Гайд по LoRA
последнее обновление: 11.05.2025
Чейнджлог:
Обновление от 11.05.2025: Фикс описания таймстепов, edm2.
Обновление от 25.11.2024: Правка инфы про prodigy на более актуальную, со сменой рекомендуемых конфигов в XL секции. Смена ссылок на v-pred модели нуба на актуальные в данный момент времени.
Обновление от 10.11.2024: Переписана вводная, советы по датасету, XL секция, в неё добавлена инфа про новые актуальные на данный момент чекпоинты. Актуализирована инфа насчёт full_bf16/fp16. Мелкие добавления про параметры по типу ip_noise_gamma, debiased_estimation_loss. Изменена формулировка v_pred+ztsnr части, на более простую, отражающую суть. Добавлена информация про очень непопулярный оптимайзер fishmonger, и обновлена про prodigy. Выпилены адднеты, всё, ушло их время и уже давно.
Обновление от 24.06.2024: Фикс сетапа трипл-теггера с нуля. Добавлена информация про masked training и новые фичи распарсивания тегов в датасете. Добавлено немного инфы про adafactor оптимайзер.
Обновление от 16.05.24: Добавлена информация про теггинг анимешных датасетов ансамблем теггеров свежих v3 версий, переписана на более корректную информация про min_snr_gamma, а также добавлена косвенно связанная с этим параметром инфа про новые loss_type, huber_schedule, huber_c параметры, обновлены зависимости для ручной установки в очередной раз. добавлен пример стилевого датасета для поней. Так же мелкое добавление про DoRA.
Обновление от 29.03.24: Добавлена инфа про тренировку XL на примере поней, вкратце расписан простой путь, раскидана новая инфа по параметрам и добавлены новые, в некоторых секциях. Так же обновлены зависимости ручной установки и версия куды.
- Что это
- Использование
- Подготовка датасета
- Тренировка
- Параметры тренировки
- --learning_rate ($learning_rate в скрипте)
- --optimizer_type ($optimizer_t в скрипте)
- --lr_scheduler ($scheduler в скрипте)
- --network_dim ($network_dim в скрипте)
- --network_module ($network_module)
- --resolution ($resolution)
- --noise_offset ($noise_offset)
- Tensorboard
- Пути для файлов тренировки
- --max_token_length ($max_token_length)
- --max_train_epochs ($max_train_epochs)
- Дополнительные аргументы, которые стоит упомянуть
- Решение проблем
Что это
LoRA (Low-rank Adaptation), хоть пейпер и рассказывает про языковые модели, но, по своей сути лора это Peft (Paramteter efficient fine-tuning), способ представления параметров в матрицах более низкого ранга, со следующими особенностями:
- быстрее тренировки полноценной модели;
- намного меньшие требования к видеопамяти при тренировке;
- маленький размер выходного файла, переносимого между определённым количество моделей;
- результаты иногда лучше, чем у традиционного файн-тьюнинга, не математически конечно, но субъективно, в случае картинкомоделей
Данный способ можно применить не только к классическим мелким переносимым сетям, подключаемым к основному SD чекпоинту, но и, например, к controlnet.
Требования для обучения просты - чем новее Nvidia видеокарта стоит в системе и чем больше на ней памяти, тем меньше придётся терпеть, ужимаясь в фичах, минимумом для XL можно считать не ниже архитектуры turing с 8 гигами на борту, для 1.5 требования меньше, подойдут в целом даже паскали.
Использование
На данный момент есть три способа использования сети LoRA:
- Использовать нативную поддержку A1111-WebUI
- Замерджить вместе с SD чекпоинтом
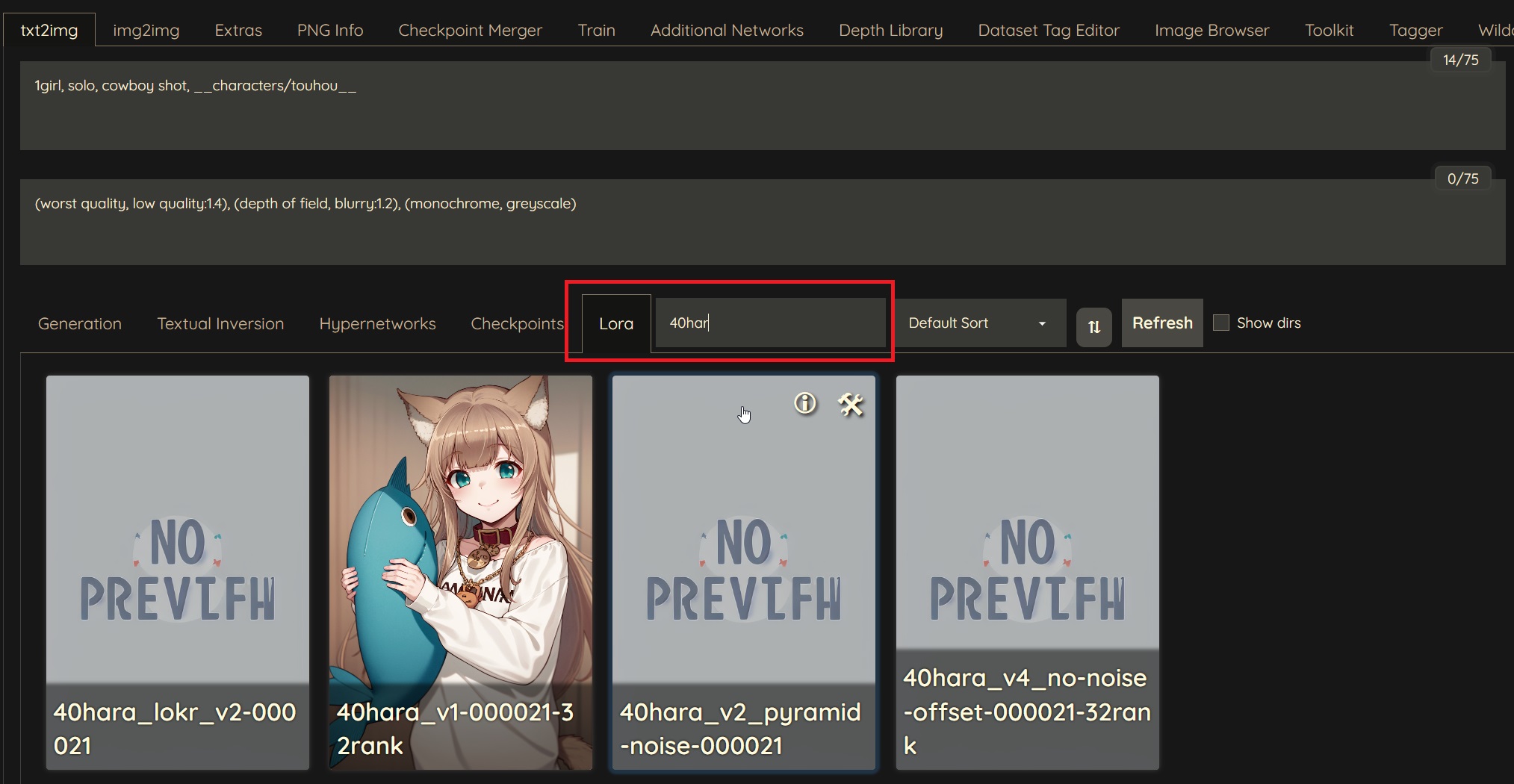
Cпособ 1 – использование в промпте WebUI
По состоянию на 03.10.2023 этот способ является приоритетным для использования, так как поддерживает все дополнительные алгоритмы LyCORIS из коробки.
По умолчанию файлы сетей хранятся в папке stable-diffusion-webui\models\lora\. Туда и нужно скидывать новые скачанные лоры перед использованием.
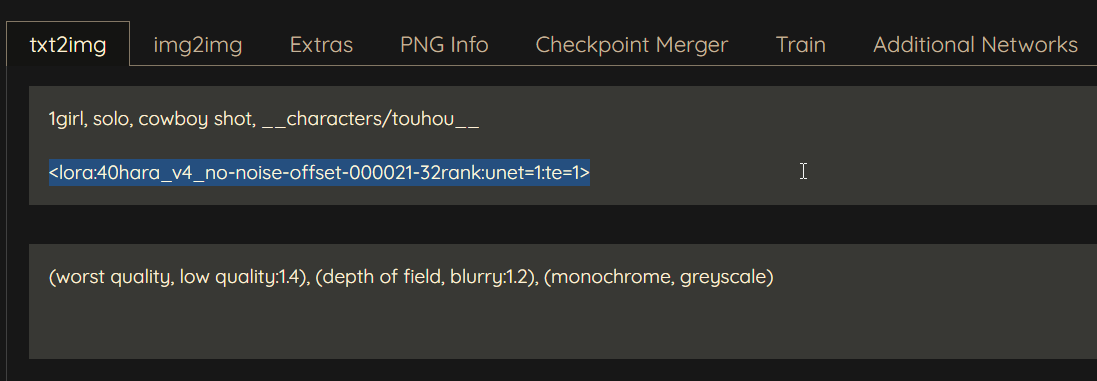
| 1. В меню генераций нажать Lora найти и выбрать интересующую сеть | 2. LoRA появится в промте (отредактируйте значение после : для изменения весов unet и te при необходимости) |
|---|---|
 |
 |
Cпособ 2 – мердж с моделью
Этот способ добавляет лору в модель навсегда, а не просто накладывает дополнительные веса в инференс тайме. Делать так стоит лишь в случае, когда вы собираетесь постоянно использовать такую модель или просто хотите создать какой нибудь новый микс чекпоинта.
Для этого лучше всего будет воспользоваться отдельной тулзой. Ставим по инструкции, и запускаем с помощью gui.bat.
Дальше нужно проследовать по вкладкам, как на скрине ниже и выбрать желаемые чекпоинт, лору/лико и путь с названием для новой модели, после нажать Merge model. Merge ratio это сила лоры с которой она будет примерджена.
