LoRA学習メモ (Lain, よしなが先生ほか)
概要
Kohya氏のsd-scripts等を使用してLoRAを学習させたときの個人的なメモをちょっとキレイにしたやつです。
SNSのタイムラインのように新しい情報は上にくるよう書く癖があるので(=降順)、順番に読むときは下の方から読むと良いかもしれません。
※現在のところ、sd-scripts作者(Kohya氏)のガイドラインにおおむね準拠した形で学習させておりその他の手法はわかりません。
情報
sd-scripts
なによりも最初に読むべき作者によるREADME。
いくら探しても見つからなかった情報が公式にふつうに書いてあった ← あるある
- ★公式LoRAガイド:sd-scripts/train_network_README-ja.md at main · kohya-ss/sd-scripts | https://github.com/kohya-ss/sd-scripts/blob/main/train_network_README-ja.md
- 公式タグ付けガイド:sd-scripts/fine_tune_README_ja.md at main · kohya-ss/sd-scripts | https://github.com/kohya-ss/sd-scripts/blob/main/fine_tune_README_ja.md
- 公式DreamBoothガイド:sd-scripts/train_db_README-ja.md at main · kohya-ss/sd-scripts | https://github.com/kohya-ss/sd-scripts/blob/main/train_db_README-ja.md
便利なツール
- RedRayz/Kohya_lora_param_gui: GUI for kohya-ss sd-scripts - https://github.com/RedRayz/Kohya_lora_param_gui
NVAスレニキ製のsd-scripts GUI。GUIで設定したparametersをsd-scriptsに渡してくれるシンプル仕様なのが良き - toshiaki1729/stable-diffusion-webui-dataset-tag-editor: Extension to edit dataset captions for SD web UI by AUTOMATIC1111 - https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
おそらくふたばのとしあき製のデータセットタグエディター。スタンドアロン版もあるが若干バグってるのでIssueを読んで解決する必要あるかも
学習テスト|SDXL
ケース02:ゆるキャン:犬山あおい for Pony系統
2024年2月25日
▼LoRA生成サンプル
出力|AutisMix_SDXL

▼前提条件
そもそもPonyで犬子(このキャラクター)はかなり学習されている
二次創作顔から公式顔になるみたいなすごい微妙な変化
←未使用 | LoRA Enable→

▼画像タグ付け
画像|64枚くらい
としあきタグエディターでWD14タガーを使ってタグ付けして、inuyama aoi, yurucamp, を先頭に追加。
▼コマンド
accelerate launch --num_cpu_threads_per_process 4 sdxl_train_network.py --pretrained_model_name_or_path "C:\ProgramTools\__GenerativeAI\StableDiffusionModels\__SDXL\Pony_Diffusion_V6_XL\ponyDiffusionV6XL_v6StartWithThisOne.safetensors" --train_data_dir "H:\Resources\Resources_AI\forLeaningImages\Yurucamp\inuyama_aoi\v3" --output_dir "H:\Resources\Resources_AI\__Models\__Lola\__MyLoRAs\SDXL" --network_module "networks.lora" --network_args "conv_dim=32" "conv_alpha=16" --mem_eff_attn --gradient_checkpointing --persistent_data_loader_workers --cache_latents --cache_latents_to_disk --max_data_loader_n_workers 1 --enable_bucket --save_model_as "safetensors" --lr_scheduler_num_cycles 4 --mixed_precision "fp16" --learning_rate 0.0001 --resolution 768 --train_batch_size 2 --max_train_epochs 20 --network_dim 32 --network_alpha 16 --save_every_n_epochs 5 --optimizer_type "PagedAdamW8bit" --output_name "lora_XL_yurucamp_inuyama_aoi_v3_pagedAdamW8bit_d32a16" --save_precision "fp16" --lr_scheduler "cosine" --min_bucket_reso 320 --max_bucket_reso 1536 --caption_extension ".txt" --max_token_length 225 --shuffle_caption --keep_tokens 1 --seed 42 --no_half_vae --logging_dir "E:\Creative\Program\Github\__AI\Art\TraningLog\sd_scripts\log" --log_prefix=lora_XL_yurucamp_inuyama_aoi_v3_pagedAdamW8bit_d32a16
下のケース01から流用。
追加:--shuffle_caption --keep_tokens 1
▼結果
公式のアニメの感じは再現されていい感じ。
manga, comic, speech bubble, Onomatopoeia, multiple views, みたいなプロンプトがガン無視されるようになってしまった。1枚絵しかでない。
すでに概念は学習されているのですごく軽くしか回してないのに謎。
改善方法をみつけたい。
▼ログ(省略)
ケース01:セーラーマーキュリー(水野亜美) for Pony系統
2024年2月25日
▼LoRA生成サンプル
出力|AutisMix_SDXL

