Unfucking  with
with  using refinery, the veggie recipe
using refinery, the veggie recipe
Are you tired of coping with the same incurable western piss-enriched 2.5D ponyslop present in autism even with 10 style loras stacked? Are you tired of seeing those sICk lines, lack of characters and styles, fried non-working loras and that smug look on the horsefucker's face? Are you already tired of waiting for that sloppy Cascade tune from the butthurt furry (release date is late 2025 btw)? Well, no more! Follow this rentry and start using the best local huffing tech yet available!
wat is a ruh-fai-nr?
For those who don't already know, firstly the refinery as a technique was widely introduced in the original SDXL paper which was used to "improve the visual fidelity of samples generated by SDXL". I think the smart name of the technique is "Ensemble of Expert Denoisers", as per eDiff-I paper. SAI (StabilityAI) trained two separate models: the base (everyone are using the finetunes of it) and the refiner, which is, despite the name, is not the main topic here.
Why no one is using the "stock" refiner, you ask? No one can bother finetuning the refiner model, and it will yield much better result if you just train the base model well in the first place. And without finetuning, the refiner is completely useless. Yes, these are the only reasons you don't see anyone using the original refiner model.
To put it simple, refining splits the diffusion process in two parts.
During the first part nothing unusual happens except the diffusion stops prematurely.
During the second part, you switch to another (refiner) model and continue sampling from where the first model left off.

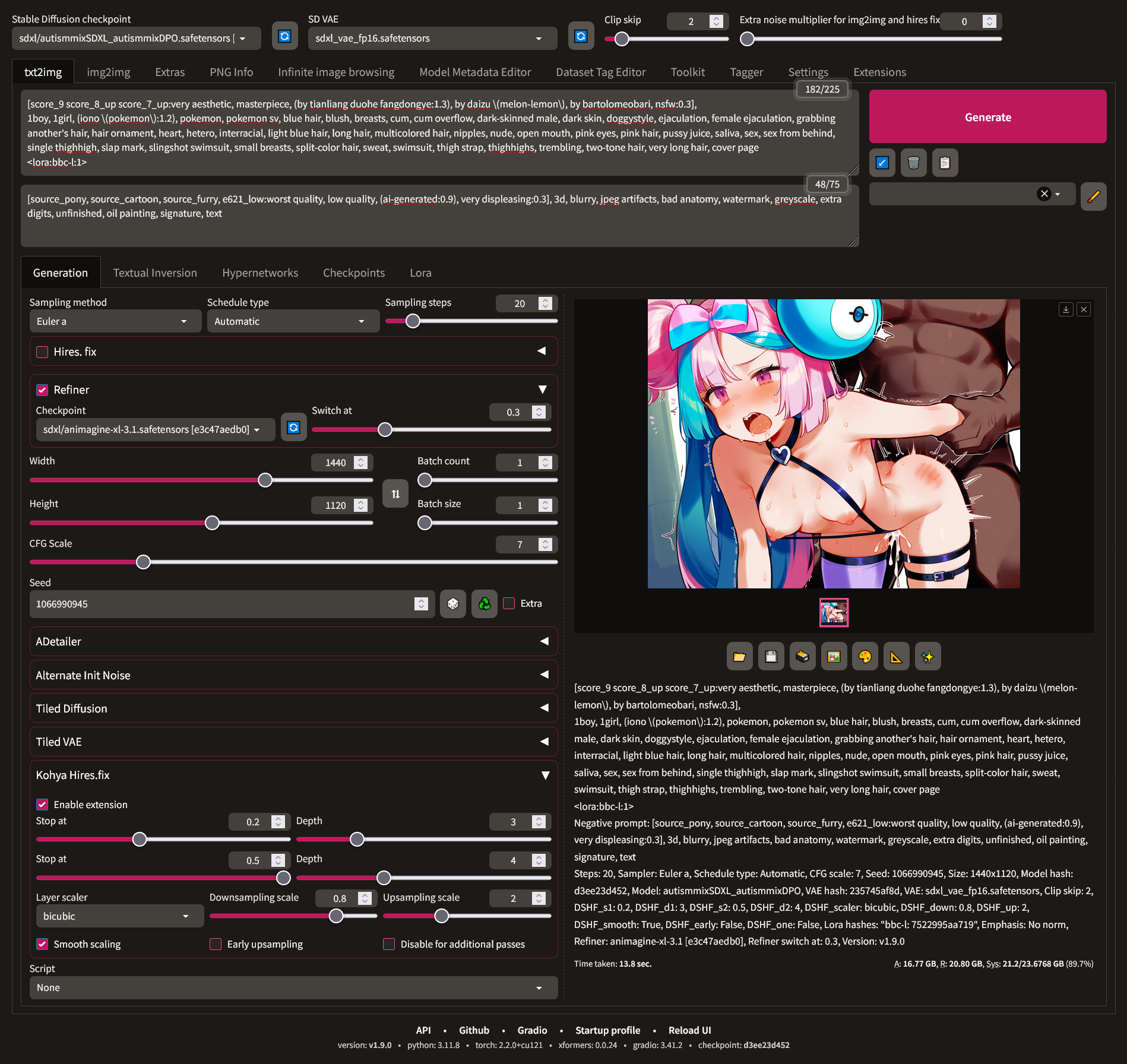
Since we don't have any finetunes of SDXL's refiner model, we will replace it with Animagine XL.