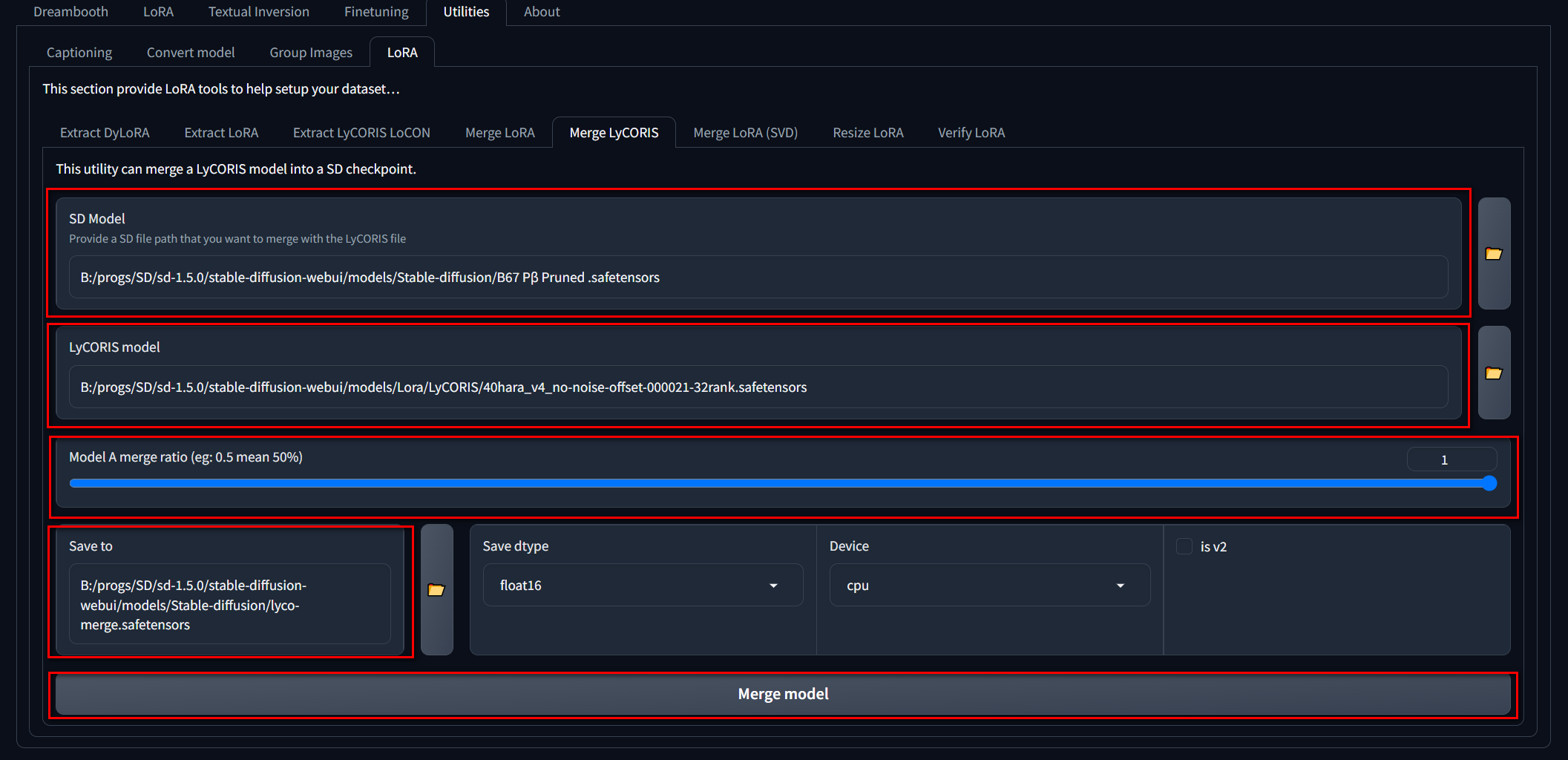
После этого стоит проверить работоспособность мерджа. Сначала сгенерировать картинку с моделью без мерджа и лорой в промпте, а после просто с моделью в которую была примерджена лора, без неё в промпте. Картинки должны быть почти одинаковыми.
Перед тем, как продолжать дальше нужно поставить CUDA-toolkit и Python 3.10.X.
Подготовка датасета
Общие советы
Совет №1 размер и консистентность датасета
Датасет это основа успешной тренировки. То насколько чисто обработаны картинки в нём влияет на полученную лору больше всего. Все ошметки чужих конечностей, непонятные объекты на картинке, подписи художников, ссылки – все, что вы не хотите видеть в генерациях, лучше обрезать или замазать в фотошопе. Разрешение картинок не должно быть ниже, чем то с которым вы будете тренировать. Примерное необходимое количество картинок, под которые не нужно будет крутить дефолтные параметры это:
- 50-100 для персонажа
- 75-200 для стиля
Цифры приблизительны и зависят от каждого конкретного датасета, а так же основываются на опыте автора. Если собрать мало картинок, сеть будет более склонна к перетрену, так и наоборот, если собрать слишком много, на том же лр сеть придётся тренить намного дольше.
Если тренируете персонажа, желательно чтобы датасет состоял только из изображений, где он присутствует, алсо рекомендуется придерживаться разных стилей в артах, если это аниме персонаж. И чтобы во всех описаниях было ключевое слово, описывающее этого персонажа/человека. Например, shiina mayuri, 1girl, short hair, green eyes и т.д. Вызов через shiina mayuri соответственно. Также, если модель уже изначально немного догадывается о вашем персонаже, которого вы будете тренировать по соответствующему тегу, это ещё больше упростит задачу.
Если тренируете авторский стиль, желательно чтобы датасет состоял только из изображений, нарисованных данным автором и не меняющихся в стиле, у некоторых авторов есть тенденция менять его со временем или и вовсе халтурить в работах.
Совет №2 теггинг
Теггинг датасета не менее важен, если правильно подобрать теги, которые уже в себе содержат инфу от предыдущих тренировок, это сильно упростит и ускорит задачу. Если тренируете на основе аниме моделей (NAIv1, IllustriousXL), описание делать строго в стиле Danbooru/Gelbooru тэгов. Например, 1girl, short hair, green eyes, black hair, school uniform..., это как раз пример тех самых тегов, которые уже тренировались в датасете Illustrious.
- Тренируя PonyXLv6 с анимешным стилевым датасетом лучше всего будет протегать датасет примерно в следующей последовательности score_9, source_anime, 1girl, standing, looking at viewer... NLP. Здесь score_9, source_anime показаны просто для примера анимешного датасета, их не обязательно оверрайдить и можно ограничиться вообще лишь выхлопом из вд-теггера, даже без NLP части, она опциональна. Сама модель универсальна и не ограничивается лишь такими тренировками, под NLP имеется ввиду естественный язык описания картинки: girl standing at the beatiful forest and looking at viewer, крайне не рекомендуется для аниме датасетов. При тренировке персонажей лучше не добавлять теги скора и сурса, так как в дальнейшем могут быть проблемы совместимости с другими лорами или стилями, за пределами аниме генераций. Протегивать картинки стоит вообще всегда, вне зависимости от того будет тренироваться энкодер или нет, от этого будет зависеть конечный результат и качество тренировки.
- Illustirious/Noob лучше всего тегать просто обычным вд-теггером/ансамблем, лишь бы были только аниме теги.
- Тренируя модели на основе FLUX архитектуры лучше воспользоваться NLP теггером по типу ToriiGate который может в нсфв теггинг или joycaption который не может в нсфв кэпшионинг.
Совет №3 выбор модели
- Конкретно про выбор модели я с уверенностью могу подсказать лишь про аниме чекпоинты. В случае со стилями, для XL чекпоинтов тренировать либо с люстры, либо с нуба. С нубом спорная ситуация, эпсилон 0.5 это хорошее продолжение тру аниме чекпоинта люстры с отлично реинфорснутой анатомией и нсфв, в версиях выше разработчики разлочили тренировку энкодера и отравили модель, которая теперь имеет конфликтующие теги с обеих бур, danbooru и e621, в угоду новым концептам. Лично сам я бы рекомендовал из эпсилонов - нуба эпсилон 0.5/оригинал люстру для "тру аниме" экспириенса, 1.0 эпсилон если нужны знания про более новых чаров или е621 концепты, но там придётся пердолиться с рескейлом во время инференса, либо же из впредов - 0.65S впред версию мерджа, где нету такой сильной проблемы пережарки.
- Для 1.5, аниме/чаров тренировать стоит лишь с NAIv1 чекпоинта (старый хеш - 925997e9, новый хеш - 89d59c3dde). Для тех, кто забыл где взять этот чекпоинт.
Совет №4 dataset managment
Для ускорения ручного тегирования можно использовать мокрописьки (1, 2, 3).
Либо использовать расширения (1, 2) для A1111-webui.
Для скачивания изображений с различных booru-досок вместе с тегами можно использовать Grabber с такими настройками (скопируйте и вставьте: %character:unsafe,separator=^,^ %, %general:unsafe,separator=^,^ %).
Простым способом для тренировки стиля/аниме персонажа будет либо протегать всё вот этим расширением, либо скачать готовые теги с пикчами данбору/гелбуру с помощью граббера с настройками выше. Достаточно просто, после ввода соответствующих тегов, нажать Get all, после перейти на вкладку Downloads и запустить загрузку, после чего приступить к сортировке картинок, вот кстати полезный скрипт, чтобы почистить тхтшники после удаления пикч, на всякий случай.
Так же стоит присмотреться к более точному способу теггирования ансамблем теггеров, описанному здесь с помощью устаревших v2 буру теггеров, или сделать всё по инструкции с обновлённой версией моделей.
Для поиска дубликатов в датасете можно воспользоваться вот этой софтиной.
Совет №5 training time
Общее рекомендуемое предельное количество шагов для тренировки можно посмотреть тут.
Структура датасета
Датасету необходима определённая структура папок:
 Пример структуры папок
Пример структуры папок
Где n – количество повторений данного концепта; conceptA, conceptB – имена концептов. Имя концепта может быть любое, оно нигде не используется (кроме особого случая, см. Важные замечания), это скорее заметка для вас, что в этой папке находится. Между количеством повторений и именем концепта обязательно наличие нижнего подчеркивания. Внутри каждой папки концепта должны присутствовать изображения вместе с файлами описания в формате *.txt, их имена должны совпадать. Внутри текстовых файлов должно быть, собственно, описание. Папок концептов может быть сколько угодно, но хотя бы одна должна присутствовать. Обрезать изображения необязательно.
Пример датасета для тренировки стиля с 1.5 моделью, и пример стилевого датасета для поней
Важные замечания
Если у файла image.png не будет соответствующего image.txt, скрипт выдаст ему описание в виде имени концепта. Например, если папка концепта называется 6_photo, будет считаться, что у файла image.png описание photo.
Поддерживаемые форматы изображений: *.png, *.jpg, *.jpeg, *.webp, *.bmp.
Повторения нужны чтобы контроллировать количество времени тренируемых концептов относительно всего датастета. В случае с одной папкой достаточно будет просто подогнать количество повторений под рекомендуемые, от 200 до 600 итераций на эпоху. В случае с несколькими лучше удерживать баланс тренируемых частей, выставив повторения соответствующим образом. Например, у вас есть папка 1_nekochan с 76 изображениями внутри и папка 6_maid с 16 изображениями внутри. Суммарно это даст 172 (1 * 76 + 6 * 16) итераций на эпоху из этих папок, и нейронная сеть будет обучаться по времени равномерно нескольким концептам.
Регуляризационные изображения для данного способа тренировки не требуются и лучше обойтись без них.
Теггинг анимешного датасета в буру стиле ансамблем из трёх v3 моделей
Здесь будет показан пример с созданием чистого venv, делать это не обязательно, можно использовать один из существующих, например от kohya_ss, поставив туда недостающие зависимости по типу onnxruntime-gpu.