▼画像
77枚
ボケボケのとか古い映像のノイズとか小さい画像入りまくり。アップスケール前処理とかなんもしてない。意外となんとかなる。
としあきタグエディターでWD14タガーを使ってタグ付け。先頭にsailor mercury, mizuno ami,

▼結果
レトロかわE
--shuffle_caption --keep_tokens 2をつけ忘れたからか、フォルダ名が10_sailormercury 1girl だから分からないが、mizuno ami だと反応しないLoRAが出来上がった。
▼コマンド
accelerate launch --num_cpu_threads_per_process 4 sdxl_train_network.py --pretrained_model_name_or_path "C:\ProgramTools\__GenerativeAI\StableDiffusionModels\__SDXL\Pony_Diffusion_V6_XL\ponyDiffusionV6XL_v6StartWithThisOne.safetensors" --train_data_dir "H:\Resources\Resources_AI\forLeaningImages\Sailormoon\sailormercury_v3" --output_dir "H:\Resources\Resources_AI\__Models\__Lola\__MyLoRAs\SDXL" --network_module "networks.lora" --network_args "conv_dim=32" "conv_alpha=16" --mem_eff_attn --gradient_checkpointing --persistent_data_loader_workers --cache_latents --cache_latents_to_disk --max_token_length 225 --max_data_loader_n_workers 1 --enable_bucket --save_model_as "safetensors" --lr_scheduler_num_cycles 4 --mixed_precision "fp16" --learning_rate 0.0001 --resolution 768 --train_batch_size 2 --max_train_epochs 8 --network_dim 32 --network_alpha 16 --save_every_n_epochs 1 --optimizer_type "PagedAdamW8bit" --output_name "lora_XL_ponyV6_mizuno_ami_v1_pagedAdamW8bit_d32a16" --save_precision "fp16" --lr_scheduler "cosine" --min_bucket_reso 320 --max_bucket_reso 1536 --caption_extension ".txt" --seed 42 --no_half_vae --logging_dir "E:\Creative\Program\Github\__AI\Art\TraningLog\sd_scripts\log" --log_prefix=lora_XL_ponyV6_mizuno_ami_v1_pagedAdamW8bit_d32a16
▼メモ
学習元は、ponyDiffusionV6XL_v6StartWithThisOne.safetensors
オプティマイザにpagedAdamW8bitを使っている。個人的にオプティマイザはAdamW8bit信者だが、SD1.5のときに使用して結果に影響を与えずに速度向上ができたのでSDXLでも継続して使ってみている。SDXLで早くなっているかは未検証。
コマンドはKohya_lora_param_guiのでSDXL用プリセットをベースに作成した(気がする)。いまだに直打ちしてるのが --log_prefix= とかがGUIで対応してなかったからだった気がするので、GUIでやったほうが安全な気がする。
PonyはTEとUNETどっちもやったほうがいい (NVAスレ民説)とのことで以下を削除
--network_train_unet_only
エラー
AssertionError: network for Text Encoder cannot be trained with caching Text Encoder outputs / Text Encoderの出力をキャッシュしながらText Encoderのネットワークを学習することはできません
→削除:--cache_text_encoder_outputs --cache_text_encoder_outputs_to_disk
▼ログ
学習テスト|SD1.5
学習テスト(sd-scripts: 5):ゆるキャン
ゆるキャン:犬山あおい
▼結果
かわよ
⏬https://civitai.com/models/7033/yurucampinuyamaaoi

