and their hashes), what python calls are we using and from which libraries, their execution time and resource usage. They are already getting pretty decent value from our coomscapades.
If we encrypt the traffic in-flight as we talked about last thread, this is (very ironically) one of the most "private" coom machines we can get at the moment.
Local
https://rentry.org/jaxflawlessvictory
Pointers
In stark contrast to the 2.7B models and lower, you actually want your temperature to be closer to 1. Anything in the range of 0.8 to 1.2 should deliver manageable results, though you are encouraged to play with the settings on your own. Jax is apparently very sensitive to repetition penalty, so it is recommended to keep it below 1.2.
You definitely want to set tokens as high as you can. Colab will handle max if you got a 16gb VRAM instance.
Archive
Old stuff that's not up to date anymore goes here.