Как обычно, нужно создать venv и зайти в него:
Далее нужно поставить рекваерменты через pip install -r reqs.txt reqs.txt это файл по ссылке.
Содержимое архива следует распаковать рядом с этим venv'ом, открыть батник tagger-v3-simple.bat и поменять --src_dir на путь к директории с картинками, а затем запустить.
Masked training
Принцип тренировки, где информация добавляемая в нетворк будет браться из определённой области, выделенной на картинке. Преимущественно полезен для точных тренировок персонажей и концептов, для снижения влияния бекграундов и прочего не нужного мусора на картинке на процесс тренировки. Чтобы начать такую тренировку, нужно создать маски к картинкам для датасета, любым доступным способом, например в фотошопе или любом другом графическом редакторе. Сам принцип такой: в зависимости от значения в красном канале пикселя маски придаётся соответствующий вес для влияния информации содержащейся в этом пикселе на тренируемой картинке, чем ниже значение, тем ниже вес. Грубо говоря, черная область маски не оказывает влияния на тренировку, тогда как красная наоброт. Пример датасета для такой тренировки. Значимая часть картинки не обязательно должна быть красной, можно и белую, главное чтобы значимая часть в красном канале имела высокий вес в виде значения 255, что является весом 1.0. Так же для такой тренировки понадобится указать параметр --masked_loss и --dataset_config="somewhere_in_the_filesystem\dataset.toml" пример которого можно так же найти выше, в нём нужно указать conditioning_data_dir как путь на директорию с масками. Для тех кто не хочет заморачиваться с консолькой данный конфиг подойдёт для dev ветки easy-scripts, достаточно лишь сменить пути на нужные.
Из немногочисленных тестов проведённых с таким способом, могу порекомендовать использовать prodigy оптимайзер для такой тренировки.
toml конфиги самого sd-scripts
Все параметры для тренировки с sd-scripts можно засунуть в один удобный конфиг, подробно про это расписано здесь. Имеет определённые баги и я бы не рекомендовал это юзать, во избежании проблем, но не упомянуть про это я не мог, ведь без подобного конфига, например, вообще не запустить маскед трейнинг, благо реализация для этого уже есть в тех же easy-scripts в dev ветке.
Особенна интересна часть про теги датасета. Не обязательно это использовать с конфигом, но описание того как это работает там дано вполне исчерпывающее, например multi-line captions при добавлении enable_wildcard в параметры использующийся для поочерёдного использования тегов из файла к картинке, разделённых ньюлайном, или keep_tokens_separator="|||", который не модифицирует теги, слева и справа от него, 1girl ||| skirt, shirt ||| masterpiece, best quality не затронет теги 1girl, masterpiece, best quality, усовершенствованный keep_tokens.
Тренировка
По состоянию на 10.11.2024 существует несколько GUI-обёрток для sd-scripts, основного репозитория скриптов для тренировки:
1) Easy-scripts. Автоматически поставит все нужные зависимости и настроит окружение, мейн ветка давно не обновлялась, но если перейти на дев будут (почти) все последние фичи.
2) Kohya_ss. Тоже избавит от нужды пердолиться с установкой, но работает как и WebUI, через браузер. В первую очередь получает все последние обновления для тренировки, имеет буквально все параметры скриптов, а так же любые тулзы необходимые для менеджмента лор.
Трейнеры с отдельным от sd-scripts бэком:
1) OneTrainer. Прост в использовании, но довольно скудный выбор параметров.
2) SimpleTuner. Который совсем не симпл. Линукс онли, автор мл пердолик, имеются фичи, недоступные в других обёртках.
Суть
Суть любой тренировки лоры заключается в попадании в свитспот сразу двух составных частей Stable diffusion модели, Unet и TE.
 Правильный подбор параметров как раз поможет как в попадании сразу в обе составляющих, в виде юнета и те, так и в растягивании этого окна свитспота, посредством грамотного замедления тренировки.
Правильный подбор параметров как раз поможет как в попадании сразу в обе составляющих, в виде юнета и те, так и в растягивании этого окна свитспота, посредством грамотного замедления тренировки.
Easy way 1.5
Сначала будет показан простой путь для тренировок, для тех кто не хочет пердолиться со скриптами и прочими проблемами.
- Поставить gui для тренировки.
- Запустить гуй с помощью run.bat в директории установки.
- Далее всё будет зависеть от видеокарты, на которой будет происходить тренировка. Вот примеры конфигов для 8, 12 и 24 гигабайтных видеокарт.
Внимание, в параметрах Training precision и Saving precision конфигов выставлена BF16 точность, если ваша GPU ниже линейки RTX3000, настоятельно советую сменить эти параметры на FP16 во избежании дальнейших проблем.
После их импортирования, в них нужно будет подкорректировать пути к моделям/логам следующим образом:
- Base model - здесь нужно указать чекпоинт с которого будет происходить тренировка, например C:/ai/nai-nsfw.ckpt
- В Saving args > Output folder - нужно указывать на директорию в которую будут сохраняться новоиспечённые лоры, например C:/ai/my-lora-dir.
- В Saving args > Output name - нужно указывать имя будущей лоры, например my-best-waifu-lora.
- В Logging args > Log output directory - следует указывать директорию для логов тренировки, например C:/ai/my-lora-logs.
- В Logging args > Prefix for log folders - стоит указать префикс логов, который будет добавляться в начало названий их директорий, например my-best-waifu-logs-.
- После стоит перейти на вкладку Subset args и нажать на кнопку Add all subfolders from folder и указать на путь к датасету, который представляет из себя папку, в которой содержатся директории вида 2_my-waifu-pics, например C:/sikret-folder/fap-pictures-with-my-waifu. Здесь так же стоит поставить галочки shuffle captions на частях датасета, где это необходимо.
Далее, как все пути расставлены верно, нужно запустить тренировку, нажав на кнопку Start training.
- Как тренировка завершится в папке, которая указана в строке Output Folder, раздела Saving args, появятся эпохи натренированных лор. Скидываем ласт эпоху в директорию stable-diffusion-webui\models\Lora и идём тестить, запустив вебуи.
- Протестировать новые лоры можно разными способами, чем больше тестов вы прогоните, тем лучше будуте знать о плюсах и минусах получившихся нетворков, лучшим тестом будет продолжительное использование получившегося нетворка со своими любимыми промптами. Сначала стоит проверить по промптам из датасета напрямую, потом насколько успешно генерализовалась информация, например если художник не рисует нсфв, но модель может в это дело, то посмотреть насколько хорошо модель поняла как совместить предыдущую информацию с новой. Или например художник не рисующий фоны, написать с ним промпт на какой нибудь высокодетализированный сити бэк. Или пример с чаром, в датасете было мало или вообще не было пикч в определённой позе и стиле, можно попробовать это запромптить. Пережар текстового энкодера будет выражаться в невозможности запромптить что-то кроме того, что было в тегах датасета, пережар юнета всякого рода артефактами, сильным, не плавным, перерисовыванием изображения с относительно низким денойзом 0.4-0.5, в инпеинте, и2и или хайрезе, а также разными нежелательными объектами даже на лоурезных пикчах, по типу дополнительных рук, не в тему летающей где то рядом херни от фона или поломанной анатомии. Недожар же можно будет понять по слабому возпроизведению тренируемого концепта/стиля. Подробнее про примерные хорошие базовые значения параметров, можно посмотреть в разделе параметров тренировки. Пережаренный юнет XL моделей может не проявлять себя так же явно как юнет от 1.5. Разные чекпоинты по разному показывают перегретые части тренировки, для той же пони например вообще в порядке вещей, что бы что то там летало рядом, по крайней мере из коробки.
- Можно сделать ещё одну вещь, снизить ранг модели, здесь стоит поэкспериментировать с параметрами ресайза, но если тренилось в низком ранге 8-16, то делать это уже не стоит.
Сделать это можно так, сначала найдите папку с установленными sd-scripts, далее введите команды в консоль павершелла, открытую в этой папке:
Надёжным рангом для ресайза 1.5 лоры можно считать рейндж 16-32.
Для XL же стоит крутить не ранг, если тренировалось уже в 16 и ниже, аdynamic_param, начиная с0.999.
XL
Основные принципы для XL моделей:
- Они куда лучше воспринимают скармливаемые им картинки, из-за буста разрешения до 1024х1024 пикселей. Всё лишнее на картинках, по типу: ватермарок художников, плохого контраста/гаммы, кривых пальцев/анатомии, текста/спич баблов, фонтана камшотов от несдерживающих себя в этом художников будет усвоено в точности. Так что первое что стоит сделать это очистить датасет, пареллельно поправив контраст/яркость, настолько, насколько это вообще возможно, последнее кстати не нужно делать с v-parametererization чекпоинтами, рейндж у них позволит передать более точно, как светло-яркие, так и темные стили без проблем. Особое внимание стоит уделить именно ватермаркам, они очень плохо привязываются к тегам и рекомендуется их вычистить ещё на этапе сбора картинок. Так же прямо на этом этапе стоит избавиться от дубликатов картинок, используя, например, вот эту мокропиську. Если нужные картинки имеют разрешение ниже необходимых 1024х1024 (или эквивалентных по сторонам) пикселей, запускаем фордж/автоматик, идём в экстрас и апскейлим в помощью этой модели предварительно создав по пути webui/models папку с названием DAT и положив модель туда. Этот апскейлер в основном хорош лишь для аниме стилей/чаров, и имеет приемлемый баланс качества/затраченного времени на каждую картинку.
- Конфиги и датасеты, без специфичных для конкретной модели вещей, между разными epsilon версиями модели на этой архитектуре подойдут друг к другу. Основной рекомендуемый мной конфиг для эпсилон чекпоинтов для easy-scripts, подойдёт для любой epsilon модели, для него нужно применить вот этот PR, подробнее про который можно почитать в оптимайзерах. Проще всего будет просто по пути LoRA_Easy_Training_Scripts\backend\sd_scripts\venv\Lib\site-packages\prodigyopt подмахнуть файл из пр'а, переименовав, ради сохранения, старый, если не хочется пердолиться с гитом. Он должен подойти для всего что имеет на борту 12 гигов свободной гпу памяти. CHANGE в полях значений нужно поменять на соответствующие пути в файловой системе и задать путь к датасету в Subset args вкладке. Если не хочется возиться с пр, то старый пони конфиг должен тоже подойти, я его не оптимизировал со времён пони и рекомендую всё таки заморочиться с пр. Рекомендуемый конфиг для чаров/концептов с датасетом хотя бы в 100 картинок, если картинок меньше, то количество шагов стоит снизить. 8 гиговую боль можно закоупить вот этим конфигом для тренировки стилей. Либо же этим конфигом для тренировки чаров с энкодером. Это серьёзный компромисс, веса основной модели замораживаются в фп8, но хотя бы есть возможность натренить то что необходимо, имея настолько ограниченную карту. V-parameterization версия конфига, для тренировки с любой v-pred версей нуба, например этой.