▼学習
学習の結果は、キャラクターデザインのリファレンスシートとかがあったり、アニメキャプチャがあったり、一貫性のあるリソースがあったためだと思います。
dim4設定(デフォルト値)でファイルサイズ9MBぽっちですが、どのようなモデルでも再現性は十分でした。

python tag_images_by_wd14_tagger.py --batch_size 5 "H:\Resources\Resources_AI\forLeaningImages\Yurucamp\inuyama_aoi\40_inuyamaaoi 1girl"
64枚×40=2560
4エポック=10240
dim4, 768解像度、4エポック、
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai_sfw.ckpt --train_data_dir=H:\Resources\Resources_AI\forLeaningImages\Yurucamp\inuyama_aoi --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI\__Models\__MyTrainModels --train_batch_size=2 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --text_encoder_lr 5e-5 --network_dim=4 --clip_skip=2 --learning_rate=1e-4 --max_train_steps=10240 --resolution=768,768
ログを出したかったけど入れるの忘れた
学習テスト(sd-scripts: 4):BlueArchive
学習:Ajitani Hifumi
▼結果
いい感じにできた
⏬:https://civitai.com/models/7050/bluearchiveajitanihifumi

▼学習
学習の結果は、Danbooruにあるこのキャラクターのイラストがみんないい感じだったせいが大きいかと思います。
▼初期セットアップ
※使ってない
学習データ:314枚
フォルダ:40_Ajitani 1girl
628×40=25,120
python tag_images_by_wd14_tagger.py --batch_size 3 "G:\TOOL\__Python\gallery-dl\gallery-dl\danbooru\hifumi_(blue_archive)+solo\40_Ajitani 1girl"
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai_sfw.ckpt --train_data_dir=G:\TOOL\__Python\gallery-dl\gallery-dl\danbooru\hifumi_(blue_archive)+solo --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI\__Models\__MyTrainModels --train_batch_size=1 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --text_encoder_lr 5e-5 --network_dim=4 --clip_skip=2 --learning_rate=1e-4 --max_train_steps=25120 --resolution=768,768
おま環かもしれないけど、やっぱ透過PNG死ぬっぽいので大人しくJPGに変換するやで……
:\Creative\Program\Github\__AI\Art\sd-scripts\venv\lib\site-packages\PIL\Image.py:996: UserWarning: Palette images with Transparency expressed in bytes should be converted to RGBA images warnings.warn( steps: 1%|▎ | 131/25120 [04:43<15:01:54, 2.17s/it, loss=0.0562]
▼54枚に削減版
python tag_images_by_wd14_tagger.py --batch_size 5 "G:\TOOL\__Python\gallery-dl\gallery-dl\danbooru\hifumi_(blue_archive)+solo\02"
54×0×2=4,320
12960
57×40×2 = 4560
3エポック=13680
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai_sfw.ckpt --train_data_dir=G:\TOOL\__Python\gallery-dl\gallery-dl\danbooru\hifumi_(blue_archive)+solo\02 --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI\__Models\__MyTrainModels --train_batch_size=1 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --text_encoder_lr 5e-5 --network_dim=4 --clip_skip=2 --learning_rate=1e-4 --max_train_steps=13680 --resolution=768,768
あかん5時間は長い
512×512にする
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai_sfw.ckpt --train_data_dir=G:\TOOL\__Python\gallery-dl\gallery-dl\danbooru\hifumi_(blue_archive)+solo\02 --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI\__Models\__MyTrainModels --train_batch_size=1 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --text_encoder_lr 5e-5 --network_dim=4 --clip_skip=2 --learning_rate=1e-4 --max_train_steps=13680 --resolution=512,512
学習テスト(sd-scripts: 3):勝利の女神 NIKKE
※編集中
基本絵1枚で学習とかをしてました。
複数概念の学習も予定してます。
▼NIKKE_Anis_v2
▼結果
なんか基本絵1枚に比べてキャラ再現性が落ちた気がする。
言っちゃ悪いけど、学習リソースを増やしたいからと言って、キャラの特徴を捉えていないあんまりあれな絵を含めると逆に悪影響を及ぼす可能性がある。