CHAPTER 3: WHY USE TEH REHFINAER XD RAWRZORRS?
For those who want to know more, go read these two papers, the first one is about SDXL and the other one is the main suspect of SAI even bothering with this shit: https://arxiv.org/pdf/2307.01952 https://arxiv.org/abs/2211.01324
But here are the most relevant parts (SDXL):
Empirically, we find that the resulting model sometimes yields samples of low local quality. To improve sample quality, we train a separate LDM in the same latent space, which is specialized on high-quality, high resolution data and employ a noising-denoising process as introduced by SDEdit on the samples from the base model. We follow and specialize this refinement model on the first 200 (discrete) noise scales. During inference, we render latents from the base SDXL, and directly diffuse and denoise them in latent space with the refinement model, using the same text input. We note that this step is optional, but improves sample quality for detailed backgrounds and human faces, as demonstrated.
eDiff-I:
We found that the generation process in text-to-image diffusion models qualitatively changes throughout synthesis: Initially, the model focuses on generating globally coherent content aligned with the text prompt, while later in the process, the model largely ignores the text conditioning and its primary goal is to produce visually high-quality outputs
if you read the passages above, you should understand that the first steps of the denoising process affect mostly the content of the resulting image, while the latter steps affect the style and how the content should look.
This is very good for us, perfect even. It is a known fact that pony handles anatomy and prompt understanding very well. Animagine is known for its decently good anime style capabilities, but it's kinda lacking on the "understanding" counterpart.
If only you could somehow share pony's content and anatomy knowledge and Animagine's style...wait. You can do that! You just use pony as a base model and Animagine as a refiner!
But hold on! Why would it even bring something new to the table!?
Well, pony was trained on exceptionally well-captioned ~2.6M images of (gpo, ces), while AnimagineXL was trained on poorly tagged ~2.4M anime images. It's not too hard to guess that they don't share a lot of images, and they can cover up each other's flaws, meaning additionally using Animagine is similar to adding another 1.9M to 2.4M anime images on top of the pony's 2.6M dataset of (gpo, ces). Moreover, by using the models this way you're technically ensembling them into one, so it shouldn't be a surprise that a 2*3.5B model outperforms a single one.
At this point you should also understand that this approach is not limited to pony->Animagine and can be used with virtually any existing model out there (ArtiWaifu?).
my bro told me itz just an img2img?
Reading this, you might find yourself asking the question: how does that differ from the usual img2img?
The main difference is that refining reduces the generation time significantly, especially if you can keep both models loaded all the time, which is almost 0 overhead compared to img2img. You don't waste compute or VRAM on extra VAE encodes/decodes and other overhead img2img carries with it either. And another thing, with img2img you can choose the seed to generate the noise, while the refiner operates with the same exact noise produced at the very start of txt2img.
Otherwise img2img should give very similar results.
You may call the artifact between an txt2img and img2img (namely the image) is somehow useful for editing or whatever, but you also should be aware that to achieve similar effect with img2img you have discard a lot of high frequency info by applying the noise to the image, which renders all small edits the same. If the stuff you want to fix is big, modifying the prompt or using the variation seed is probably what you want to do.
wtf bro thats very interesting butt, hau tu use it??
First, download the models. I assume you already have a pony-based one, so just download the latest Animagine:
https://huggingface.co/cagliostrolab/animagine-xl-3.1
https://civitai.com/models/260267/animagine-xl-v31
To take advantage of this approach, you absolutely must understand that you are trying to glue two different, almost unrelated models. You can't prompt it the normal way, you will likely get garbage. You have to make sure they're on the same page. Thankfully this issue is not too hard to get around in A1111/Forge using a special prompting trick, more on that below.
- First, select your main model as autism/pony/whatever.
- Tick the box against the "Refiner" widget and select Animagine model there.
-
Choose the "Switch At" value wisely.
Switch At controls how late in the diffusion process you should stop and switch to Animagine, from 0 to 1, where 0 is only using pony, 1 is only using Animagine. For starters, set it to 0.5. This way you will do half the steps on pony and another half on Animagine.