- В общем про гиперпараметры: Ранги (network_dim) выше 32 избыточны и не рекомендуются для простых тренировок, 16 хватит для 95% датасетов, даже с несколькими концептами внутри. Чаров, как и раньше, лучше тренить с энкодером в 30-50% лра от лра юнета, предварительно запрунив теги по принципу "один на каждую значимую часть атрибутики", а не "skirt, black skirt, pleated skirt" и прочие повторяющие одно и тоже одинаковые теги. Стили же лучше делать юнет онли с чистыми датасетами, но если на картинках присутствуют сложные концепты или много мусора/текста, который лень чистить, то энкодер стоит тоже включить, при условии что датасет хорошо протеган. 2000-3000 шагов должно быть более чем достаточно с батчсайзом равным 2. Gradient checkpointing мастхев, хоть с ним и получаются чуть иные результаты тренировки, без него в 24гб влезет лишь тренировка с батч сайзом 1, с ним даже в 12гб можно будет уместить больший батчсайз, пусть и ценой скорости тренировки, таблицу с ориентиром потребления vram можно найти здесь.
- Есть одна общая закономерность как для пони, так и для люстры в том, что легкий тюн в 2500 шагов, или другими словами, любая годно натрененная лора, на довольно выделяющегося стилем художника с правильной анатомией, отлично умеют стабилизировать эти чекпоинты, фикся определённые проблемы консистенции и артефактов аутпута, но не фиксят мусорную анатомию, нуб с люстрой делает примерно тоже самое, но в масштабах модели при этом вправляя анатомию.
Illustrious/Noob epsilon
Вообщем то не особо то и много можно сказать про тренировку этой модели, в сравнении с пони. Она проходит куда проще в случае анимешного датасета и люстры/нуба до 0.5, включительно, версии, из за прямой аниме направленности модели. Люстра тренилась ещё в мае 2024 и имеет примерно такой же катофф, в стоке имеет очень серьёзный недотрен и тонну артефактов, плохую анатомию и бэки. Первое и второе фиксится обычной лорой, третье 0.5 нубом, с четвертым сложнее и будет зависеть от конкретного используемого стиля. Старые конфиги от поней, без конкретных особенностей пони чекпоинта, будут работать и здесь, эта та же самая архитектура.
Одно важное замечание насчёт тренировок на этих моделях. Не стоит использовать разнообразные способы вмешательства в шум по типу noise_offset, ip_noise_gamma. Если натренировать с люстры лору с такими флагами на более позднем(0.5+) нубе получаются мыльные и смазанные результаты, такого не происходит с multires_noise. В остальном лоры между моделями плюс минус работают как примерно между пони и деривативами.
С нубом спорная ситуация, 0.5 эпсилон это хорошее продолжение тру аниме чекпоинта люстры с отлично реинфорснутой анатомией и нсфв, в версиях выше разработчики разлочили тренировку энкодера и отравили модель, которая теперь имеет конфликтующие теги с обеих бур, danbooru и e621, в угоду новым концептам. 1.0 версию без рескейла CFG в инференс тайме юзать практически невозможно, но эта версия имеет какие-никакие знания е621 тегов и должна быть чуть более свежа в плане знаний о новых персонажах.
Noob-vpred/Rouwei-vpred
V-parameterization, zero terminal signal to noise ratio конвертнутые модели 1, 2, не отличаются с точки зрения тренировки лоры под них ничем, кроме как дополнительным указанием двух флагов --v_parameterization и --zero_terminal_snr. Но с точки зрения экспириенса использования такой модели, разница в насыщенности картинок цветом будет ощущаться сразу.
При тренировке с этой модели нельзя использовать никакое вмешательство в шум, помимо ztsnr. Вмешательство в шедулинг таймстепов имеет свои нюансы, например используя debiased estimation loss нужно использовать и флаг скейла лосса. Готовый конфиг для easy-scripts лежит чуть выше.
Pony
Теггинг конкретно этой модели достаточно специфичен и отличается от предыдущих известных подходов к нему. Если планируется тренировать анимешный датасет, то я рекомендую удалить предыдущие теги, притянутые с буры и пройтись ансамблем теггеров по датасету и позже добавить недостающие теги text, speech bubble в картинки, в которых присутствует соответствующий мусор, но удалить их из датасета не получится по определённым причинам. С теггингом ватермарок дела обстоят посложнее, в определённых случаях они очень не хотят привязываться к тегам, но если прямо совсем не хочется вычищать картинки, лучше их протегать пример так: watermark, если там ещё и имя автора то вдобавок artist name, text. Более качественный результат тренировки стилей можно получить тренируя текстовый энкодер и оверрайдя существующие теги score_9, source_anime, удобно добавить теги в датасет можно с помощью вот этого расширения, но, в последствии и качество лоры привяжется и лоботомирует в какой то степени эти теги, так что тут остаётся только выбирать стул, по этой ссылке лежит пример стилевого датасета для поней. При тренировке персонажей лучше не добавлять теги скора и сурса, так как в дальнейшем могут быть проблемы совместимости с другими лорами или стилями, за пределами аниме генераций. Стоит сразу определиться насчёт тренировки энкодера, в среднем лоры натрененные с ним лучше работают с концептами, которые были внутри датасета, но хуже генерализируются на оставшуюся часть поней, юнет онли же наоборот, лично я рекомендовал бы второе, это тренится куда быстрее и минимальные шансы поломать нежный энкодер поней.
После того, как тренировка завершится, идём и тестим получившуюся лору настолько долго, насколько хватит терпения, в первую очередь по знанию датасета, во вторую по генерализации на оставшуюся часть поней. Небольшой трюк для стилелор, их качество можно оценить взяв в тесты очень редкий и легколомаемый концепт, например такой, если те же самые сиды трудногенерируемого концепта не ломаются и картинки с лорой выглядят так, как и задумывалось стилем, 99% вероятности что стилелора получилась годной, сюда же можно ещё добавить какую нибудь хорошо натрененную лору на персонажа, чтобы оценить насколько хорошо стиль будет работать и с ним, данный тест не является эталоном, но по нему достаточно просто ориентироваться, если лора перформит приемлемо по датасету и за его пределами, им можно пренебречь.
Ручная установка для тренировки с помощью скрипта или же просто коммандной строки
- Клонировать репозиторий в любую папку:
git clone https://github.com/kohya-ss/sd-scripts.git, либо же просто в ручную скачать его отсюда - Открыть PowerShell и поочерёдно выполнить следующие команды, либо же запустить скрипт внутри свежей папки с sd-scripts:
- После последней команды терминал начнёт задавать вопросы, выбрать следующее:
In which compute environment are you running?
– This machine
Which type of machine are you using?
– No distributed training
Do you want to run your training on CPU only (even if a GPU is available)?
– NO
Do you wish to optimize your script with torch dynamo?
– NO
Do you want to use DeepSpeed?
– NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list?
– 0 или all
Do you wish to use FP16 or BF16 (mixed precision)?
– fp16 или bf16
BF16 > FP16
Если железо поддерживает BF16 (rtx 3000 и выше), лучше выбрать его. Почему, можно почитать подробнее в описании параметров.
Если PowerShell сыпет ошибками при нажатии на стрелочки
Выключить NumLock на клавиатуре, выбирать варианты при помощи кнопок 8 и 2 на нампаде. Если нампада нет.
- Скачать скрипт
PowerShell
Данный скрипт предназначен для PowerShell, но это не значит что он доступен только пользователям последних версий Windows. Не все знают, но PowerShell доступен для всех версий Windows начиная с XP, на Linux, а также на macOS.
- Редактирование скрипта
Открыть скрипт любым текстовым редактором и изменить переменные вверху файла под свои нужды. Опираясь на информацию, которую можно прочитать в разделе параметров тренировки. Как минимум стоит указать правильные пути к датасету, моделям и папке с sd-scripts. - Запуск скрипта
Если не открывается по двойному щелчку
В папке со скриптом ПКМ в свободном месте -> "Открыть в Терминале" -> ввести .\название_скрипта.ps1 и нажать Enter.
Параметры тренировки
--learning_rate ($learning_rate в скрипте)
Скорость обучения. Основной рычаг управления обучением, если поставить слишком большое число, сеть будет учиться из под палки и результат будет соответствующе пережарен, если поставить маленькое число, сеть будет учиться слишком лениво и долго, что совсем не подходит для такого быстрого метода обучения как лоры. Этот параметр целиком и полностью зависит от других параметров а так же количества картинок в датасете:
- Для AdamW8bit оптимайзера - хорошим стоковым значением является 1e-4 (0.0001) с network_dim=network_alpha=64-128 для 1.5 чекпоинтов и от 3 до 6.5e-4 для XL, если альфа не сильно ниже размерности, а сама размерность ниже 16.
- Для адаптивных оптимайзеров, таких как DAdaptation, Prodigy значение этого параметра необходимо указывать в диапазоне на несколько порядков выше, 0.5-2.0, но хорошим дефолтом можно считать именно значение 1.0. Данные оптимайзеры by design созданы так, чтобы упразднить этот параметр, с ними он не имеет такой силы, как с классическими и управлять скоростью обучения лучше с помощью параметров самого оптимайзера, либо другими параметрами, о влиянии которых можно прочитать далее. У адаптивных оптимайзеров также нету разделения этого параметра на unet_lr и text_encoder_lr, что немного усложняет задачу не поджечь энкодер в процессе.
Наглядные примеры андерфита (недотрена, недожарки) и оверфита (перетрена, пережарки). Для этих примеров были выключены все улучшалки, safety measures и локон, а так же уменьшен и увеличен лр в 10 раз соответственно.
| 1. Underfit | 2. Overfit |
|---|---|
 |
 |
В первом случае видно, что картинка слабо меняется в стиле по сравнению с дефолтной, без лоры. Во втором наглядная демонстрация взрыва юнета и те при оверфите, где очень много левой херни на картинке, а также повылезали и горничная и кошка, хотя они находятся в другой части датасета и вызываются абсолютно другими тегами, о плавности тренировки тут не идёт даже и речи.
Данный параметр можно разделить на два раздельных лернинг рейта для разных частей сд, используя классические оптимайзеры.
--unet_lr ($unet_lr в скрипте)
Скорость обучения UNet. UNet это такая часть в сд, которая отвечает за пошаговое преобразование шума в картинки, можно грубо себе это представить как графическую составляющую, которая и будет запоминать новую информацию. Именно для этого параметра подходят рекомендации, расписанные в learning_rate.
--text_encoder_lr ($text_encoder_lr в скрипте)
Скорость обучения TE - text encoder. Эта часть сд, которая отвечает за преобразование того, что пишет пользователь в промпте в математические значения, для дальнейшего гайданса юнета во что ему преобразовывать шум. Не такая крупная, и судя по вот этой информации количество тренируемых параметров у неё почти втрое меньше на одинаковом ранге. Поэтому хорошим значением может считаться unet_lr/2-3, то есть 3.3e-5 - 5e-5, если лр юнета равен 1e-4.