▼タグ付け
python tag_images_by_wd14_tagger.py --batch_size 4 "H:\Resources\Resources_AI\forLeaningImages\NIKKE\NIKKE_Anis\Manual2\40_nikkeanis 1girl"
あじたにひふみv1からコピーしてきたやつ
低dim設定
学習データ49枚:40_nikkeanis 1girl
49×40×2=1エポック3920
3エポック11760
4エポック15680
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai_sfw.ckpt --train_data_dir=H:\Resources\Resources_AI\forLeaningImages\NIKKE\NIKKE_Anis\Manual2 --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI\__Models\__MyTrainModels --train_batch_size=1 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --text_encoder_lr 5e-5 --network_dim=4 --clip_skip=2 --learning_rate=1e-4 --max_train_steps=15680 --resolution=512,512
▼NIKKE:Anis_v1
▼結果

▼今回の学習の主目的
- 基本絵1枚、合計データ10枚の低リソース学習はどういった結果を返すか
- 解像度を上げたらどうなるか
- network dim 128
▼画像編集
Danbooruは使わずにGoogle画像検索でポチポチダウンロード

Danbooru収集
gallery-dl https://danbooru.donmai.us/posts?tags=anis_%28nikke%29+solo&z=5
タグ
python tag_images_by_wd14_tagger.py --batch_size 3 "H:\Resources\Resources_AI\forLeaningImages\NIKKE\NIKKE_Anis\Manual_simple\40_nikkeanis 1girl"
▼学習
40_nikkeanis 1girl
10枚、40回 = 400
1エポック800 (なんで×2されるのかわからん)
5エポック4000ステップ
主な変更点は以下
--resolution=768,768 --network_dim=128 --learning_rate=1e-4 --text_encoder_lr 5e-5
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=E:\Creative\Program\Github\__AI\Art\StableDiffusion_AUTOMATIC1111_v7.0\stable-diffusion-webui\models\Stable-diffusion\AOM2f.safetensors --train_data_dir=H:\Resources\Resources_AI\forLeaningImages\NIKKE\NIKKE_Anis\Manual_simple --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI\__Models\__MyTrainModels --resolution=768,768 --train_batch_size=1 --learning_rate=1e-4 --text_encoder_lr 5e-5 --max_train_steps=4000 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --network_dim=128
学習テスト(sd-scripts: 2):クレヨンしんちゃんのキャラクター
- 学習させたいキャラがそもそもマスピ顔だったりすると学習されてんのかされてないのかが曖昧で困る
(あとマイナーすぎるキャラだと第三者からみて似てんのか似てないのかわからなくて困る) - 完璧に学習されたまつざか先生(ビーチでビキニ着てるやつ)がスレにぽっと貼られて衝撃を受ける
- 流行の画風からはかけ離れたファミリーアニメ系のキャラクターは学習のスタートに最適かもしれない
- ↑イマココ
野原ひろし (クレヨンしんちゃんテスト02)