Actually, by default the webui doesn't allow you to set it to 0, only to 0.01 which means that at least the first step will be done on pony, but oh well.
-
Use the following POSITIVE prompt template:
As you can see, this prompt utilizes the Prompt Editing feature of the webui to pass different prompts to different models. In the first part inside the square brackets, before
:, use tags for pony. In the second part, use tags for Animagine. The number in the end of the square brackets chooses when to switch the prompts. You MUST sync it with the refiner's "Switch At" slider. This is rather complicated, but it works. -
Use the following NEGATIVE prompt template
Don't forget to sync
0.5here as well. - Set up the rest as you usually do.
Here is the comparison on a relatively simple non-cherrypicked pic using by rasusurasu, by eiri \(eirri\), by kedama milk as the style prompt.
| 100% Autism (Switch At = 1) | 50% Autism 50% Animagine (Switch At = 0.5) | 30% Autism 70% Animagine (Switch At = 0.3) | 100% Animagine |
|---|---|---|---|
 |
 |
 |
 |
Another one with (by tianliang duohe fangdongye:1.4), (by daizu \(melon-lemon\):1.1), by bartolomeobari, (by rodriguez \(kamwing\):1.2):
| 100% Autism (Switch At = 1) | 35% Autism 65% Animagine (Switch At = 0.35) | 100% Animagine |
|---|---|---|
 |
 |
 |
 |
The sweetspot for style transfer is around 0.2-0.3, but unfortunately Animagine can't manage the anatomy as well when swapping to it so early, so exercise caution.
automaticGODS
Everything works out-of-the box. If you have the VRAM, enable caching in the settings by setting Maximum number of checkpoints loaded at the same time to 2.

If you have less VRAM, you can can try caching stuff in RAM instead by checking the respective checkbox below the slider.
Use the visual prompting guide:
abandonwarekeks
It worked somewhat fine for me with --always-gpu flag but it won't work properly unless you have 24GB VRAM.
Forge is basically abandoned and buggy version of A1111, and AFAIK on the latest version of Forge, the cache slider in the settings doesn't work, it will always try to reload them from the disk. Built-in kohya hires fix doesn't work with the refiner either, it stops working as soon as the UI switches to using a refiner.
Someone reported that it's memory leaking for them when trying to use refiner, causing the entire PC to hang.
Apparently it also has problems with switching the models in general which is a massive bummer.
I would highly recommend using the updated Automatic1111 instead
i am le vramlet
get a job, fag
It should eat the same amount of VRAM by default on either of the webuis, you will just have to wait for the models to reload from disk. If genning takes magnitudes longer, you fucked something up.
8-12GB is enough to swap to RAM. With 16 you can try loading models in 8bit, and with 24GB+ refining doesn't have any overhead whatsoever (is 100-200 msec an overhead?).
/sdg/ residents
go figure out yourself, you're not a child anymore (or so you say)
some styles to try
Schizo style grids: https://civitai.com/posts/2273977
Styles that apparently were introduced in Animagine 3.1: https://files.catbox.moe/76bnae.txt
the limitations
- Small details sometimes get fucked. For example, pussies. They are less right with Animagine, although they do not look particularly atrocious. Usually fixable by playing with the prompt, but some things just refuse to work properly (upside-down pussy).
- The style may still be not very apparent. In this case, you should try increasing the weights on the artists or start switching to Animagine earlier. You can also try using Ancestral sampler and sample for longer.
- Sometimes you just can't have both the nice style and anatomy. In this case, proceed with running the best anatomy image through img2img multiple times using plain Animagine with denoise around 0.5 and using Ancestral sampler (without the refiner), but this doesn't always work.
tips
- I found that it's more useful to use Ancestral samplers, while setting more steps overall. So, if you usually did 20 steps, do 30, while adjusting refiner's "Switch At" to a lower value. This will make Animagine style somewhat more apparent while still preserving the anatomy.
- CFG 5-6 is a sweet spot IMHO.
- Loras made for pony will still work on Animagine (as refiner) and vice-versa, but they are weaker. Test your loras individually.
-
You can use
ai-generatedtag on Animagine that will control the levels AOMslop in its outputs. I prefer putting it in negatives.- If you see really weird shading after putting
ai-generatedin negative, also try addingby segami daisuke, by yukia \(firstaid0\)in there as well. Also condideroldest.
- If you see really weird shading after putting
- If Animagine struggles to stick to the character it knows well when pony doesn't, all you need to do is to be more precise with the prompt to make it less confusing for Animagine. For example, if you didn't specify the hair color, it's almost guaranteed that Animagine will stick to the wrong color picked by the autism. All you need to do is specify the hair color.