Раздельные скорости обучения для unet_lr и этого параметра на адаптивных оптимайзерах невозможны, поэтому в случае с ними значение нужно ставить таким же как и learning_rate.
--lr_warmup_steps ($lr_warmup_ratio в скрипте)
Шаги разогрева планировщика лр. Скрипт настроен для высчитывания этих шагов в процентном соотношении. $lr_warmup_ratio - процент шагов начиная с первого, в течении которых скорость обучения линейно увеличивается от 0 до значения learning_rate. Полезен с низкими значениями 0.05-0.1, помогает плавно начать тренировку с маленького лр и не перенасытить сеть слишком рано.
--optimizer_type ($optimizer_t в скрипте)
Тип оптимайзера, ещё один из важнейших параметров влияющих на то, как придётся подстраивать остальные. Их существует огромное количество, в том числе и кастомных, вот только из хелпы сд-скриптс: AdamW, AdamW8bit, Lion8bit, Lion, SGDNesterov, SGDNesterov8bit, DAdaptation(DAdaptAdamPreprint), DAdaptAdaGrad, DAdaptAdam, DAdaptAdan, DAdaptAdanIP, DAdaptLion, DAdaptSGD, AdaFactor. Разные их версии отличаются разными необходимыми параметрами, а также разным потреблением ресурсов гпу. Здесь же будет написано лишь про несколько из них, самых полезных:
- AdamW8bit. Король, которого сложно переплюнуть, практически все существующие гайды по тренингу лор расписывают именнно его параметры и как подстраивать всё остальное под него. Имеет маленькое потребление VRAM и не 8битную версию, которая ест чуть больше, но не прибавляет особо в качестве. Просто работает и считается дефолтом, остальные будут сравниваться именно с ним. Не нуждается в особых параметрах, но если очень хочется, то вот такие подставляются к нему в derrian-gui
"weight_decay=0.01" "betas=0.9,0.999". Хорошо подходит для стилей. Всё ещё актуален для XL, хотя с лернинг рейтом иногда придётся повозиться и не факт что с первой попытки лора получится идеально чистой. - DAdaptAdam. Адам без нужды регулировать лр. Имеет более низкую скорость итераций тренировки и повышенное потребление VRAM. Нуждается в аргументах,
"decouple=True" "weight_decay=0.01" "betas=0.9,0.99"иначе ничего не будет работать. С помощью weight_decay можно регулировать скорость его обучения, чем выше поставить число, тем она станет ниже. В прошлом он претерпел ряд изменений и самые удачные версии это 3.1 и 1.5, в которой кстати ещё была возможность разделения лров, но я не уверен что она работала корректно. В версии 1.5, кстати он назывался и вызывался в скриптах просто как DAdaptation. У этого оптимайзера есть некоторые проблемы с тренировкой стилей, но в целом он хорош и использовать его можно с таким же успехом, как и обычный адам. Он так же является недетерминированным, что усложняет сравнения тренировок с другими параметрами на нём. Есть мнение что с низким значением network_alpha динамический лр с этим оптимайзером может быть подобран слишком большим. - Prodigy. Прололжение DAdaptAdam, также является адаптивным оптимайзером, имеет параметры
"decouple=True" "weight_decay=0.01" "d_coef=1" "use_bias_correction=True" "safeguard_warmup=True". Всё что актуально для DAdaptAdam, актуально и для него. Больше склонен сжарить энкодеры, нежели его предок.d_coef- важный параметр, множитель напрямую влияющий на адаптивный лернинг рейт.safeguard_warmup- можно использовать вместе с вармапом, не особо полезно, учитывая что и он и DAdaptAdam имеют свой вармап. Для тренировок на XL, особенно юнет онли, с которыми не хочется заморачиваться лучше всего будет выбрать именно этот оптимайзер, но в случае с XL просадка скорости тренировки будет ещё сильнее ощущаться, так что тут опять только остаётся лишь выбирать стул.Совсем хитро будет запустить тренировку с продиджи, подождать пока лр устаканится на определённом значении в тензорборде, снизить его процентов на 15 и запустить с этим лр тренировку уже на адаме со всеми его бонусами в виде скорости и возможности разделить лернинг рейты юнета и энкодера.Данный PR фиксит проблему поджарки энкодеров, использовать его нужно классическим способом, задавая лр энкодеров ниже, например 0.25. Личное мнение - для тренировки всего эпохи 1.5 и XL этот оптимайзер справляется лучше всего, хоть и довольно медленный. - Adafactor. Рекомендуемый самим кохьей оптимайзер для файнтюнов XL моделей. Чемпион по самому малому потреблению памяти с XL чекпоинтами, единственный оптимайзер который позволяет файнтюнить (не делать лору!) XL модели с приемлемой скоростью и относительно крупным батч сайзом (5) имея одну 24 гиговую карту. 1, 2 две ссылки с подробностями, но вкратце сохранить память при файнтюне можно для любого не адаптивного оптимайзера, пусть и не так эффективно как для этого.
"scale_parameter=False" "relative_step=False" "warmup_init=False" --fused_backward_passпараметры, которые необходимы для тренировки с этим оптимайзером, конкретно--fused_backward_passотвечает за всю магию сохранения памяти. - Lion. По заверениям разработчиков, замена AdamW, на деле выдаёт чуть хуже качество, с параметрами, рекомендуемыми самими разработчиками. Что точно известно, так это то что он с другими одинаково равными параметрами требует лр в 10-15 раз ниже адамовского, то есть 1e-5 --- 2e-6. Вообщем оптимайзер для экспериментов. Имеет 8битную версию, но для неё нужны более свежие библиотеки bitsandbytes.
- Fishmonger. Screw it, fisher everything. Не адаптивный оптимайзер на основе адама, про который знают 2.5 калеки, тренирует покруче продиджи, но и дольше примерно в 2 раза + ест больше памяти. Много сказать про него пока что не могу, параметры гридами не сравнивал, со стоком тренирует отлично, конфиг я использовал вот такой.
--optimizer_args ($optimizer_args в скрипте)
Собственно те самые аргументы для оптимайзера: "decouple=True" "weight_decay=0.01" "betas=0.9,0.99"
--min_snr_gamma ($min_snr_gamma)
Прежде немного пояснения про timesteps и outliers. Таймстеп это число показывающее зашумлённость изображения, где 1000 - полный шум, а 0 - полностью расшумлённое изображение. Во время тренировки случайным образом, равномерно распределённо, выбирается число от 0 до 1000 на котором проходит данный конкретный шаг тренировки для вычисления расхождений в предсказании. Когда выбирается таймстеп ниже 100-150, предсказания оказываются хуже, шума на картинке почти не остаётся и нейронке сложнее предсказывать следующий шаг, в отличии от начала или мидла генерации, лосс со стандартной функцией на этих таймстепах выше, что может направить процесс обучения сильно не туда. Сильное и резкое отклонение в процессе обучения, чем и является более провальное предсказание на низких таймстепах, является аутлеером и может привести к провальной тренировке ушедшей не туда.
Этот параметр был создан как раз для того чтобы придать меньше веса таймстепам с почти готовым изображением, на графиках видно влияние этого параметра на таймстепы, рекомендуемое значение в районе 5. Это так же является небольшим дампенером и safety measure для тренировки.
Несколько сурсов с обсуждением: 1, 2
| 1. График дампенинга влияния нижних таймстепов | 2. График, на котором показано на каком таймстепе дампенинг больше не действует, в зависимости от значения min_snr_gamma |
|---|---|
 |
 |
--debiased_estimation_loss
Ещё один способ вмешательства в шедулер таймстепов, отличающийся очень агрессивным поднятием веса последних. При тренировке v_pred чекпоинтов с данным флагом крайне рекомендуется использовать ещё и рескейл лосса. До недавнего времени впринципе был поломан для тренировки с v_pred чекпоинтами, но на последнем dev коммите уже пофикшен.

--edm2
Тренируемый параллельно с основным нетворком мелкий нетворк, config b отсюда, единственная цель которого, динамически определять значимость таймстепов прямо во время тренировки. Самый интересный способ на лету с помощью нейронки контроллировать как тренится другая нейронка, даже сд3/флюкс/прочие_новые_модели_нейм не сравняться со своими статик шифтами с этим. Реализован в пердольном форке easy-scripts'ов. В последних версиях можно натыкать параметров прямо в гуе, но дропну старый конфиг для примера, который работал до появления такого функционала в гуе. Форк довольно нестабилен и от коммита к коммиту может зависеть его работоспособность.
--loss_type
Развивая мысль препятствия влиянию аутлееров на тренировку, были добавлены разные типы предсказаний потерь, соответственно и этот параметр их может принимать huber, pseudo-huber или же smooth l1, и классический l2 mse. Huber - очень хорошо влияет на общую композицию исправляя влияние верхних таймстепов, но плохо влияет на нижние таймстепы, чем вызывает плохую детализацию мелких деталей. Поведение классического l2 уже расписано вот тут, и его как раз можно смягчить тем параметром. Smooth l1 в свою очередь включает в себя преимущества двух подходов и является средним между huber и l2 mse loss'ами, поэтому если уж и рассматривать что то на замену min_snr_gamma то лучше выбирать smooth_l1 для этого параметра, дефолтным значением является l2.
Хорошее обсуждение этого можно почитать вот здесь.
--huber_schedule
Шедулер потерь, актуален для huber и pseudo-huber loss_type'ов. Принимает значения exponential, constant, snr. Дефолтным является snr, его лучше и оставить, то есть контроллировать функцию потерь в зависимости от signal-to-noise-ratio или же таймстепа.
--huber_c
Параметр контроллирующий этап смены шедулинга smooth_l1, разработчики рекомендуют значение 0.1.
--scale_weight_norms ($scale_weight_normals)
Ещё одна safety measure, которую предлагается использовать в связке с network_dropout. Скейлит ключи, которые имеют слишком большие значения для весов в них. В консоли выводится значение подсчётов Average key norm=tensor(0.5194, device='cuda:0') ключей, и количество отскейленных Keys Scaled=0. Может сигнализировать о пережарке юнета, если ключи начинают часто скейлится и счётчик Keys scaled растёт, так же есть мнение что этот параметр придаст лоре большую флексибилити для комбинации с другими в инференс тайме. Что заметил лично я, так это то, что использование этого параметра со значением 0.9-1.0 в одиночку, без дропаута, добавляет ещё больше плавности к тренировке. Лучше не переусердствовать со значением, иначе сеть ничему не научится.
--network_dropout
Выбрасывание рандомных весов из рассчётов в процессе тренировки, что тем самым стимулирует тренируемую сеть создавать новые связи, а не акцентироваться сильно на одних и тех же значениях, является дампенером и повышает послушность лор. Рекомендуемое значение 0.1.