▼画像収集
ImageeyeでGoogle画像検索から収集
▼プロンプト例(一番右)
1boy, white_background, jacket, upper_body, white_shirt, male_focus, necktie, facial_hair, formal, suit, (cowboy shot, looking at viewer:1.1), solo, simple_background, shirt, black_hair, (nhh:1.7), lora:LoRA_nnh_NoharaHiroshi:1.06
Negative prompt: nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.2),( 3D, realistic:1.0), (loli, child, infant:1.4), pointy ears,
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 3966759607, Size: 512x864, Model hash: 038ba203d8, Model: AbyssOrangeMix2_sfw, Clip skip: 2, ENSD: 31337
かなり強調しないとモデルのデフォルト1mature maleがコスプレしただけのイケオジCEOマンみたいになりがち。
identiferを強調してもあまり意味はないっぽい(例:(nhh:1.7))。
▼概要
BooruDatasetTagManagerでnhhをすべてのタグの先頭につけてみるテスト
→タグ(nhh←NoHaraHiroshi)が効かないLoRAができた。1.0にしても2.0にしてもなんも影響力を発揮してない感じがある。一応、(nhh:1.0), lora:LoRA_nnh_NoharaHiroshi:1.3
みたいにLoRAの数値を上げていけばなんか効いてきて野原ひろしになるっちゃなる。
WD Taggerでタグ付けしたらそのまま学習に投げていいんじゃね?って感じはある
ベースモデル:NAI (nai_full).ckpt
タグ付け
python tag_images_by_wd14_tagger.py --batch_size 3 "H:\Resources\Resources_AI\forLeaningImages__KureyonShinchan__NoharaHiroshi\40_nhh 1boy"
学習
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai.ckpt --train_data_dir=H:\Resources\Resources_AI\forLeaningImages__KureyonShinchan__NoharaHiroshi --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI__Models__MyTrainModels --resolution=512,512 --train_batch_size=1 --learning_rate=1e-4 --max_train_steps=5000 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --network_dim=64
よしなが先生 (クレヨンしんちゃんテスト01)
かわE

▼プロンプト例:右下の焼肉くわえてるやつ
1girl, solo, (28yo, mature female, curvy:1.2) , long hair, (bust up, upper body, looking at viewer:1.1), open mouth, brown hair, shirt, bow, standing, ponytail, hair bow, black eyes, (chewing, satisfied, content, holding chopsticks, eating, meat, barbeque, holding plate, full plate, yakiniku restaurant, dressed in traditional Japanese attire, kimono, geta sandals, hair tied up, happy face:1.1), lora:yoshinaga_v2_epoch-000003:1.08, (ysn:1.7), ,
Negative prompt: nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.2),( 3D:1.0), (loli, child, infant:1.4), pointy ears,
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 2472926398, Size: 512x864, Model hash: 038ba203d8, Model: AbyssOrangeMix2_sfw, Clip skip: 2, ENSD: 31337
かなり強調しないとモデルのデフォルト1girlがコスプレしてるみたいなキャラクターになりがち。
(ysn:1.7),とか意味ないっぽい(?)
フォルダ命名規則「40_ysn 1girl」等は以下のように呼称されている
- ysn = identifier
- 1girl = class
引用:sd-scripts/train_db_README-ja.md at main · kohya-ss/sd-scripts
https://github.com/kohya-ss/sd-scripts/blob/main/train_db_README-ja.md
このときのidentifier(例:ysn)はタグ付け等をすると無効になるらしい(?)
identiferを強調してもあまり意味はなく、lora:yoshinaga_v2:1.08等、LoRA強度を強めて調整できることは確認できた。
▼画像収集
Google画像検索で画像収集したかったので、Imageeyeなる拡張を使って収集。
Image downloader - Imageye - Chrome ウェブストア - https://chrome.google.com/webstore/detail/image-downloader-imageye/agionbommeaifngbhincahgmoflcikhm?hl=ja
なおPythonスクリプトでいい感じのを見つけようとすると
hardikvasa/google-images-download: - https://github.com/hardikvasa/google-images-download
が見つかるけど、古くてGoogleの仕様に対応していないらしいので非推奨。
▼学習素材
フォルダ:40_ysn 1girl
35枚くらい

▼学習
network_dim=32、clip_skip=2にしてみた以外はあまりLainと変わらない。
network_dim=32で72MBくらいになります。
ベースモデル:NAI (nai_full).ckpt
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai.ckpt --train_data_dir=H:\Resources\Resources_AI\forLeaningImages__KureyonShinchan\YoshinagaSense\sfw --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI__Models__MyTrainModels --resolution=512,512 --train_batch_size=1 --learning_rate=1e-4 --max_train_steps=10000 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225 --network_dim=32
学習テスト(sd-scripts: 1):Lain(岩倉玲音)

▼生成モデル:AOM2hard + LoRA_IwakuraLain_v4_nai :https://files.catbox.moe/ufxcer.safetensors
▼学習の流れ
- 画像収集にgallery-dl(スタンドアローン版)を使用:https://github.com/mikf/gallery-dl#id9
gallery-dl https://danbooru.donmai.us/posts?page=1&tags=iwakura_lain+soloで画像を収集- PhotoShift で人力で選別
- \sd-scripts\finetune\tag_images_by_wd14_tagger.py でタグ付け
- sd-scripts呪文を唱える
- 完成
学習時間1時間半くらい (RTX3060 12GB、Ryzen3900XT)
▼学習画像フォルダ
G:\TOOL__Python\gallery-dl\gallery-dl\danbooru\iwakura_lain_solo\X_Manual
学習画像115枚
フォルダ名:40_iwl 1girl
→tag: iwl class: 1girl
▼タグ付け
WD14Taggerによるタグ付け
- Git bash here とか、ディレクトリ欄に「cmd → Enter」とかでsd script ディレクトリを開く
- アクティベートする
.\venv\Scripts\activate - cd E:\Creative\Program\Github__AI\Art\sd-scripts\finetune
みたいな感じで移動する (タグ付けのスクリプトがここのフォルダに置いてあった) - python tag_images_by_wd14_tagger.py --batch_size 4 G:\TOOL__Python\gallery-dl\gallery-dl\danbooru\iwakura_lain_solo\X_Manual
みたいな感じでバッチサイズとフォルダを指定する - Enterで実行
- タグ付けされる
100枚のタグ付けに3分くらい。
▼正則化画像
透過10枚