--lr_scheduler ($scheduler в скрипте)
Планировщик кривой лернинг рейта. Дефолтные со спадающим лром не сильно друг от друга отличаются, но и тут есть пара нюансов. Для долгих тренировок стилей лучше всего подходят разнообразные косинусы с рестартами/подогревами. Константный шедулер рекомендуется юзать вместе с адаптивными оптимайзерами, а вот обычный адам его плохо переваривает, ему нужен постоянно спадающий лр.
Дефолтные шедулеры поставляемые с sd-scripts: linear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup, adafactor.
- constant: скорость обучения не изменяется во времени с начала и до конца обучения. Единственный планировщик, который не использует переменную lr_warmup_ratio.
Все остальные планировщики используют переменную lr_warmup_ratio и имеют следующие формулировки:
После периода разогрева, длящегося lr_warmup_ratio% шагов, в течение которого скорость обучения линейно увеличивается между 0 и learning_rate:
- linear: скорость обучения линейно уменьшается от значения learning_rate до 0.
- cosine: скорость обучения уменьшается вслед за значением косинусной функции между learning_rate и 0.
- cosine_with_restarts: скорость обучения уменьшается вслед за значением косинусной функции между learning_rate и 0, с несколькими жёсткими перезапусками.
- polynomial: скорость обучения уменьшается как полиномиальный распад со значения learning_rate до значения 1e-7.
Вот так они выглядят на графике тензорборда.
| 1. Constant | 2. Polynomial 0.75 power | 3. Cosine | 4. Linear | 5. Cosine with 4 restarts |
|---|---|---|---|---|
 |
 |
 |
 |
 |
--lr_scheduler_num_cycles ($lr_r_num_cycles в скрипте)
Количество рестартов шедулера cosine_with_restarts. Пример применения: --lr_scheduler_num_cycles=4 даст три рестарта, самое начало тренировки тоже считается рестартом.
--lr_scheduler_power
Сила спада Polynomial шедулера, чем ближе к 0 значение, тем раньше и сильнее начнётся распад.
--lr_scheduler_type ($lr_scheduler_type)
Возможность добавить кастомный шедулер, прямо через аргумент. Например --lr_scheduler_type=cosine_annealing_warmup.CosineAnnealingWarmupRestarts
--lr_scheduler_args ($lr_scheduler_args)
Аргументы кастомного шедулера. Например --lr_scheduler_args "T_0=549" "gamma_min_lr=0.99915" "decay=1" "down_factor=0.5" "warmup_steps=100" "cycle_warmup=50" "init_lr_ground=True"
Рекомендация по кастомному шедулеру для тренировки стилей
Стили с помощью лор тренируются дольше всего и так получилось, что лучшим шедулером для такого дела является cosine_with_restarts, но у него есть один изъян. Моментальное повышение лр за 1 шаг с 0 до значения указанного в learning_rate. Получалось так, что где-то на протяжении одной эпохи бывает слишком маленький лр (ниже 1е-6) чтобы сеть могла чему то научиться, а после резкое повышение, что сказывавается на плавности тренировки. Для решения этой проблемы я предлагаю использовать кастомный шедулер основанный на шедулере из этого репозитория, объясню как его поставить:
- Сначала нужно поставить оригинальный шедулер внутри venv папки с сд-скриптс командами:
- Пройти по пути sd-scripts\venv\Lib\site-packages\cosine_annealing_warmup и поменять название лежащего там файла с scheduler.py на scheduler.py.bckp.
- Скачать кастомный шедулер в эту папку с названием scheduler.py.
Правильный вызов в скрипте этого шедулера показан в параметрах чуть выше. T_0 стоит высчитывать так: высчитать общее количество шагов, которое будет сделано во время тренировки, например 1600 и поделить его на желаемое количество рестартов. Это число, в данном случае 400 и нужно вписывать в T_0, в этот момент будет происходить рестарт с подогревом. С помощью gamma_min_lr стоит регулировать скорость спада лр, чем ниже число, тем быстрее он будет понижаться.
Matplotlib для визуализации не адаптивных шедулеров
Удобно визуализировать работу этого шедулера можно с помощью ещё одного скрипта с дамми нетворком. Достаточно лишь разобраться с импортами вверху него, установив нужные зависимости и положив его рядом с самим шедулером (не обязательно это делать в venv кохи, можно копировать куда нибудь в другое место).

--network_dim ($network_dim в скрипте)
Размер сети. Параметр определяющий количество тренируемых параметров UNet и TE, чем выше, тем больше параметров будет обновляться на каждом проходе. Является одним из параметров, влияющих на скорость обучения, при низких значениях он её замедляет, но не так значительно как остальные. Так же влияет на размер выходного файла и высчитывается по формуле network_dim x 1,125 при половинной точности (FP16, BF16) для линейных и конволюшен слоёв 1.5 чекпоинтов и network_dim x ~6,96 для линейных слоёв XL. Влияет на потребление VRAM во время тренировки, чем меньше значение, тем оно будет ниже. Значения выше 128 избыточны, достаточным значением будет 64 для 1.5 моделей или 16 для XL.
--network_alpha ($network_alpha в скрипте)
Параметр, изначально введённый, чтобы бороться с андерфлоувами выходных весов, когда веса близкие к нулю округлялись до последнего и записывались в тензор, работает скалирование через формулу network_alpha/network_dim. Для тех, кто может использовать преимущества BF16 точности этот параметр нужен в первую очередь только для замедления тренировки. Является вторым по силе замедлителем тренировки и плохо влияет на обучение стилей. В случае с FP16 не полностью убирает нулевые значения, а лишь снижает их количество, чем больше соотношение, тем меньше будет нулевых тензоров.
При понижении этого параметра требуется компенсировать скорость обучения повышением лернинг рейта, в случае с не адаптивными оптимайзерами, примерное рекомендуемое значение для значений альфа=1, рамзерность сети=64 - это повышение лр юнета в 10 раз, до 1e-3.
Хорошие значения:
- От 1/4 до 1/1 от размерности сети - для тренировки стилей.
- От 1/128 до 1/16 для тренировки простых персонажей.
С тренировками лор на SDXL этот параметр можно понижать ниже единицы, например для 8 размерности сети соотношение 1/128 для чаров станет 0.0625 результатом для этого параметра.
--mixed_precision ($mixed_precision) и --save_precision ($save_precision)
Выбор этого параметра зависит от имеющейся гпу для тренировки. Если есть RTX3000 и выше, оба значения лучше ставить в BF16. FP16 подойдёт для владельцев других карт, но этот формат имеет слишком мало бит на экспоненту и из-за этого в итоговой лоре может получиться очень много нулевых тензоров. Кстати про это, проверить тензоры модели можно при помощи одного из скриптов в наборе sd-scripts, а именно networks\check_lora_weights.py. Как обычно через venv из папки networks, предварительно положив рядом интересующий нетворк:
Открываем этот out.txt, ну например с помощью notepad++ и ищем 0.0\r\n поставив чекбокс search mode в extended нажав на count.

У нормально натрененной лоры, на 2 клип скипе должно быть всего навсего 6 найденных значений, если больше, значит были ошибки пресижиона, их кстати можно пофиксить, заресайзив модель, как показано в 6 пункте easy way, по всей видимости при ресайзе первыми отбрасываются именно нулевые значения.
--fp8_base
Опция замораживающая веса основной модели в точности fp8_e4m3 на время тренировки, чем существенно снижает потребление vram. Полезна лишь в одном исключительном случае, когда нужно натренировать XL лору, но имеется лишь 8ГБ vram или меньше. Не рекомендуется использовать этот параметр в каких либо других случаях, так как он зануляет некоторую часть значений ещё на этапе замораживания весов.
--full_bf16/--full_fp16
Опция для серьёзного снижения потребления vram, путём снижения точности до 2 байт всех значимых для тренировки параметров - Parameter storage, Gradient storage, State 1 (momentum), State 2 (variance). Это один из способов тренировки полноценного XL чекпоинта с нормальным оптимайзером, а не специфическим по типу adafactor'а. Разработчики рекомендуют её использовать на свой страх и риск, так как она была слабо протестирована и вызывает баги по типу stale gradients. Лучшим решением будет использовать такое снижение точности вместе с оптимизированными оптимайзерами для этого дела по типу optimi с kahan summation или torchastic с его stochastic rounding
В параметре --mixed_precision и --save_precision следует ставить так же выбираемую тут точность при использовании одного из этих флагов.
--network_module ($network_module)
Определяет основную реализацию алгоритмов скриптов для тренировки, которых всего две, от кохи и кохака. Расписывать про преимущества реализаций, основываясь на опыте, я не смогу, так как не тестировал их face to face, ну и со временем они меняются, фиксятся или добавляются баги, появляются новые алгоритмы и тд. Подробнее про правильный вызов с параметрами можно почитать вот тут, Ctrl+F "network_module" на странице.
Имеет несколько принимаемых параметров, но выбирать нужно один:
- networks.lora - обычная реализация от кохи, принимающая на вход аргументы без указания алгоритма, но можно указать conv слои, о чём будет рассказано чуть позже.
- networks.dylora - реализация DyLoRA от кохи, из моих тестов, эта реализация тренится медленнее реализации кохака. Также никто не мешает накинуть сюда конволюшена.
- locon.locon_kohya - старая реализация локона онли, до того как этот проект перерос в ликорис, которая лежит здесь, for legacy reasons.
- lycoris.kohya - реализация дополнительных алгоритмов, в том числе и дилоры от кохака, принимает другие параметры.
--network_args
Аргументы для network_module. Для каждой из реализаций нужно передавать свои параметры:
- networks.lora, locon.locon_kohya, networks.dylora - принимают на вход
"conv_dim=32" "conv_alpha=32" - lycoris.kohya - принимает на вход такие же параметры с дополнительным указанием тренируемого алгоритма
"conv_dim=32" "conv_alpha=32" "algo=locon". Возможные алгоритмы:full, lora, locon, loha, dylora, lokr, ia3, diag-oft, подробнее про выбираемый алгоритм можно почитать тут или же пейпер, весь список доступных алгоритмов и их параметров. Выбор алгоритма будет влиять на всю последующую тренировку и её параметры, алгоритмы, помимоfullявляются лоуранговыми и большинство из них требуют подбора правильных параметров, сам жеfullсхож с принципом тренировки dreambooth, без декомпозиции матриц в низкий ранг. Так же может принимать параметр тренировки слоёв нормализации"train_norm=True", тренируемый пресет частей нетворка с возможными значениями:full, full-lin, attn-mlp, attn-only, unet-only, unet-transformer-only, unet-convblock-only, можно тренировать даже вплоть до полноценного чекпоинта, выбравfull, но в низком ранге. А так же дополнительные параметры, по типу"use_tucker=True"для ускорения тренировки conv слоёв посредством потери точности или специфичные для определённых алгоритмов параметры, как например для LoKR:"factor=4", или для Constrained OFT:"constrain=1e-4".
dora_wd=True или же просто DoRA
DoRA, новый тип декомпозиции весов во время тренировки, более свойственный тому что происходит при файн-тюне. Переоценённый тип тренировки реализованный в данный момент только в либах от кохака, тренируется примерно в два раза медленнее при мизерных улучшениях в качестве, в том числе и из за сломанности lycoris_lora в данный момент в плане перформанса. Если не жалко потерпеть и пожечь видеокарту, то включается он добавлением dora_wd=True в аргументы нетворка. Включить его можно лишь с LoRA(в том числе и с конволюшенами), LoHa, и LoKr алгоритмами. Не совместим с bypass_mode и network_dropout. LR ставить с тренировкой доры лучше где то в ~3 раза ниже от обычного.
bypass_mode=True
Добавив этот аргумент, можно вернуть старую скорость тренировки с локоном, на версиях lycoris_lora с ~3.0.0, используя либы ликорис проекта.
module_dropout и rank_dropout
Дампенеры тренировки, два уникально реализованных дропаута в ликорис проекте. На практике вместе с этими параметрами лоры получаются более послушными, рекомендуемое значение, как и для обычного дропаута 0.1. Эти типы дропаута, кстати, работают с алгоритмом dora.