▼ベースモデル:NAI (nai_full).ckpt
▼sd-scripts呪文
○ベース:公式LoRAガイドのコード↓
accelerate launch --num_cpu_threads_per_process 12 train_network.py
--pretrained_model_name_or_path=..\models\model.ckpt
--train_data_dir=..\data\db\char1 --output_dir=..\lora_train1
--reg_data_dir=..\data\db\reg1 --prior_loss_weight=1.0
--resolution=448,640 --train_batch_size=1 --learning_rate=1e-4
--max_train_steps=400 --use_8bit_adam --xformers --mixed_precision=fp16
--save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug
--network_module=networks.lora
○実際に使用したコード
accelerate launch --num_cpu_threads_per_process 24 train_network.py --pretrained_model_name_or_path=C:/ProgramTools/__GenerativeAI/StableDiffusion_AUTOMATIC1111_v6.0/stable-diffusion-webui/models/Stable-diffusion/nai.ckpt --train_data_dir=G:\TOOL__Python\gallery-dl\gallery-dl\danbooru\iwakura_lain_solo\X_Manual --reg_data_dir=H:\Resources\Resources_AI\forLeaningImages\touka\10images --output_dir=H:\Resources\Resources_AI__Models__MyTrainModels --resolution=512,512 --train_batch_size=1 --learning_rate=1e-4 --max_train_steps=10000 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=1 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225
変更点
- --num_cpu_threads_per_process 24: CPUのスレッド数
- --enable_bucket : NovelAIが開発した異なるアスペクト比で学習可能にするオプション
- --color_aug : 学習時に動的にデータを変化させることで、モデルの性能を上げる手法
- --max_token_length=225 : トークン長を拡張して学習
--network_dim オプションを付与して精度を上げてる人も多いっぽい。デフォルト4→64など。ここを増やすとLoRAのファイルサイズが肥大化する。
--learning_rate=1e-3は0.001 1e-4は0.0001 5e-5は、0.00005
5e-5は4ちゃんのLoRAで見た設定
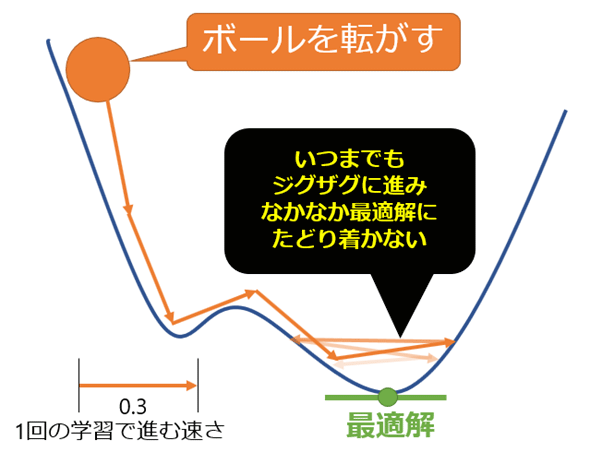
https://atmarkit.itmedia.co.jp/ait/articles/1912/16/news026.html
learning_rate = こういうことしてるらしい
▼コマンドプロンプトのログ
書き込み保存
スレに書き込んだ書き込みの保存
817: 2023/01/25(水) 16:53:32.45
sd scriptのGUI版でLoraのトレーニング始めたんだけど、クソほどエラー吐いたのでやめた
ワイはいつになったら学習に着手できるんや
853: 2023/01/25(水) 18:24:29.23
817
これだけど
python -m venv venv のほうが python -m venv --system-site-packages venv より安全そうなため書き換えました。globalなpythonにパッケージがインストールしてあると、後者だといろいろと問題が起きます。)
に引っかかった感じかもしれない。torchとかglobalにインストールしてあると死ぬ
作者純正の方Cloneしてコマンド打ったら学習し始めたわ
954: 2023/01/25(水) 22:16:03.25
949
これワイもハマったわ
要するに_にリネームした学習画像データのフォルダは直接指定しないでねって話で例えば↓こういうこと
✕|E:\TrainDatas\001\img\40_kdy 1girl
◎|E:\TrainDatas\001\img
間違うと画像が見つかりませんと怒られる
849: 2023/01/27(金) 18:43:32.13
LoRAやってみてるんだけど、DBに比べるとモデルのデフォルト1girlが学習キャラのコスプレしてるみたいな画像にならない?
設定が悪いんかな
--resolution=512,512 --train_batch_size=1 --learning_rate=1e-4 --max_train_steps=800 --use_8bit_adam --xformers --mixed_precision=fp16 --save_every_n_epochs=1 --save_model_as=safetensors --clip_skip=2 --seed=42 --network_module=networks.lora --enable_bucket --color_aug --max_token_length=225
863: 2023/01/27(金) 19:54:20.70
ほーん
"learning_rate = 1e-4"は、学習率が0.0001を表しています。 これは、学習スピードがやや遅めで、精度が高い可能性が高いことを示しています。この値は環境やデータセットによって異なりますが、一般的には小さな値が使用されます。
学習率が大きすぎると、学習が収束しない、振動する可能性があります。学習率が小さすぎると、収束までに時間がかかる可能性があります。学習率を調整することで、学習スピードと精度のバランスを取りながら、最適な結果を得ることができます。
5e-5と1e-4を小数点表記で表すと?
"5e-5"は、0.00005、 "1e-4"は0.0001を表します。
866: 2023/01/27(金) 19:56:31.63
learning_rate = こういうことしてるらしい
937: 2023/01/27(金) 22:01:59.13
ついにLainを生成するのに成功した! asymmetrical hair, single sidelockとかやっても出なかったあの独特な髪型めちゃくちゃ安定してるわ。リークNAIを触り始めてからの目標だったので嬉しいぞ



個人的なメモだけどワークフロー簡単にまとめました
954: 2023/01/27(金) 23:02:10.82
947
そのまんま透過PNGやで。たしかWikiあったやつ
正直、正則化画像は雰囲気や
197
1e-3は0.001、5e-5は、0.00005、 1e-4"は0.0001で極小になるほど精度が上がって最適解に収束するらしい
227: 2023/01/28(土) 13:19:43.19
コスチュームがあんま決まってないキャラ(Lain)のLoRAだったら着せ替えは普通にできた
黒白ストライプのサンタ服とか花柄のねずみ色のセーラー服みたいなイミフな服も生成された
たぶんがっちりキャラデザされてるキャラだと生首方式のほうがいいかもしれない


862: 2023/01/29(日) 11:14:32.94
自分がドキュメント読んで理解した限りでは、Taggerでタグ付けして、なおかつキャプションつけるときにそれらを統合する手順を踏んでねって感じだったような。ただキャプション付けはエアプなんで合ってるかわからん
263: 2023/01/30(月) 01:15:39.61
240GB 1,400 LoRA files ほか
4ちゃんのくそデカ学習モデルパックはダウンロードしたかい
magnet:?xt=urn:btih:XFDFHICCEVQ6IXQXRSBBT7SN5SC6RWSI&dn=lora-torrent&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
208
これはこのフォルダ名にすると「tag: iwl class: 1girl」になるぞっていう説明
LainのときはTaggerにお任せでそのまま学習に投げたから先頭にiwlとかはついてなかったと思う

653: 2023/01/30(月) 18:11:42.09
草


ただBooruDatasetTagManagerでnhhをすべてのタグの先頭につけてみたらなんかタグ(nhh←NoHaraHiroshi)が効かないLoRAができた。1.0にしても2.0にしてもなんも影響力を発揮してない感じがある。一応、(nhh:1.0),,lora:LoRA_nnh_NoharaHiroshi:1.08
みたいにLoRAの数値を上げていけばなんか効いてきて野原ひろしになるっちゃなる。
WD Taggerでタグ付けしたらそのまま学習に投げていいんじゃね?って感じはある
727: 2023/01/30(月) 19:45:28.37
LoRA学習のメモ追加で更新しといた
259: 2023/01/31(火) 18:09:22.90
次元数(rank)が違うとLoRAのマージができないっていう"次元数"ってnetwork dimのことだと理解してるんだけど、学習者ごとに各々好きな値を設定して配布する形になると、マージ互換性のないLoRAがたくさん出回ることになりそうだなあ
263: 2023/01/31(火) 18:14:54.49
Ti普通に有用だと思う。LoRA2つ以上使うと破綻してくる
LoRA or DreamBooth:キャラのベースデザイン
構図や仕草:Ti
みたいな棲み分けはよさそう
357: 2023/01/31(火) 21:15:44.40
フォルダがよしなが先生だらけになってきたぞ……


487: 2023/02/01(水) 01:13:34.55
う~ん着替えさせたいとか体型変えたいからとかで首を切ったり、タグを消したりっていうの疲れるだけであんまりしてもしなくていい気がする
よしなが先生とかデータはこんなんばっかだけど、curvyしたらムチムチになるし、school uniformも着るし、バイクも乗る

497: 2023/02/01(水) 01:32:40.09
っていうかフォルダの命名規則の「40_ysn 1girl」のidentifierってプロンプトに打つ必要ないんだな?
lora:yoshinaga_v2_epoch-000003:1.08とか打つだけで効いてる
これは複数概念を学習させたときに呼び出す呪文なんだろうか
って書いてたら>>484が書いてたわ学習なんもわからん