Lycoris
Проект одного неравнодушного анимешника для имплементации новых алгоритмов тренировки в сд-скриптс. Из этого проекта я могу выделить лишь один достойный внимания алгоритм.
LoCon
В дополнение к Attention слоям тренируемым классической Linear LoRA, этот алгоритм тренирует Convolution слои блоков ResNet UNet'а.
- conv_dim - тоже самое, что и network_dim, только для этих слоёв. Размер этих слоёв складывается с размером network_dim в выходном файле. Хорошим значением будет network_dim/2-4, например при network_dim=64 это будет 32, для XL это значение может даже превышать размер линейных слоёв, приблизительно хорошим значением для XL с network_dim ниже 16 можно считать network_dim x 2.
- conv_alpha - тоже самое, что и network_alpha, только для этих слоёв.
Эти слои можно накидывать в дополнение к любому другому алгоритму, или к обычной лоре. Подключение этих доп. слоёв очень благотворно влияет на тренировку стилей, чего нельзя сказать о персонажах, особенно с датасетом в одном стиле. Является ещё одним сильным бустером качества и замедлителем тренировки. Больше тренируемых компонентов вызывает снижение скорости тренировки, и точно также замедляет скорость генерации в инференс тайме при использовании такой лоры. Требует увеличения длительности тренировки, очень помогает избежать пережара, даже с неадекватными лр можно получить что-то приемлемое.
--resolution ($resolution)
Разрешение тренировки. Самый главный повышатель качества тренировки. Каждые +64 пикселя дают огромный прирост мелких деталей и переносимость стиля. Повышать следует в первую очередь, учитывая свои возможности врам, потому что этот параметр по совместительству самый сильный замедлитель тренировки. Во-первых, большее разрешение снижает скорость итераций тренировки, во-вторых намного более слабое проявление результатов тренировки на одинаковых шагах. Примерные цифры при повышении с 512 до 768 это х2 шагов минимум, в третьих из-за большего потребления врам, позволяет использовать куда более меньший батч сайз, что в свою очередь ещё больше замедлит дело.
Рекомендуемые значения 768 для тренировок 1.5 чекпоинтов и 1024 для XL, разрешение для XL я крайне не рекомендую понижать, деградация качества будет даже куда заметнее, чем тренить с fp8 весами. Для XL это так же не является дампенером, так как базовый чекпоинт уже был натренирован в таком разрешении.
--train_batch_size ($train_batch_size)
Количество картинок из которых одновременно будет преобразовываться среднематематическое для обновления градиента и весов. Каждый +1 существенно увеличивает потребление vram. У карт с низким врам значения выше 1-2 недосягаемы, поэтому каждая картинка датасета будет влиять на результат сильнее, чем сразу несколько семплов, как в случае с 24гб картами. Есть некоторая математика, связанная с повышением лр для компенсации, а именно, умножать значение лр на среднее между sqrt(batch_size) и batch_size/1.5, sqrt(5)~=2,23, 5/1.5=3.33, тоесть умножить стоит на ~2.75, в сравнении с батчем в 1, тоесть 1е-4 превращается в 2.75е-4, но данная математика не совсем точна, очень экспериментальна, и не всегда применима, по крайней мере в случае с лорой и теми мелкими батч сайзами/короткими сроками с которыми они тренятся. Но вот что действительно не стоит делать, так это ставить его большим, если датасет тоже является недостаточно большим и разнообразным, например бс5 и 15-50 картинок будет не лучшим выбором, а бс5 и 500 картинок уже вполне неплохо, но это скорее отдельная тема про файнтюн, с лорами на одну конкретную вещь батча 1-2 более чем достаточно.
С XL хватит и батча в 2, большие батчи будут тренироваться дольше и не факт, что на сопоставимом временном промежутке результат будет лучше или хотя бы таким же, как с низким батч сайзом. Так же тут ещё более остро стоит вопрос VRAM, если всё таки хочется батча побольше, но память не позволяет, следует комбинировать этот параметр с параметром имитатором, про который написано ниже.
--gradient_accumulation_steps ($gradient_accumulation_steps)
Имитатор батч сайза для тех, у кого недостаточно VRAM для полноценного батч сайза. Объединяется с batch size подобным образом bs x ga. Общая формула для обновлений весов тем самым превращается в (количество пикч х повторы х эпохи) / bs x ga.
--gradient_checkpointing ($gradient_checkpointing)
Параметр для снижения потребляемой VRAM, посредством платы за это существенным замедлением тренировки. Незаменимый параметр для тренировок XL моделей, таблицу примерного потребления памяти можно найти здесь. Вкратце: без этого параметра максимум на что можно рассчитывать это батч 1 при 24ГБ доступной vram при тренировке лоры на XL модель, с ним в 12ГБ влезет уже намного больший батч сайз.
--noise_offset ($noise_offset)
Ужасная заплатка, с помощью которой можно решить проблему дистрибуции шума, для генерации очень тёмных или очень светлых изображений за приемлемое количество шагов семплера. Ужасная она потому что при комбинации с ещё одной моделью/лорой натрененной таким способом картинка сгорит полностью, использовать эту одноразовую заплатку я крайне не рекомендую. Слева можно наблюдать пример такого сожжения. Если данная перспектива не останавливает, хорошее значение в районе 0.05-0.1.
--multires_noise_iterations и --multires_noise_discount
Ещё одна заплатка, призванная решить ту же проблему. Из того что я успел потестить, эта версия не имеет таких проблем с прожаркой. Значения multires_noise_discount ниже 0.3 практически не будут заметны, можно ставить примерно multires_noise_discount=0.4 а multires_noise_iterations=8-10.
--ip_noise_gamma
Способ имитировать не идеальность инференс тайма добавляя излишний шум в тренировочные изображения во время тренировки. Тренировка с этим флагом, может в конце концов привести к артефактам или шуму, выученному моделью, я не рекомендую это использовать, но примерный рейндж нормальных значений это 0.05-0.1.
--v_parameterization и --zero_terminal_snr
Вкратце про суть данного сабжа - epsilon чекпоинты имеют баг связанный с тем, что во время тренировки они обучились таким способом, что на нулевом таймстепе всё ещё оставалась часть сигнала с изображением, но при инференсе модели даётся в отличии от этого полный шум, который она должна будет предсказать. Это привело к тому, что модель привязалась к предсказанию средней яркости изображения и всегда старается это воспроизвести, что в итоге в инференсе привело к невозможности получить полностью черное/белое изображение или скудной палитре/неуместным вставкам рандомных вещей в картинку лишь для соблюдения этого баланса. Zero terminal signal to noise ratio является самой продвинутой заплаткой этого бага, но требует полной перетренировки модели, в оригинальном пейпере так же используется V prediction тип тренировки, так как заявляется, что epsilon способ не может выучить ничего значимого на нулевом энфорснутом степе. Отличия между v и epsilon следующие, epsilon пытается собрать картинку основываясь лишь на шуме, в то время как v prediction, использует так называемую величину "v" - комбинацию из шума и сигнала в зависимости от таймстепа, эффективно усваивая информацию с полного шума, и полностью расшумлённой картинки.
Лорой такое не натренить, нужна полноценная конверсия с достаточно долгой тренировкой на большом датасете, чтобы корректно это сделать. Но тренировка лор с таких чекпоинтов ничем, кроме этих двух флагов, не отличается от тренировки с эпсилон чекпоинта.
--scale_v_pred_loss_like_noise_pred
Позволяет скалировать loss во время тренировки с v_pred в привычные значения, при серьёзном вмешательстве в шедулинг, в данный момент актуально лишь при использовании с debiased estimation loss с v_pred тренировкой.
--v_pred_like_loss
Судя по документации, добавляет v-preditction loss в размере от 0 до 100% (0.0-1.0 в передаваемом значении) для тренировок на обычных, не v_pred чекпоинтах.
Tensorboard
В теории, с правильно подобранными параметрами, график Loss в тензорборде должен иметь постоянный нисходящий тренд на протяжении всей тренировки. Это действительно так, но не в случае таких быстрых тренировок. Проблема в том, что в худшем случае на графиках будет видно лишь полный провал тренировки, а в лучшем, с правильно подобранными параметрами, лишь небольшое снижение значений. Вот три скриншота с графиками:
| 1. Normal train | 2. Boom shakalaka | 3. Overfit and underfit |
|---|---|---|
 |
 |
 |
На первом абсолютно нормальная лора с хорошо получившейся стилизацией, по учебнику стоило бы взять 18 эпоху, ведь там самое низкое значение потерь, но если взглянуть на общую картину, ни одна эпоха не превышает первую по значению, и можно спокойно выбрать любую. На втором намеренно выставленный х15 лр для демонстрации что действтительно покажет тензорборд, такого надо избегать, тренд в идеале должен быть или нисходящим, или хотя бы топчущимся на месте. На третьем скриншоте те два нетворка из гридов про оверфит и андерфит повыше. Исходя из этого, я бы не советовал сильно всматриваться в эти графики, по крайней мере во время быстрых тренировок лор.
Чтобы запустить тензорборд, вне зависимости от установки, найдите папку с сд-скриптс, откройте там повершелл и введите команды:
А дальше через браузер стоит проследовать по этому адресу.
--logging_dir ($logging_dir)
Собственно папка в которую во время тренировки будут записываться логи для тензорборда.
--log_prefix ($log_prefix)
Префикс для логов. Полезно, если тренить много сеток. Можно задавать произвольно, например как в скрипте: $log_prefix = "$output_name" + "_"
Пути для файлов тренировки
--pretrained_model_name_or_path ($ckpt)
Путь к чекпоинту с которого будет происходить тренировка.
--output_dir ($output_dir)
Путь по которому будут сохраняться натрененные лоры.
--output_name ($output_name)
Имя сохранения файлов лор.
--train_data_dir ($image_dir)
Путь к датастеу.
--vae ($vae_path)
Путь к вае. Есть разные мнения использовать ли отдельное, не встроенное в модель вае во время тренировки или нет, я лично придерживаюсь того, что если и использовать то только вот это для тренировки с NAI 1.5 чекпоинтом, из моих тестов оно давало более лучшую детализацию, нежели то что по дефолту находится внутри чекпоинта. Для поней я не советую указывать отдельное.
$sd_scripts_dir (только в скрипте)
Путь до установленных sd-scripts.
--max_token_length ($max_token_length)
Максимальная длина для токенов в описаниях к пикчам. Достаточно просто сразу поставить 225 и не париться об этом параметре больше никогда.
--shuffle_caption ($shuffle_caption)
Перемешивание описаний к пикчам каждую эпоху, полезная штука, лучше тоже включать.
--keep_tokens ($keep_tokens)
Сохранять количество, указанное в этом параметре, тегов от перемешиваний. Это аргумент полезен лишь в случае, если вы хотите сохранить имя персонажа/название концепта и оно стоит на первом месте во всех описаниях к картинкам. Например, при тренировке персонажа, все картинки состоят из него и первым тегом идёт shiina mayuri. При тренировке стилей не имеет особого эффекта и лучше ставить 0, не выделяя отдельного тега и не сохраняя его.
--clip_skip ($clip_skip)
Собственно сам клип скип, работает по тому же принципу, как с простой генерацией, для аниме тренировок ставить значение 2, для реализма 1. Для XL моделей не имеет смысла менять этот параметр, будь то тренировка или инференс.
--seed ($seed)
Примерная аналогия с сидом, как и во время генераций, тоже нужно с чего то начать. Никак не влияет на тренировку, можно генерить автоматически каждый раз рандомный, или выбрать какой нибудь lucky number на удачу.
--max_train_epochs ($max_train_epochs)
Количество эпох (повторений всего датасета) в течении которых будет трениться сеть.
--max_train_steps ($max_train_steps)
Количество шагов в течении которых будет трениться сеть. Выставлять нужно либо это, либо эпохи. Эпохи, тем не менее, всё равно будут сохраняться, после каждого полного прохода по датасету. XL чекпоинтам, по типу illustrious или pony, особенно первому, тренировка поддаётся куда проще и количество шагов для них можно ставить поменьше.
Рекомендации по предельному количеству итераций по картинкам до деления этого числа на batch size, с учетом всех включённых улучшателей тренировки (768 res, locon) при тренировке с nai 1.5 чекпоинта:
- От 8000 до 12000 для стилей. От 400 до 600 итераций на эпоху.
- От 2000 до 7000 для персонажей, в зависимости от сложности чара, грамотного подбора тегов и осведомленности модели о нём. От 300 до 500 итераций на эпоху.
Рекомендации по предельному количеству итераций по картинкам до деления этого числа на batch size, при тренировке XL чекпоинта (illustrious, pony):
- От 2500 до 6000 шагов для стилей в низких рангах.
- От 1000 до 4000 шагов для чаров в низких рангах.
--save_every_n_epochs ($save_every_n_epochs)
Как часто сохранять эпохи. Лучше поставить 1, чтобы сохранять каждую.
--save_last_n_epochs ($save_last_n_epochs)
Количество последних эпох, которые будут сохраняться. Чтобы вдруг ничего не удалилось лучше ставить значение больше, чем будет всего натренированных эпох.
Дополнительные аргументы, которые стоит упомянуть
--cache_latents и --cache_latents_to_disk
Могут помочь сохранить ещё немножечко врам, особенно вначале тренировки. Но если кэшировать на диск, могут возникнуть разного рода конфликты в дальнейшем, поэтому если видите какие то странные ошибки тренировки, первым делом лучше будет вычистить эти .npz файлы из датасета.
--xformers
Ускоряет и сейвит врам также эффективно как и при генерации, стоит включать всегда.
--sdpa
Как и xformers, способ эффективного сейва врам/увеличения скорости тренировки. Актуально в случаях, когда xformers нету/или они не собираются с конкретно необходимой версией торча. Использовать можно лишь что то одно.
--network_train_unet_only
Определяет тренировку только UNet части модуля, полезно для тренировки одиночных стилей, снижает требования vram и ускоряет тренировку, но хуже будет разделять концепты датасета между собой, если в базовой модели уже нету или не достаточно знаний о тренируемых вещах. Не рекомендуется включать этот параметр, если датасет собран для персонажа/концепта или состоит из нескольких разделяемых между собой концептов.
--cache_text_encoder_outputs и --cache_text_encoder_outputs_to_disk
Кэширует описания к картинкам, чем сокращает использование vram. Не может быть использована одновременно с --shuffle_caption или дропаутом связанным с описаниями.
--enable_bucket, --min_bucket_reso, --max_bucket_reso
Автоматический кроп под выбранное разрешение тренировки картинок и рассовывание их в "бакеты". Горизонтальные пойдут в 896х640 и схожие при выборе разрешения тренировки 768, вертикальные наоборот в 640х896 и схожие. Лучше ставить просто большой диапазон по типу --min_bucket_reso=256 --max_bucket_reso=2048. Если в датасете будут преобладать, например вертикальные изображения, это может сказаться на итоговом качестве модели при генераций горизонтальных изображений.
--persistent_data_loader_workers
Выключает назойливые паузы меджу эпохами, стоит включать всегда.
--max_data_loader_n_workers
Я так и не встретил случая, где было необходимо значение больше двух, для ускорения работы. А вот повышение этого значения начинает отъедать львиную долю системной памяти (RAM). Не рекомендуется ставить значение больше 2.
--masked_loss
Расписано тут.
--dataset_config
Расписано тут.
Решение проблем
Данная часть гайда можно сказать совсем не обновляется в основном из за отсутствия какого либо фидбека, поэтому траблшутинг отсюда был актуален лишь на начало 2023 года.
Q: Ошибки, связанные с accelerate и default_config.yaml во время запуска install.bat скрипта.
 A: Поставить vc_redist и запустить
A: Поставить vc_redist и запустить install.bat ещё раз.
Q: Ошибка связанная с zipfile во время запуска install.bat скрипта и ответа y на вопрос Do you want to install the optional cudnn patch for faster training on high end 30X0 and 40X0 cards?.
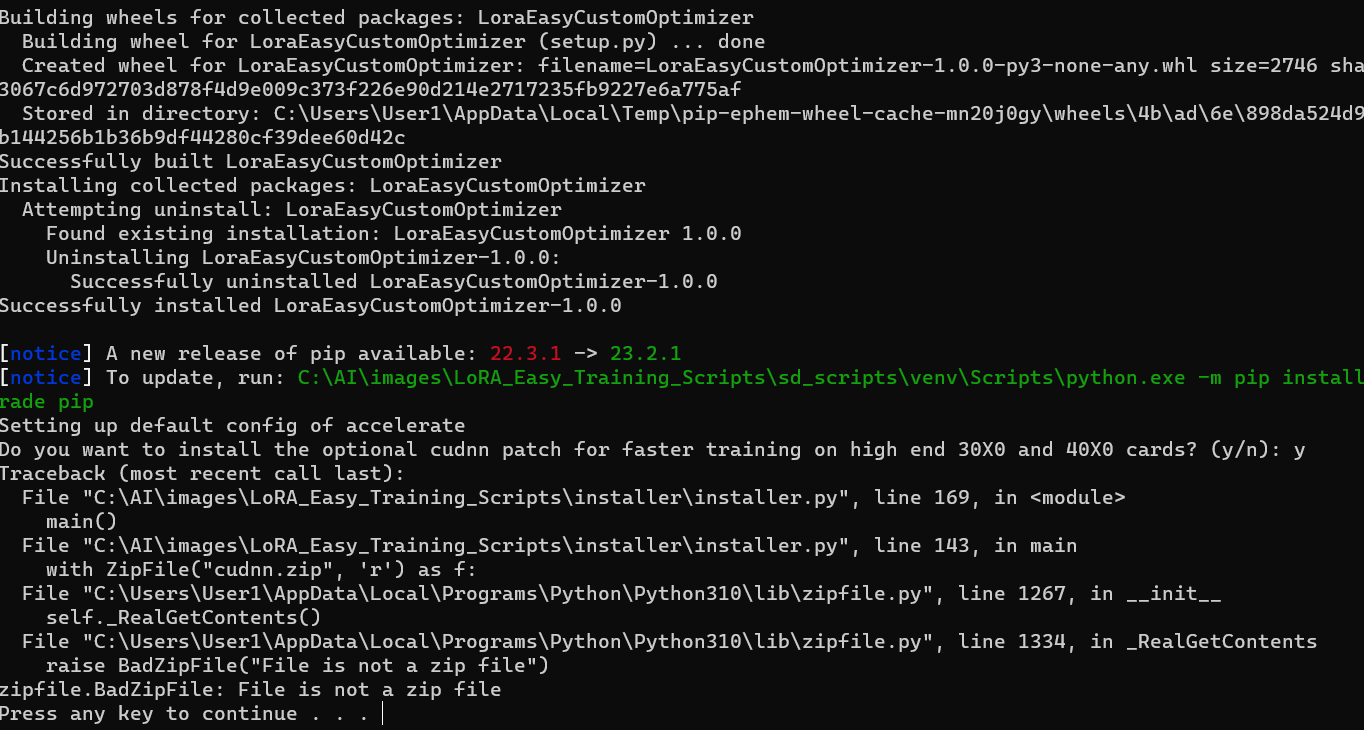 A: Это связано с недосягаемостью хоста с cudnn фиксом с вашего айпи. Решением будет рероутнуть траффик любым способом, например включить прокси/впн и запустить
A: Это связано с недосягаемостью хоста с cudnn фиксом с вашего айпи. Решением будет рероутнуть траффик любым способом, например включить прокси/впн и запустить install.bat ещё раз.
Q: Какие-то проблемы с CUDA.
A: Вероятно не установлен CUDA Toolkit.
Q: У меня карточка 10-й серии и у меня вываливает ошибку при запуске тренировки. Что делать?
A: Скачать альтернативные библиотеки cuda, файл libbitsandbytes_cudaall.dll переименовать в libbitsandbytes_cuda116.dll, поместить по пути sd-scripts\venv\Lib\site-packages\bitsandbytes\ с заменой.
Q: У меня Windows 7 и PowerShell крашится.
A: Установите PowerShell 6.
Q: Сыпятся красные ошибки в консоли при выполнении скрипта!
A: Обновите PowerShell.
Q: Установил всё по гайду, но все равно не находит модули! Мне что, каждую зависимость устанавливать вручную?
A: Нет, процесс подготовки был отредактирован, а конкретно убран флаг --system-site-packages. Этот флаг отвечал за учёт системных библиотек, установленных по стандартному системному пути, и это нередко приводило к конфликтам (в т.ч. у автора). Удалите папку venv из \sd-scripts и пройдитесь по командам заново.